Каталог
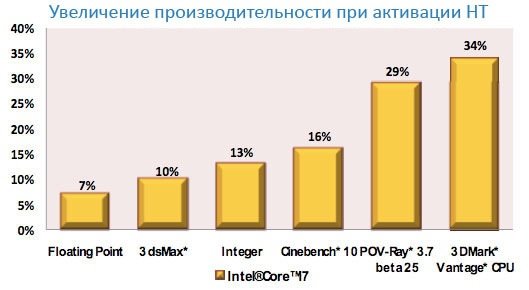
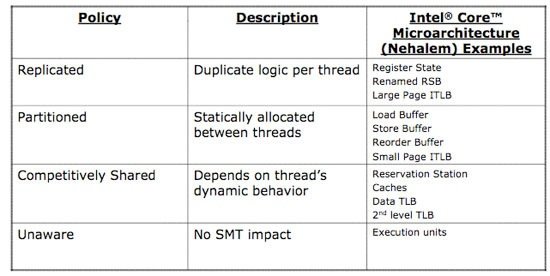
Новый TLB, быстрый доступ к инструкцям в кэше с неопределенным размеромИсторически так сложилось, что именно серверные приложения, такие как уже упомянутые базы данных, по максимуму используют логику трансляции виртуальных адресов памяти в физические, что и является основной работой TLB. Вспоминая о серверной направленности Nehalem, мы не удивляемся, видя в списке нововведений обновленный юнит TLB. Помимо простого увеличения размеров буфера страниц первого уровня, инженеры Intel применили при модернизации TLB тот же прием, что и при улучшении блока предсказания ветвлений – “надстроили” второй унифицированный уровень Translation Lookaside Buffer, отвечающий и за данные, и за код. 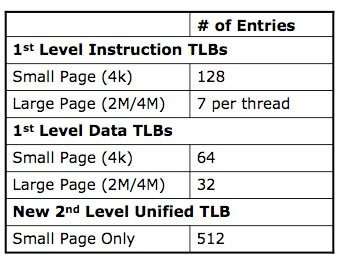 Когда компиляторы при обработке исходного кода не могут гарантировать попадание в 16-байтные границы, процессоры Core 2 получают серьезные просадки производительности, даже тогда, когда выполняется операция незаданного размера над данными известного объема. Этому должен препятствовать внутренний 64-байтный микробуфер для хранения обработанных 16-байтных контейнеров, но и на него накладываются ограничения по сложности инструкций. Ранее разработчикам приходилось писать дополнительный код, специально нацеленный на программное исправление данного явления. Теперь же в этом нет нужды – в Nehalem Intel удалось не только полностью избавиться от проблем при исполнении операций неизвестного размера над данными известного, но и кардинально снизить падение скорости, когда не определены ни размеры инструкции, ни данных. Даже если при компиляции всегда будут использованы операции необъявленного размера (кстати, это стандартная настройка во многих средах разработки), или же декодер каждый раз будет натыкаться на блоки свыше 16 байт, это не приведет к серьезным потерям производительности, а программистам сэкономит время. 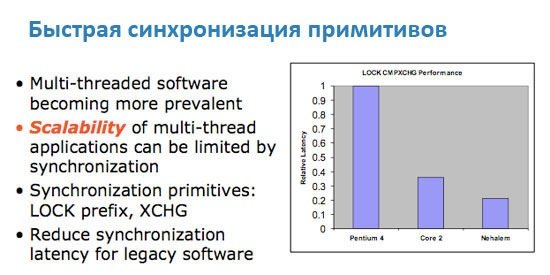 [N8-Новое поколение Hyper Threading] Много времени утекло с того момента, когда корпорация Intel впервые представила процессоры Pentium 4 с первой версией технологии Hyper Threading. Когда еще не было прямых предпосылок к увеличению количества ядер в домашних ПК, Intel уже предопределяла будущее индустрии микропроцессоров, подготавливая программистов к “параллельному” будущему. HT – маркетинговое название технологии SMT (Simultaneous Multi-Threading, одновременная многопоточность), предполагающей благодаря специальным механизмам исполнение за один такт инструкций из двух потоков. Операционная система определяет ПК с Hyper Threading как многопроцессорную конфигурацию, разделяя команды в несколько линий (в случае с P4 – одно ядро могло обрабатывать две линии). При проектировании Core от HT решено было отказаться, ведь даже сейчас для большинства домашних потребностей достаточно и двух ядер. Сегодня Hyper Threading возвращается в Nehalem (опять же – серверная ориентация, только профессиональные приложения получают существенный прирост даже от увеличения количества физических ядер), однако теперь производительность новой инкарнации HT будет на порядок выше первой версии. На это есть несколько причин:
  [N9-Иерархия кэш-памяти] Вообще говоря, красноречиво говорит за себя данный слайд:  Кэш ядер L1 располагает таким же объемом, как и Penryn, однако скорость его работы снижена (3 такта против 4). Intel пришлось замедлить кэш L1, так как он серьезно ограничивал общую тактовую частоту CPU. Конечно, такое решение было принято после многочисленных исследований производительности. С учетом большой площади кристалла процессора и его общей сложности оказалось, что намного лучше принести в жертву низкие задержки кэша, нежели ограничивать верхнюю планку частоту. По данным Intel увеличение задержек L1 на треть приводит к потери всего 2-3% производительности. Придется проверить на слово, инструментов для проверки таких заявлений нет. L2 сравнивать напрямую с предшественниками особого смысла нет, ведь в предыдущих реализациях архитектуры Core основной массив набортной памяти ядер являлся как раз общим кэшем второго уровня, теперь же такую функцию выполняет L3, а L2 является локальным для каждого ядра, урезан с 6 Мб до 256 Кб и обладает задержкой в 10 тактов. Фактически, L2 является неким дополнительным буфером кэша L3, который сдерживает при нехватке данных одновременное обращение всех ядер в L3 (мгновенная потребность в огромной внутренней ПСП вполне может привести у резкому падению производительности). Как мы уже упоминали, L3 является общим для всех ядер и выполняет старые функции L2. В первых процессорах Core i7 его объем будет составлять 8 Мб, однако Intel уже сейчас говорит о том, что эта характеристика будет варьироваться в зависимости от количества процессорных ядер. В Bloomfield наличие 8 Мб L3 оправдано тем, что многопоточные приложения всегда получают прирост от большого объема кэша, доступ к которому есть у всех ядер. Следуя традициям, Intel сохраняет инклюзивную структуру кэша в Nehalem. Иными словами, в L3 содержатся все данные из L1 и L2. Очевидным достоинством такого подхода является то, что данные L1+L2 пропорционально занимают не так много места с учетом большого объема L3, при этом если ядро обращаясь в L3 не находит там нужных данных, не происходит дополнительных запросов в L1 и L2 других ядер. Это не только повышает производительность, но и снижает энергопотребление CPU. К тому же не стоит забывать, что если бы кэш третьего уровня был не инклюзивным, уже в Quad-Core процессоре каждое ядро искало бы данные в памяти трех других, что уж говорить о 8ми-ядерных конфигурациях Nehalem. [N10-Сниженное энергопотребление кэш-памяти] Еще одним фактом о Nehalem, который стал известен на IDF, является переход к использованию восьмитранзисторных ячеек (8-T) памяти SRAM для формирования массива кэша первого и второго уровней (L3 построен по старым нормам). Основное преимущество данного подхода состоит в снижении необходимого минимального напряжения для функционирования памяти, что в конечном итоге снижает энергопотребление, хотя и увеличивает площадь ядра. Нечто схожее было сделано и при проектировании Atom: “Вместо того чтобы поднимать напряжение и формировать небольшой массив из сигналов, в Intel применили специальный регистровый файл с одним портом на запись и одним на чтение, требующий меньшее напряжение для функционирования. Кэш теперь обладает большим размером ячеек (8 транзисторов на микро-матрицу), что позволяет без значимых затрат энергии сохранить приемлемый размер кэшей инструкций и данных L1. Но, так как при создании Atom приоритет отдавался энергопотреблению, все же пришлось, однако, несколько урезать быструю память и сделать L1 ассиметричным – 24Кб/32Кб. Только так оказалось возможным удержать планку уровня энергопотребления на низком уровне”. Итак, в Nehalem так же, как и в Atom, применены ячейки 8T для кэшей L1 и L2. Сделано это потому, что L1 и L2 занимают относительно мало места, и для них более чем рентабельно еще немного увеличить площадь, но при этом снизить минимальное необходимое ядру напряжение. С другой стороны массивный L3 и так огромен, расширять его неоправданно. Намного проще, заботясь об энергопотреблении, например, запитать его от отдельного канала. Как вы увидите дальше, Intel так и поступила, разделив питание ядер и остальных частей CPU.  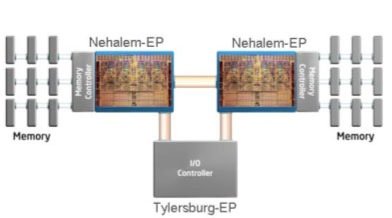 Несколько страниц мы уже не упоминали о серверной направленности Nehalem, сейчас самое время снова вспомнить об этом. В серверах используется дорогая буферизированная и достаточно медленная память с коррекцией ошибок ECC, поэтому применение агрессивных алгоритмов предвыборки данных в Xeon’ах, построенных на базе ядер Core, не всегда оправданно. Получается, что и так небольшая ПСП еще сильнее уменьшается, когда по шине прокачиваются необходимые блокам предварительной выборки данные. Приложения, которым нужна большая пропускная способность от такого только страдают. С учетом огромной ПСП Nehalem, абсолютно излишней в домашних условиях, эта проблема отпадает сама собой – пропускной способности в буквальном смысле хватит на всех. [N12-Quick Path Interconnect] Естественно, что с отказом от чипсетного контроллера памяти и соответственно шины FSB, Intel было необходимо разработать новый интерфейс связи вроде Hyper Transport, используемой AMD. Такой шиной и стала новая Quick Path Interconnect (QPI). Каждый линк QPI является двунаправленным и поддерживает до 6.4 Гб/с в одну сторону. При этом каждый линк обладает шириной в 2 байта, что дает 12.8 Гб/с, а в сумме получаются внушительные 25.6 Гб/с. 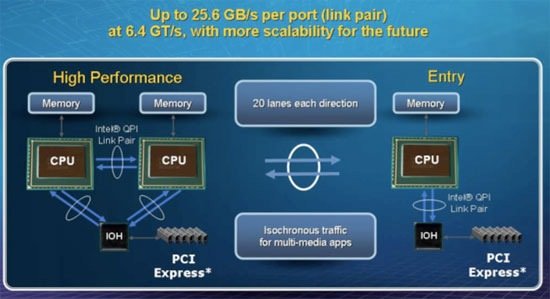 Разработчики серверных приложений теперь будут беспокоиться о корректной работе софта на мульти-сокетных платформах Intel, ведь у каждого CPU в наличие свой собственный массив памяти, и программы при работе должны будут четко различать с каким процессором, и, соответственно областью памяти они работают во избежание возникновения коллизий. Как и в случае со встроенным контроллером памяти, AMD ввела шину HT намного раньше Intel. В каком-то смысле это сейчас сыграло на руку Intel, так как приложения, оптимизированные для HT, будут работать на Nehalem с QPI существенно быстрее, чем работали на старых Xeon. [N13- Новые инструкции SSE] Вместе с выпуском Penryn, Intel расширила список мультимедийных инструкций набором SSE4.1, в Nehalem сделано еще несколько дополнений – теперь процессор поддерживает SSE4.2: 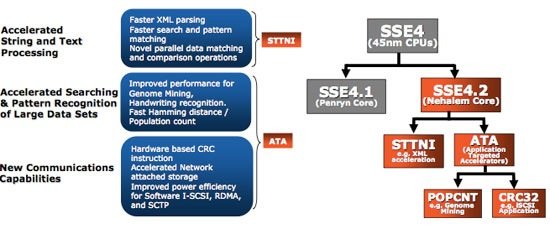  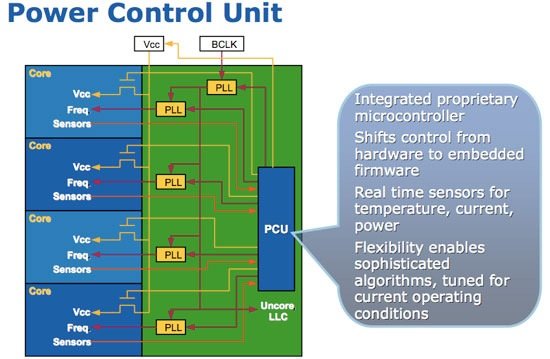 Благодаря плотной совместной работе архитекторов Nehalem и производственных инженеров, в Intel создали узкоспециализированный материал, который встраивается между источником энергии и самим ядром и служит контрольным пунктом подачи энергии на ядро.   Используя вновь-разработанные энергетические шлюзы можно беспрепятственно вводить неиспользуемые ядра в “глубокий сон”, снижая напряжение отдельного ядра безо всяких выделенных линий питания. Сегодняшние процессоры такой возможности не имеют, и, снижая рабочие частоты отдельных ядер, оставляют напряжение неизменным, что приводит к дополнительному выделению энергии неиспользуемыми блоками. Nehalem этого недостатка лишен, и ненужные в данный момент ядра могут быть просто отключены. Еще один плюс технологии в том, что при интеграции на кристалл управляющей логики, изменение напряжений происходит на порядок быстрее, чем при наличии отдельного чипа на материнской плате. Также интересным моментом является то, что PCU работает в паре с операционной системой, запрашивая данные о нагрузке на разные ядра и производительности. На основании этой информации сам PCU принимает решения об отключении/включении ядер вне зависимости от того, какие команды дает ОС. Нередко при управлении операционной системой возникают проблемы разного рода (вспомним недавние приключения с Phenom, лишенными такого механизма), например ОС отключает ядро для того, чтобы в следующий момент ненадолго снова включить его. Как раз чтобы избежать таких ситуаций, которые, помимо неоптимального температурного и энергетических режимов, еще и снижают производительность на значимую величину, в PCU и сделано взаимодействие с ОС. [N15- Турбо-режим] Фактически, это последнее из рассматриваемых нами сегодня нововведений уже было представлено в мобильной версии Penryn. Идея так называемого “турбо-режима” состоит в том, что если двухъядерный CPU работает в однопоточном приложении и второе ядро не задействовано таким образом вообще, общий TDP чипа соответственно снижается относительно допустимого. Эти условия можно использовать для некоторого поднятия частоты активного ядра, и, соответственно, производительности. TDP в таком случае все равно останется низким, а неоптимизированное под многоядерность приложение будет работать быстрее. К сожалению, эта функция не особо хорошо работала в мобильных Penryn, так как у них не было выделенного блока PCU, а Vista, установленная на большинстве ноутбуков, постоянно перекидывала задачи с ядра на ядро в попытках более равномерно загрузить процессор. Nehalem в этом отношении работает намного лучше. PCU не только способствует более корректному управлению энергопитанием и степенью активности ядер, но и может включать Turbo Mode при целом комплексе условий, а не только, когда, например, 2 ядра из 4 не заняты работой.  Конечно, технология эта предназначена для неискушенных пользователей, которые не хотят рисковать вручную разгонять процессор, и будут рады даже 5% бесплатной прибавки скорости. Для таких покупателей приятная новость может состоять в том, что 266 МГц Intel ограничиваться не собирается и в будущих процессорах количество ступеней поднятия частоты будет увеличено. Все-таки даже автоматические системы разгона из BIOS материнских плат достигают более значимых результатов, чего уж говорить о нормальном подконтрольном человеку режиме оверклокинга. Как раз для таких случаев, кстати, турбо-режим можно отключить. Кстати говоря, если тестеры будут оставлять данную технологию включенной, процессоры Intel будут соревноваться с конкурентами не совсем честно – схожие методы были у ATI с введением VPU Overdrive, автоматически повышающей частоты видеочипа на безопасные величины. Конечно, пока AMD не в состоянии противопоставить CPU Core/Nehalem ничего существенного, но факт остается фактом, ведь зачастую процессоры с повышенной даже на 100 МГц тактовой частотой стоят уже существенно дороже своих младших собратьев. [N16- Стартовые частоты и прогнозы по производительности] Уже сейчас достоверно известно, что стартовыми моделями Nehalem будут три процессора Core i7 с частотами в 2.66, 2.93 и 3.2 ГГц. Точные индексы – 920, 940 и 960 соответственно. Все процессоры получат 8 Мб кэша L3, и будут четырехъядерными (как раз такими, как сфотографированный в начале статьи). Конструктивно CPU будут выполнены в форм-факторе LGA1366 (3х канальный контроллер DDR3 и 2 линка QPI), тактовый генератор, заменяющий стандартную частоту FSB, будет работать на 133 МГц. Материнская плата потребуется с соответствующим сокетом, а первый настольный чипсет для Bloomfield будет называть Tylesberg (X58 в рознице). Когда ждать домашние процессоры, не нацеленные в первую очередь на энтузиастов, с сокетом LGA1160, парой каналов DDR3 и одним линком QPI пока неизвестно. Турбо-режим будет представлен лишь двумя ступенями с возможным повышением частоты либо на 133 МГц в худшем случае, либо на 266 в лучшем – в зависимости от условий. О ценах пока говорить сложно, во всяком случае, рекомендуемые величины не будут сильно завышены относительно четырехъядерных Penryn. Что касается производительности, несмотря на NDA данные уже просачиваются в сеть. Конечно, согласно нашему рассказу об архитектуре, наибольшее влияние будет заметно в серверных приложениях, однако существует и много домашних отлично распараллеленных приложений, в которых эффект от доработок также не замедлит сказаться. Кодирование видео, 3D-рендеринг, архивация, программы, предъявляющие существенные требования к ПСП – все это работает на Bloomfield существенно быстрее, чем на Penryn. Если же разработчики не утруждались распределением потоков вычислений по нескольким ядрам, стоит ожидать небольшого увеличения скорости до 15% в сравнении со старыми Core в зависимости от приложения. Частотный потенциал процессоров радует – эксперименты по разгону показывают, что Bloomfield, несмотря на намного более сложный по сравнению с Penryn кристалл, свободно работает на частотах около 4 ГГц при воздушном охлаждении. При этом не стоит забыват |
Источник: www.anandtech.com/