Каталог
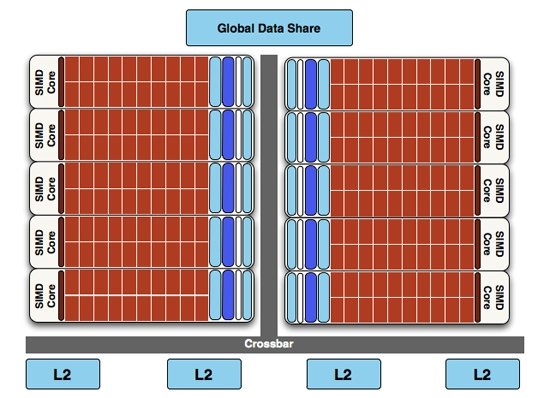
Знакомство с остальными решениями EvergreenПохоже, что где-то по пути к Cypress AMD несколько отклонилась от пути создания кристаллов небольшой площади.  Cypress занимает 334 кв. мм, что существенно больше 260 кв. мм RV770, с учетом того, что последний производится по 55 нм нормам, а RV870 – по 40 нм. Причина заключается в том, что в новом чипе использовано целых 2.15 миллиарда транзисторов против 956 миллионов у RV770. А ведь еще совсем недавно 1.4 млрд у GT200 казались огромным числом... Естественно, это не могло не привести к увеличению энергопотребления (188 Вт против 160 Вт) карты. И, что менее приятно, к ее подорожанию. Так, если на старте рекомендованные цены на HD 4870 и HD 4850 составляли €299 и €199 соответственно, в случае с HD 5870 и HD 5850 они выросли до €379 и €259. Естественно, чип новый и очень сложный, необходимо окупить затраты на разработку и «снять сливки», пока первый чип класса Fermi от NVIDIA только готовится к выходу, и в будущем цены будут снижаться, но сам факт такого удорожания настораживает. К тому же, AMD называла 256 кв. мм оптимальной площадью для GPU, а Cypress серьезно превосходит эту величину. Более того, уже сейчас понятно, что следующая архитектура AMD должна будет нести не столько количественные, сколько качественные изменения. Ведь фактически, как и в случае с GT200 у NVIDIA (который, не смотря на множество мелких отличий и усовершенствований, по сути, был увеличенным G80), RV870 является последователем RV770. С выпуском GTX серии NVIDIA поняла, что дальше изменять G80 невозможно, и принялась за разработку новой архитектуры, которая и будет впервые реализована в GF100. Для того чтобы сохранить конкурентное преимущество и не оказаться снова в ситуации, схожей с выпуском R600 или Phenom первого поколения, AMD/ATI стоит уже сейчас задуматься о своем следующем шаге. Ведь очевидно, что очередного удвоения исполнительных блоков будет недостаточно для эффективной конкуренции с NVIDIA на следующем витке борьбы, да и уже сейчас соотношение производительности и количества транзисторов не выглядит таким впечатляющим, как при выводе на рынок RV770. Кроме того, из-за большой площади RV870 во избежание пробелов в своей линейке для более дешевых карт AMD планирует выпуск еще одного чипа в семействе Evergreen.  Ситуация с топовыми картами понятна. Как и раньше, наиболее быстрые одиночные платы AMD будут использовать внутренний Crossfire (возможно, наконец-то заработает Sideport) и состоять из двух полноценных чипов RV870. Точной информации о Hemlock пока что нет, хотя в Сети уже проскакивали первые фотографии. Пока что известно, что AMD оперативно решает проблему высокого энергопотребления плат (еще бы – ведь и 4870X2 был очень горячим и громким, как поведут себя два RV870 на одной PCB представить довольно сложно). Из-за этого ходят различные слухи, что, возможно, 5870X2 представлен не будет вообще, а свет увидит лишь 5850X2. По аналогии – NVIDIA не решилась использовать в GTX 295 два полноценных GT200b, так что GTX 285 представляет собой не удвоенный GTX 285, а скорее GTX 275. Так же может поступить и AMD в этом поколении. Но пока что все это предположения, не подкрепленные фактами. Какой уровень производительности покажет 5800X2, и как он будет соотноситься с Fermi, мы узнаем совсем скоро. Пока же нас интересуют не 300 Вт монстры (ведь две HD 5870 потребляют до 376 Вт в Crossfire), а более дешевые платы, которые попадут в нишу до двухсот евро, которую в прошлом поколении занимал HD 4850. Именно здесь, похоже, и стоит ожидать появления еще одного чипа семейства Evergreen под именем Juniper. Хотя его анонс и намечен на Ноябрь, сейчас нет точных данных о характеристиках этого ускорителя. Ясно, что для того, чтобы вписать его в требуемые ценовые рамки, AMD придется уменьшить количество исполнительных блоков в чипе. По нашим расчетам стоит ожидать 14 SIMD блоков с соответствующим числом ROP, возможно, даже 192-битную шину памяти. Вопрос только в том, как собирается AMD выходить из такой ситуации при отсутствии компактного чипа. В случае с процессорами компания зачастую блокирует в полнофункциональных кристаллах ядра или кэш-память, но вряд ли на такое пойдут в случае с видеокартой ценой до 200 евро. Ведь даже в HD 5850 присутствуют деактивированные блоки. Тем не менее, не нам решать, что экономически выгоднее – использовать отбраковки производства RV870, назвав чип RV870LE, или же использовать новый кристалл, в котором изначально будет присутствовать меньшее число функциональных блоков.  С картами нижнего ценового диапазона таких проблем возникнуть не должно. Чипы Redwood и Cedar будут выпущены в первом квартале следующего года и станут заменой сегодняшних RV710 и RV730. Хотя они и будут построены на базе RV870, высокого уровня производительности ждать от таких карт не приходится. Подытоживая все вышесказанное, хочется отдельно отметить, что в ближайшие 6 месяцев AMD собирается выпустить 4 новых чипа, наделив всю свою линейку от самых бюджетных до топовых карт поддержкой DirectX 11. Уложиться в такой небольшой срок – сложная задача. Посмотрим, насколько успешно ATI сможет осуществить задуманное. Тем временем, перед тем как перейти к непосредственному тестированию новинки, необходимо разобраться в теоретических аспектах новой архитектуры. А для того, что бы лучше понять, чем в сущности является Cypress, освежим в памяти структуру его предшественника – RV770. [N5-Об архитектуре RV770 вкратце] Итак, центральная часть чипа RV770 – Stream Processing Unit (SPU), арифметико-логическая единица наиболее низкого уровня. Именно количество SPU обычно указывается в характеристиках чипа, однако более правильно было бы говорить о потоковых процессорах, Streaming Processor (SP), каждый из которых включает в себя 5 SPU. Помимо них у каждого потокового процессора имеется свой регистровый файл и блок предсказания ветвлений. Таким образом, хотя формально расчетами занимаются непосредственно SPU, корректней было бы говорить именно об SP, как об основных блочных составляющих чипа. Ведь именно будучи объединенными с необходимыми блоками логики пятерки SPU в составе SP способны работать эффективно, обрабатывая как стандартные функции для классических ALU, так и трансцендентные функции.  Имеющиеся в чипе потоковые процессоры сгруппированы по 16 штук, к ним добавлены текстурные модули, кэш L1, разделяемая память и управляющая логика. Такой укрупненный блок в терминологии AMD обозначается SIMD модулем, и RV770 состоит главным образом из десяти таких модулей, именно их количество определяет общую вычислительную мощь ядра, хотя в самом чипе, естественно, трудится еще множество разных составных частей, таких блоки растеризации, L2 кэши, аппаратные тесселяторы и т.д.  Однако все это великолепие не так-то просто использовать, как может показаться. Для того, что бы все доступные SP эффективно работали, нити инструкций передаются в них подготовленные специальным образом. Если говорить точнее, нити группируются во фронты, и в каждом таком фронте может находиться до 64 нитей. Таким образом, максимально эффективно чип может быть задействован только при исполнении команд с высоким уровнем параллелизма (Instruction Level Parallelism – ILP), так, чтобы все 5 SPU в каждом SP были загружены работой. А это, как вы понимаете, задача довольно сложная. Естественно, если SPU не загружены работой, общая производительность чипа падает, так как исполнительные модули попросту простаивают. Разработанная AMD архитектура обладает прекрасными теоретическими возможностями по вычислениям, но их грамотное использование – задача непростая.  Начиная с самого низкого уровня SPU, добавились несколько новых аппаратных инструкций, и увеличилась скорость исполнения старых. Это было сделано как для повышения производительности, так и для соответствия чипа стандартам различных API последних версий. Ускорение работы достигнуто за счет того, что некоторые инструкции, требующие ранее несколько циклов для исполнения, отныне могут быть рассчитаны за один заход. Поддержка необходимых для DirectX 11 команд, таких как count, insert и extract, была добавлена именно на этом уровне. Отдельное внимание было уделено обсчетом поднормалей, которые теперь производятся без потери скорости.  Наверное, одной из самых интересных добавленных инструкций стала сумма модулей разности – Sum of Absolute Differences (SAD). Она особенно часто применяется при кодировании видео и анализе графических данных, так как в геометрическом плане с ее помощью легко оценивать движение. В случае с RV770 аппаратная поддержка SAD попросту отсутствовала, а для ее эмуляции требовалась цепочка из, по меньшей мере, 12 инструкций. С добавлением SAD в SPU исполнение инструкции занимает один единственный такт, и, по словам AMD, это должно более чем в два раза убыстрить кодирование видео силами GPU. Несколько удручает, что SAD не является обязательной частью DirectX 11 или OpenCL, а это значит, что написанные под DX программы не могут вызывать ее, то же справедливо и для OpenCL, но для этого API хотя бы существует необходимая библиотека. С другой стороны, эти API не ограничивают жестко поведение GPU, поэтому динамический компилятор AMD может на лету распознать возможности оптимизаций (например – упомянутую выше цепь из 12 инструкций) и заменить необходимые части общего кода на более эффективные для данной конкретной архитектуры. То есть, даже если программист и не вызывал какие-либо нужные функции вручную, интеллектуальные алгоритмы смогут компенсировать это упущение самостоятельно. Так выглядит список инструкций, который блок SP Cypress может исполнять за один-единственный такт:
 Текстурные модули были также переработаны. Первое из внесенных изменений – добавленная возможность чтения сжатых AA цветовых буферов для более рационального использования пропускной способности. Второе – в AMD задались целью повысить скорость интерполяции, и реализовали это довольно интересным способом. Текстурные модули попросту лишили этой способности, перенеся ее в обязанности SP (это часть спецификаций DirectX 11). Это позволило значительно увеличить быстроту выполнения операций данного типа. Вследствие этого текстурные модули в Cypress имеют более высокую скорость закраски (филрейта), чем в RV770. Данное обстоятельство будет хорошо отражено в синтетических тестах. AMD утверждает, что чип способен в совокупности достигать показателя в 68 миллиардов билинейно отфильтрованных текселей в секунду, что является результатом переброски интерполяции на SP и проделанных оптимизаций для более рационального расходования пропускной способности. Наконец, снова делая шаг вверх по лестнице архитектурных уровней, мы добрались до основной причины превосходства в производительности RV870 над своим предшественником. AMD удвоила количество SIMD блоков с 10 до 20 штук. Это означает двукратное количественное превосходство по всему, начиная от SP и кончая текстурными модулями. Это довольно банальное изменение, в отличие от добавления новых низкоуровневых команд или переработки кэшей, зато наиболее действенное.  Естественно, для того, чтобы максимально эффективно загружать работой такое количество потоковых процессоров, были внесены и доработки в алгоритмы распределяющего диспетчера Ultra-Threaded Processor, 4 кэша L2 были удвоены с 64 до 128 Кб, причем одновременно с этим они получили ускорение в работе. Ранее они были связаны со сверхбыстрой памятью первого уровня на скорости до 384 Гб/с, теперь – 435 Гб/с. Наконец, общий буфер данных был увеличен в 4 раза, до 64 Кб. То есть, возвращаясь к нашему утверждению в начале статьи о необходимости расширения внутренних кэшей, мы видим, что AMD не только банально удвоила все исполнительные блоки и расширила их функциональность, но и позаботилась об отсутствии возможных узких мест.
Далее, для того, чтобы обработать все то, что рассчитывают SIMD процессоры, удвоили и ROP блоки. Это значит, что их число в Cypress возросло до 32 штук. Сами ROP также подверглись косметической переработке, в результате чего их производительность также несколько увеличилась. Теперь блоки растеризации способны проводить быструю цветовую очистку, согласно исследованиям AMD, многие игры сотни раз проводят такие операции между кадрами. Так же ROP ответственны и за некоторые этапы нового метода SSAA сглаживания, представленного ATI вместе с 5000 линейкой карт, но этого момента мы коснемся несколько позже. И, наконец, последнее усовершенствование по списку, но не по значимости – так называемый AMD Graphics Engine. 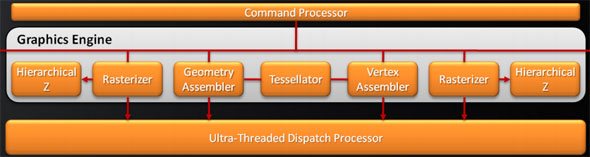 Блок аппаратной тесселяции появился еще в RV770, однако, несмотря на свои широкие возможности, разработчики игр практически не использовали его, обходя стороной. В DX11 появилось требования обязательного наличия такого блока в GPU, и имеющийся в RV770 был усовершенствован для соответствия спецификациям DX11. Причем если в RV770 такой модуль был один, для лучшего баланса и равномерности загрузки массива из 20 SIMD, в RV870 добавили второй. [N7-DirectX 11 Redux] С ранним выпуском 5800 серии AMD оказалась в довольно выигрышном положении. Компания предлагает пользователям графические решения с поддержкой DX11 на месяц раньше, чем станет доступен сам DirectX 11 с релизом Windows 7. NVIDIA же, углубившись в разработку своей новой архитектуры, в отношении внедрения возможностей DX11 в свои чипы довольно существенно отстала от ATI. Помимо очевидных маркетинговых преимуществ, Cypress впервые за долгое время стал стандартом де-факто для API Microsoft нового поколения. Ведь с ранним выходом чипа от AMD и отсутствием отлаженного и доведенного до ума конкурента от NVIDIA разработчики игр, желающие начать использование следующей версии библиотек DX уже сейчас, просто не имеют альтернативы. А, значит, игры будут разрабатываться в первую очередь с упором на архитектуру AMD, стремясь максимально полно задействовать ее возможности (а, как мы выяснили недавно, это не так просто), и стараться сглаживать недостатки. В прошлый раз ATI испытывала такой триумф только в 2002 году, когда Radeon 9700 PRO открыл эру DirectX 9; DX10 появился вместе с уникальной для своего времени унифицированной архитектурой G80, и долгое время NVIDIA доминировала из-за постоянных задержек и неудач канадской фирмы. Тем не менее, как и всегда, конечным пользователям не стоит судить о возможностях той или иной видеокарты по наличию поддержки API определенной версии. Во-первых, на данный момент пока нет даже каких-либо инструментов для оценки производительности RV870 в среде DirectX 11. Во-вторых, в первую очередь DirectX - это инструмент разработчика, и именно программист волен использовать те или иные инструменты, разработанные в Microsoft. Мы рассмотрим основные нововведения DX11 ниже. Стоить помнить, что DirectX 11 версии построен на базе DX10 (в то время как десятая модель API кардинально отличалась от своего предшественника), поэтому AMD не потребовалось проводить коренных изменений для трансформации видеоконвейера RV770 в то, что мы можем наблюдать в Cypress. 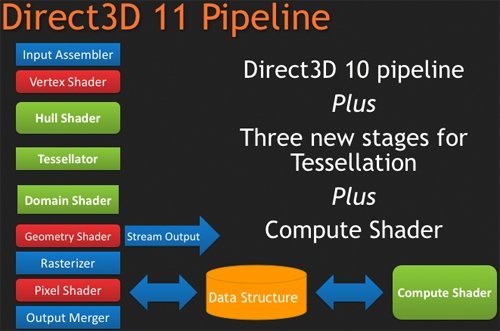 Наиболее значимыми нововведениями Direct3D стали система тесселяции, которая разбита на три этапа, и вычислительные шейдеры (Compur Shader). Первым делом на этапе подготовки к процессу тесселяции (после вершинных, до геометрических и пиксельных шейдеров) используются Hull Shader («скорлупка», из следующего абзаца будет легко понять, почему разработчики так назвали его). Этот тип шейдеров несет ответственность за выборку необходимых для формирования лоскутов модели и контрольных точек (направлений тесселяции). Затем в работу вступает отдельный аппаратный вычислительный блок высокого уровня сложности, в обязанности которого входит построение на базе изначальной геометрической модели и информации, просчитанной из Hull шейдеров, более сложной и детально проработанной структуры. Этот этап разработан для того, чтобы несколько разгрузить процесс формирования базовой геометрии сцены, когда излишняя проработка деталей требует огромной вычислительной мощности. С помощью процесса тесселяции в DX11 стало возможным без существенных затрат получить значительно более сложную модель объекта. Нет необходимости тратить дополнительные тысячи и десятки тысяч полигонов – с помощью Hull шейдеров отныне разработчик может создавать детальную модель, не нагружая GPU чрезмерно. Не стоит путать данную технологию с распространенными картами нормалей и бампмэппингом – хотя цель у этих разработок близка, алгоритмы различны, и, естественно, аппаратная тесселяция силами графического процессора – более прогрессивный, быстрый, и качественный вариант создания детализированных трехмерных объектов. Стоит отметить, что тесселятор не является непосредственно программируемым, он просто формирует новые поверхности на основании данных, которые поступают из шейдера с описанием точек «скорлупы». Тем не менее, фиксированный набор функций, который может быть рассчитан модулем, достаточно широк. После того, как сам процесс тесселяции завершен, результаты вычислений вместе с изначальными данными Hull шейдера попадают в Domain Shader, который, в свою очередь, уже производит все необходимые операции по совмещению и оценке полученных данных. Именно на этом этапе могут быть применены карты нормалей. Естественно, данное действие не является обязательным и приведено лишь в качестве примера. В зависимости от имеющихся инструкций, Domain шейдер может просто передать совокупные данные в обработку геометрическому шейдеру. Как вы видите, тесселяция является очень интересным способом получения более детализированной и, соответственно, реалистичной картинки. Тем не менее, использование этой функции целиком зависит от разработчика, ведь из конвейера D3D 11 версии эта стадия может быть вообще убрана, RV870 просто предоставляет аппаратную реализацию возможности стандарта, но никак не применяет тесселяцию в тех случаях, где это не предусмотрели программисты. Вообще, рассмотренная технология во многом появилась в DirectX 11 благодаря AMD. Первые версии блоков тесселяции компания ATI представляла еще в 2001 году, однако ни разу они не были оценены разработчиками по достоинству и не набрали популярность на PC (конечно, важная причина кроется и в отсутствии поддержки разработки у NVIDIA). Тесселятор, например, используется в Xbox 360, графический чип которого под кодовым названием Xenos разработан ATI, хотя его консольная реализация на порядок проще имеющейся сейчас в Cypress. В том же виде, в котором он присутствует в приставке Microsoft, тесселятор перешел в R600, но распространения, опять же, не получил. Но теперь, с введением стадий тесселяции в конвейер DX11, оба графических гиганта будут иметь чипы с поддержкой этой возможности, и, надеемся, со временем она будет применяться повсеместно. Принятие тесселяции на вооружение в DX11 – настоящая награда для AMD за длительные годы разработки этой возможности. Еще одно важнейшее нововведение в грядущем поколении Direct3D – вычислительные шейдеры. Они позволяют программам получать прямой доступ к математическим ресурсам GPU и работать с ним напрямую как с вычислительным, а не графическим процессором. Данный тип шейдеров может быть использован как в игровых приложениях, так и в программах любого другого типа, но во втором случае, когда эта возможность задействуется вне графического конвейера, обычно упоминается термин «прямых вычислений», DirectCompute, вместе вычислительных шейдеров. В любом случае, смысл от этого не меняется. А имеющиеся уже сейчас программы, использующие CUDA у NVIDIA и FireStream у ATI, показали, сколь огромным может быть ускорение от переноса вычислений некоторого типа с CPU на GPU (эта тенденция получила общее название GPGPU – General Purpose GPU, использование графических процессоров для вычислений общего типа). Безусловно, именно DirectX 11 (вместе с OpenCL) наконец-то сможет стать единым инструментом для проведения вычислений такого типа, однако в данный момент мы рассматриваем в первую очередь игровую видеокарту, и, как это ни странно, AMD предложила очень интересное применение, казалось бы, неуместным в обычной компьютерной игре вычислительным шейдерам. Речь идет об обсчете прозрачных текстур силами Compute Shader. Технология получила название Order Independent Transparency (внеочередная обработка прозрачности). Ее достоинство – возможность однопроходного рендеринга прозрачных поверхностей в оптимальном порядке. Хотя и раньше такой техникой пользовались, реализуя ее, например, средствами пиксельных шейдеров, с помощью вычислительных Compute Shader проделать необходимые операции можно будет существенно быстрее.  Естественно, поддержка тесселяции и нового типа вычислительных шейдеров – отнюдь не все, что отличает DirectX 11 от предшественника. В одиннадцатой версии API серьезные изменения претерпели стадии текстурирования Direct3D конвейера. Например, максимальный размер текстур был увеличен до 16K x 16K, то есть теперь могут быть использованы изображения вплоть до огромного разрешения в 256 Мп. На практике это означает, что DX11 позволяет работать с текстурами сколь угодно огромного размера – скорее закончится локальная видеопамять, чем будет достигнуто программное ограничение API. Также были добавлены две новых схемы сжатия текстур, BC6H и BC7. Как и в случае с добавлением тесселяции в конвейер D3D, их можно назвать детищем AMD. Дело в том, что эти алгоритмы компрессии были разработаны именно ATI, и затем включены в DX11 Microsoft. BC6H – первый в мире метод сжатия текстур, специально оптимизированный для HDR графики. Ранее для данных целей применялись менее эффективные BC3/DXT5. Он способен достигать впечатляющего соотношения компрессии 6:1 (с потерями качества). В то же время, BC7 теоретически должен стать заменой распространенным BC3/DXT5 в случае со стандартными RGB текстурами, он позволяет в три раза уменьшать размер изображений. Несмотря на то, что без реальных игр все эти теоретические рассуждения бесполезны, мы оцениваем значимость введение обязательной поддержки аппаратной тесселяции и новых методов сжатия текстур в DX11 очень высоко. Ведь фактически это серьезный толчок к росту качества графики компьютерных игр, на новый уровень выводятся как геометрическая, так и текстурная составляющие картинки. Тесселяция может без особых потерь производительности создавать более детализированные и проработанные 3D-модели, а новые технологии компрессии позволят натягивать на геометрический каркас текстуры более высокого разрешения и качества, не выходя за разумные пределы потребления видеопамяти. Мы надеялись представить в материале какие-либо скриншоты для сравнения изображения, полученного методами DX10 и DX11, но, к сожалению, найти достойные варианты вовремя не удалось. Тем не менее, по синтетическому бенчмарку, показанному Microsoft на GameFest 2008, можно верно оценить ценность нововведений. 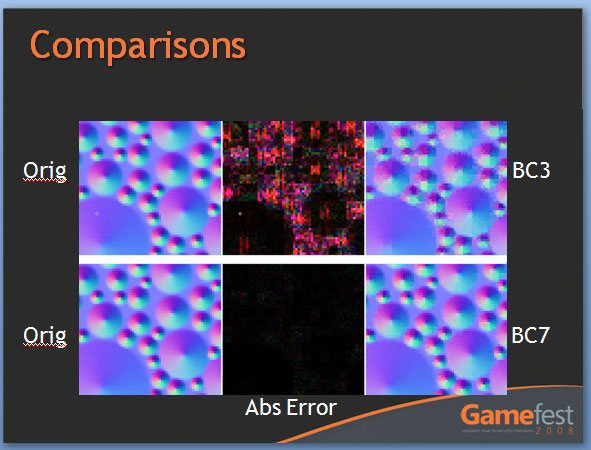 Переработке подвергся не только конвейер рендеринга Direct3D, еще одним значимым моментом DirectX 11 является улучшенная поддержка многопоточных вычислений. Отныне API поддерживает возможность получения указаний на создание ресурсов, управление состояниями или, скажем, принудительное завершения исполняемой команды от нескольких активных нитей. Ранее DX мог обрабатывать такой управляющий поток только в случае использования единственной нити. Эта оптимизация направлена на более рациональное использование ресурсов CPU, а значит, в ситуациях, когда производительность в графических приложениях будет упираться в видеокарту, мы сможем получить пусть небольшой, но заметный в критических ситуациях выигрыш в скорости. То есть это нововведение нацелено не на помощь самому CPU в случаях, когда его производительности не хватает, а именно на лучшее использование графической карты. Справедливости ради стоит отметить, что данная возможность не требует DX11 (может быть реализована с помощью специальной надстройки в DX10/10.1), однако впервые она будет представлена именно с DX11. Наконец, DirectX 11 вводит в обращение новый высокоуровневый язык шейдеров (High Level Shader Language) версии 5.0, в котором был добавлен ряд инструкций, сфокусированных на ускорении стандартных операций. Впервые появились классы и интерфейсы, которые позволят писать более структурированный и сегментированный код. Все это идет рука об руку с новыми алгоритмами интеллектуальных динамических связей шейдеров и их менеджмента. [N8-Первые игры DirectX 11] Каждый раз с выпуском новой версии DirectX и выхода карт, ее поддерживающих, встает вопрос о доступности игр для этой связки. Естественно, для разработки программных продуктов под очередной API, для начала требуется хотя бы иметь аппаратную платформу, соответствующую его требованиям. Это и служит логичным объяснением того, что какой бы «мягкой» ни была смена поколений DirectX, сначала на рынок выходит аппаратное обеспечение, и лишь затем | |||
Источник: www.anandtech.com/