Каталог
Sideband Stack OptimizerУ самого первого Pentium M Intel ввела механизм, который она назвала "dedicated stack manager" – специальный диспетчер стека. В соответствии со своим названием, он предназначен для работы со всеми стековыми операциями x86 стека (запись в стек, извлечение из стека, запрос, возврат). Задача диспетчера стека в том, чтобы хранить в коде те операции стека, которые часто используются для вызова функций, отделяя их от остального потока x86 команд, посылаемых в CPU. Специализированный диспетчер стека будет заниматься декодированием и "выполнять" эти команды, чтобы они не забивали декодеры процессора и исполнительные блоки в конвейере. Intel, по существу, "расширила" ядро, выгрузив некоторые операции, чтобы дистанцировать аппаратные цепи. В Barcelona AMD вводит похожую технологию, которую они назвали Sideband Stack Optimizer. Команды стека больше не идут через 3-путный декодер и стековые операции больше не прогоняются через исполнительные блоки, что эффективно расширяет Barcelona при минимальном удорожании. Sideband Stack Optimizer, как и интеловский dedicated stack manager, имеет собственный сумматор, который обрабатывает все операции стека. Это небольшое дополнение может помочь увеличить общую производительность процессора и одно из тех, которое должно пойти AMD на пользу. Более быстрая загрузкаСравнивая производительность Athlon 64 и Core 2, легко понять, почему у Intel большое преимущество в производительности в приложениях, широко использующих SSE. А как насчет приложений, таких как игры и бизнес-приложения, которые должны выигрывать от интегрированного на кристалле контроллера памяти AMD? Или для того, чтобы обойти Athlon по быстродействию, Core 2 достаточно лишь большего L2 кэша и агрессивной предвыборки? Одним из главных преимуществ микроархитектуры Core является возможность разрешать командам загрузки обходить предыдущие команды загрузки и выгрузки. В среднем около 1/3 всех команд программы заканчивается их загрузкой, поэтому, если вы можете увеличить скорость загрузки, вы, как правило, можете очень сильно увеличить скорость работы приложения. Чтобы не ждать доступа к памяти, отнимающего много рабочих тактов, в микроархитектуре Core можно изменить последовательность загрузок, если вы уверены, что команды, зависящие от этих загрузок, получат нужные им данные. Core позволяет также сдвинуть загрузки и установить из перед выгрузками, что раньше было невозможно, потому что более ранняя выгрузка могла аннулировать только что загруженные данные. В Intel полагают, что вероятность того, что выгрузка произойдет перед загрузкой, очень маленькая, порядка 1 - 2%, поэтому с достаточно точным предсказателем Вы можете точно предположить, когда это может произойти. Логика прогнозирования интеловских процессоров Core 2 может предсказывать, что у выгрузки и загрузки может быть один и тот же адрес памяти. В случае такого прогноза, меняется очередность команд и загрузке разрешается завершиться перед выгрузкой. В тех маловероятных случаях, когда предсказатель ошибется, загрузку придется проводить заново ценой сброса конвейера (подобно тому, как это происходит в случае ошибки предсказания перехода). У архитектуры K8 не было эквивалентной схемы, которая бы разрешала выполнение загрузки перед другими загрузками и выгрузками, поэтому даже без интегрированного на кристалле контроллера памяти Intel может выполнять некоторые операции с памятью быстрее, чем K8. У Barcelona эта проблема решена вводом схемы, почти идентичной той, что Intel сделала у процессоров Core 2. Теперь и Barcelona может менять очередность и ставить одни загрузки перед другими, точно так же, как это может Core 2. Также загрузка может выполняться перед другими выгрузками, при условии, что процессор знает, что эти две операции не используют один и тот же адрес памяти. В то время как для определения того, что выгрузка и загрузка конфликтуют, Intel использует предсказатель, AMD использует более консервативный подход. До принятия решения о том, что загрузка может быть осуществлена перед выгрузкой, Barcelona ждет, пока адрес выгрузки не будет вычислен. Работая по такой схеме, Barcelona никогда не ошибается и он не может получить штраф за неправильное предсказание. Инженеры AMD рассмотрели интеловский алгоритм работы предсказателя, и решили, что для их архитектуры он не даст прироста в быстродействии. AMD может вычислить до трех адресов выгрузки за такт, так как у неё имеется 3 блока расчета адресов (AGU - Address Generation Unit), по сравнению с одним блоком на выгрузку у Intel, так что у AMD больше вычислительных мощностей для вычисления адреса выгрузки ещё до того, как поставить загрузку перед выгрузкой. Улучшение во внеочередности загрузки у Barcelona должно быть даже более эффективным, чем у Core 2, при том, что раньше AMD не могла делать никаких перестановок загрузок до Int/FP шедулеров, тогда как Core Duo мог производить ограниченное число перестановок. [N6-Другие изменения] Буферы трансляции-просмотра Translation Lookaside Buffer (TLB) используются для кэширования карты виртуальных адресов распределения физической памяти системы. Частота успешных обращений к TLB обычно весьма высокая, но, по мере того как программы становятся все больше и им нужно всё больше памяти, конструкторам процессоров приходится подгонять под них и объемы TLB. У K8 TLB больше, чем у K7, и с Barcelona AMD придется проделать то же самое. TLB у Barcelona немного больше, чем у K8, но они поддерживают 1G страницы, которые нужны для баз данных и виртуализации нагрузки. У Barcelona AMD также сделала 128 входов 2M L2 TLB, что также помогает при работе с новыми программами, для которых нужны большие page файлы. Усовершенствования TLB у Barcelona не будут заметны при работе с настольными приложениями, но производительность в корпоративном использовании должна увеличиться в серверных приложениях, для которых нужны большие объемы памяти. Когда Intel выпустила свой второй Pentium M, под кодовым названием Dothan, одним из улучшений у него была меньшая задержка при делении целых чисел. Хотя сейчас подробности неизвестны, но AMD заявляет, что у Barcelona аналогичная задержка тоже уменьшена. Нельзя сказать, чем эти изменения похожи на то, что сделала Intel у Dothan, но, по-видимому, это усовершенствование не может сильно повлиять на скорость работы с обычными приложениями. Это одно из тех изменений, которое внесет вклад в увеличение общего быстродействия, но оно не из тех, что могут удвоить скорость работы с числами вообще. В другой попытке эффективно "расширить" Barcelona без существенного увеличения количества транзисторов, AMD перевела несколько команд в микрокоды и сделала их fastpath-инструкциями. Такие команды могут пройти через fastpath-декодер ядра значительно быстрее, чем происходит декодирование обычных микрокоманд. Команды CALL и RET-Imm теперь являются fastpath-командами, что является частью улучшения оптимизации байпасного стека (sideband stack optimization) Barcelona. Команды MOV из SSE регистров в целочисленные регистры также являются fastpath-командами. Говоря о командах, стоит сказать, что в Barcelona AMD также ввела несколько новых расширений для своей технологии ISA. Введены две новых команды для работы с битами: LZCNT и POPCNT. Leading Zero Count (LZCNT) считает число первых нулей операции, а Pop Count считает количество первых единиц. Обе эти команды предназначаются для приложений шифрования. AMD также вводит 4 новых SSE расширения: EXTRQ/INSERTQ, MOVNTSD/MOVNTSS. Первые два расширения – это маскирование и сдвиг, объединенные в одну команду, две последние – скалярная потоковая выгрузка (потоковая выгрузка, которая может быть применена к скалярным операндам). Некоторые из этих команд можно увидеть у Penryn и у других будущих процессоров Intel. [N7-Более быстрый контроллер памяти] С тех пор как AMD перенесла контроллер памяти на кристалл, она у каждого своего нового процессора делает его всё более совершенным. У Barcelona изменения значительные, и это должно существенно улучшить скорость работы памяти. Одной из сильных сторон интеловской архитектуры FB-DIMM, используемой в серверах Xeon, является возможность одновременной записи и чтения в/из буфера. Со стандартной памятью DDR2 можно делать только первое или второе, и вы теряете темп при переключении с одной операции на другую. Если у вас эти события происходят случайным образом, на это тратится много времени, чего бы не было, если бы сначала выполнялись все операции чтения, а после переключения – запись. Контроллер памяти K8 старается сначала произвести чтение, так как на это нужно меньше времени, но у Barcelona контроллер памяти более интеллектуальный. Теперь, вместо того чтобы произвести запись сразу же по приходу этой команды, они записываются в буфер, и как только буфер заполнится до заданного порога, контроллер выполнит подряд все эти операции. Таким образом, сокращаются задержки на переключение чтение/запись, что помогает увеличить пропускную способность и уменьшить задержки. У ядра K8 (Socket-940/939/AM2) один контроллер памяти с 128 битной шиной, а у Barcelona AMD разделила контроллер DRAM на два отдельных 64-битных контроллера. Каждым контроллером можно управлять независимо, поэтому мы получаем некоторое увеличение быстродействия, особенно при задействовании 4 ядер, когда каждое ядро работает со своим потоком данных и своим массивом ячеек памяти. Северный мост Barcelona также сделан так, чтобы обеспечивать более высокую пропускную способность, чем была раньше. У него более объемные буферы, что позволяет поддерживать более высокую пропускную способность, и северный мост уже подготовлен для работы с будущими технологиями памяти (например, DDR3). По-видимому, AMD переключит Barcelona на новую память только после выхода одной или двух модификаций процессора, а пока новое ядро дебютирует с поддержкой DDR2. [N8-Новый блок предвыборки] Предвыборка осуществляется многими компонентами системы и во многих алгоритмах. Когда NVIDIA выпустила чипсет nForce2, он поразил тем, что мог делать интеллектуальную предвыборку при работе с очень широкой, на то время, 128-битной шиной памяти. Позже, с выходом процессоров Core 2, его 3 блока предвыборки на ядро позволили значительного уменьшить задержки при работе с памятью. Ядро K8 имеет 2 блока предвыборки на ядро – один для команд, и один для данных. Ядро Barcelona имеет столько же блоков предвыборки, но они улучшены. Самое большое изменение – блок предвыборки данных теперь переносит данные прямо в L1 кэш данных, а не в L2 кэш, как у K8. AMD изучила точность работы блоков предвыборки, и пришла к выводу, что они работают довольно хорошо, поэтому имеет смысл делать предвыборку только в быстром L1 кэше и не засорять L2 кэш. AMD также увеличила гибкость своего блока предвыборки команд L1 кэша, чтобы он мог обрабатывать 2 предстоящих запроса по любому адресу. На первый взгляд, предвыборка Intel у Core 2 солиднее, по крайней мере, блоков предвыборки у этих процессоров больше, чем даже AMD планирует для Barcelona. Напомним, что у Core 2 у каждого ядра 2 блока предвыборки данных и 1 блок предвыборки команд, плюс 2 дополнительных блока предвыборки в L2 кэше, и все они хорошо контролируются, чтобы они не злоупотребляли запросами. В то же время нужно иметь в виду, что Intel эти предвыборки нужны для маскировки более длинного пути до оперативной памяти. Если говорить о перспективах CPU, преимущество здесь у Intel, но, говоря о платформе в целом, здесь трудно отдать кому-нибудь предпочтение. Каждое ядро Barcelona имеет свой набор блоков предвыборки команд, но главное его усовершенствование в том, что теперь у него есть новый блок предвыборки – блок предвыборки DRAM. Расположенное в контроллере памяти, где раньше у AMD никогда не было подобного блока логики, новый блок предвыборки DRAM просматривает все запросы к памяти и старается извлечь из неё данные, которые, по его мнению, понадобятся в будущем. Так как этот блок предвыборки помогает всем четырем ядрам по отдельности, он реально помогает всему процессору улучшить производительность, и может эффективно намечать тенденции, которые будут положительно влиять на работу всех ядер. Блок предвыборки DRAM не переносит данные ни в L2, ни в L3 кэш CPU – у него есть собственный буфер, поэтому он не засоряет кэши. У этого буфера примерно 20 - 30 строк кэша и он может быть тем же самым буфером, который использует Barcelona для накопления записей, о котором говорилось на предыдущей странице. [N9-Добавим ещё транзисторов – L3 кэш] AMD уже давно проиграла гонку кэшей Intel, но только из-за технологических возможностей. В AMD знают, что они не могут угнаться за Intel по размещению большего числа транзисторов на тех же кристаллах, поэтому они придумали отличную вещь – сделать на кристалле процессора интегрированный контроллер памяти. С накристалльным контроллером памяти у K8 AMD уменьшила необходимость иметь большие кэши, поэтому даже нынешние Athlon 64 X2 имеют L2 кэш объемом всего 512 Кбайт на ядро – столько же Intel делала уже в 2002 году у своего ядра Northwood. Сейчас у двух ядер Core2 4 МБ общего L2 кэша, в то время как у самого быстрого процессора AMD он в 2 раза меньше. Отставание продолжится и с Barcelona, так как каждое из его четырех ядер будет иметь только 512 кБ L2 кэш. В то время как четырехъядерный чип Barcelona будет иметь в сумме 2 МБ кэша L2 на все 4 ядра, четырехъядерный Kentsfield в настоящее время имеет 8 МБ L2 кэш на 4 ядра. К концу этого года ожидается, что у интеловского Penryn будет 12 МБ L2 кэш на все его ядра. Чтобы сохранить размеры кристалла приемлемыми, AMD сделала свой четырехъядерный процессор Barcelona на одном кристалле с 4 ядрами, у каждого 128 кБ L1 и 512 кБ L2 кэш – как у большинства сегодняшних массовых K8. Однако в эру многопотоковых приложений, для обеспечения высокой производительности, многоядерным CPU нужен общий пул скоростной памяти. 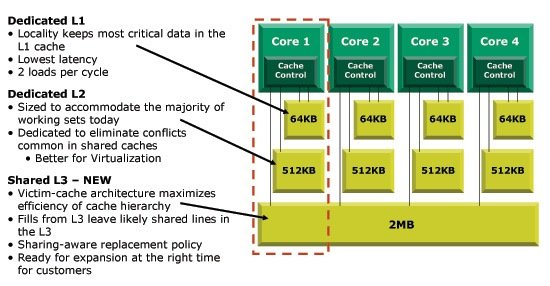 Иерархия в Barcelona работает таким образом: L2 кэши заполняются излишками L1 кэшей. Когда кэш заполняется до конца, данные, которые не использовались в последнее время, освобождают место для новых данных, которые контроллер кэш-памяти посчитает нужным иметь в кэше. В структуре кэша с запасником, выселенные данные помещаются в участок памяти, известный как запасник, а не удаляются из кэша сразу. Если данные снова понадобятся, кэш-контроллер просто возьмет их запасника, а не из намного более медленной оперативной памяти. Barcelona отселяет данные из L1 кэша в L2 кэш. Новый кэш L3 работает как запасник для L2 кэшей. Поэтому, когда маленький L2 кэш заполняется, выселенные данные переносятся в более объемный L3 кэш, где они и хранятся до тех пор, пока не понадобится место для новых данных. Алгоритмы, которые управляют работой L3 кэша, стараются сохранять в нем данные, которые могут понадобиться нескольким ядрам. Если CPU сделает выборку кода, его копия останется в L3 кэше, чтобы этот код был доступен всем четырем ядрам. Но простая загрузка данных осуществляется независимо. Контроллер кэш-памяти следит за хронологией, и если данные уже были в общем доступе, их копия остается в L3 кэше; если нет – они не сохраняются. У L1 и L2 кэшей ассоциативность не изменена – 2 и 16 уровней соответственно. Однако у нового L3 кэша уровень ассоциативности 32. Это должно повысить число успешных обращений к относительно маленькому, по сравнению с его конкурентами, кэшу. [N10-Улучшение виртуализации AMD] Говоря об увеличении быстродействия, стоит отметить, что у Barcelona увеличена скорость переадресации адресов виртуализации. В виртуальном программном стеке, где гипервизор управляет несколькими гостевыми ОС, трансляция адресов памяти происходит по-новому, и с этим тоже нужно уметь работать: нужно производить переадресацию от гостевой ОС к гипервизору, так как у каждой гостевой ОС свой собственный диспетчер памяти. Согласно AMD, в настоящее время этот новый уровень переадресации осуществляется программно методом shadow paging. В качестве альтернативы shadow paging Barcelona предлагает Nested Paging – свою технологию с аппаратным ускорением. Предположительно до 75% времени гипервизор может работать с теневыми страницами, которые AMD ликвидирует, научив процессор работать как с гостевыми таблицами страниц, так и с хостовыми. Транслируемые адреса кэшируются в новом большем буфере TLB, что ещё больше увеличивает производительность. AMD указывает, что включить поддержку Nested Paging у Barcelona очень просто; достаточно установить соответствующий бит режима, что разработчики ПО могут легко осуществить. Управление питаниемПоследним раскрытым аспектом дизайна Barcelona является управление питанием. Хотя все 4 ядра все еще работают на одном уровне питания (одинаковое напряжение), северный мост Barcelona теперь имеет независимое питание. Напряжения ядра и северного моста у Barcelona могут изменяться в пределах 0,8 - 1,4 В независимо друг от друга. В обычной платформенной архитектуре северный мост является отдельным от CPU чипом, и у них разные шины питания. Плюсом такой конструкции является то, что эти две микросхемы могут снижать своё энергопотребление независимо друг от друга. Поэтому, когда у контроллера памяти мало работы, он может перейти в состояние с пониженным энергопотреблением и оставаться в нем до тех пор, пока он не понадобится. У K8 этого нет, так как северный мост и ядро(ра) CPU имеют общую шину питания. У Barcelona шины сделаны разными, чтобы можно было улучшить эффективность энергопотребления. На все ядра подается одно и то же опорное напряжение, но каждое ядро имеет свой собственный PLL, так что, в зависимости от загрузки, они могут работать на разных тактовых частотах. Хотя напряжение на все 4 ядра подается одинаковое, тактовую частоту, а, следовательно, и ток, проходящий через каждое отдельное ядро, можно уменьшить в соответствии с загрузкой этого ядра, что даст экономию электроэнергии при поддержании нужной производительности процессора. Особенно это интересно для настольных компьютеров, так как не часто у них загружены все ядра процессоров на 100%. Barcelona поддерживает до 5 независимых энергетических уровней для каждого ядра, которые отличаются только тактовой частотой. Эти уровни полностью контролируются аппаратно, поэтому для задействования этой функции драйвер не нужен. У Barcelona AMD также увеличила количество ступеней и объектов clock gating, по сравнению с K8, в том числе и у логики. Больше об этом AMD ничего не сообщает, но учитывая, сколько времени прошло с выхода K8, можно ожидать, что здесь можно было многое сделать. Улучшение эффективности Barcelona, вместе с обновленным управлением питанием, продвинутый clock gating и 65 нм техпроцесс позволят первому четырехъядерному процессору AMD иметь такое же энергопотребление, как у нынешних Opteron'ов. [N11-Заключение] Когда Intel выпустила свой первый Core 2 процессор, улучшение производительности было просто революционным. Это самое большое увеличение производительности, которое мы видели у нового процессора за несколько прошлых лет, к тому же ничего близкого тоже не было. Большая часть успеха Core 2 основана на его архитектуре, но нельзя отрицать того, что она бы не появилась, если бы у Intel дела шли хорошо. Все, что нужно было сделать Conroe, Merom и Woodcrest – опередить по быстродействию стареющие и неудачные процессоры Pentium 4 с ядром NetBurst. Процессоры AMD делали это довольно легко и много раз, начиная с их появления в 2000 году. Не имея соперников в лице Intel, AMD и не старалась сильно от неё оторваться. Хотя архитектура K8 на то время была успешной, но она устаревала. С начала своего появления в 2003 году у неё не было серьезного изменения в архитектуре, что могло бы увеличить её производительность, и она была для Intel как неподвижная мишень. С каждой последовательной итерацией архитектуры Pentium M, Intel приближалась всё ближе и ближе с разработкой своего процессора, который бы мог обойти Athlon 64, и в итоге она его сделала – это Core 2 Duo. Это не было какое-то мистическое действо по созданию процессора, которое позволило Intel в прошлом году вырваться вперед – это была хорошая архитектура и удачное время. Довольно иронично – это те же самые два элемента, которые во многом способствовали успеху архитектур K7 и K8 AMD; они обе были хорошо сконструированы и появились в то время, когда у соперника дела шли не важно. &nb |
Источник: www.anandtech.com/