Каталог
Архитектура RV870 – что нового?Вспомнив, как функционирует RV770, посмотрим, что же нового добавили инженеры AMD в Cypress. Начиная с самого низкого уровня SPU, добавились несколько новых аппаратных инструкций, и увеличилась скорость исполнения старых. Это было сделано как для повышения производительности, так и для соответствия чипа стандартам различных API последних версий. Ускорение работы достигнуто за счет того, что некоторые инструкции, требующие ранее несколько циклов для исполнения, отныне могут быть рассчитаны за один заход. Поддержка необходимых для DirectX 11 команд, таких как count, insert и extract, была добавлена именно на этом уровне. Отдельное внимание было уделено обсчетом поднормалей, которые теперь производятся без потери скорости.  Наверное, одной из самых интересных добавленных инструкций стала сумма модулей разности – Sum of Absolute Differences (SAD). Она особенно часто применяется при кодировании видео и анализе графических данных, так как в геометрическом плане с ее помощью легко оценивать движение. В случае с RV770 аппаратная поддержка SAD попросту отсутствовала, а для ее эмуляции требовалась цепочка из, по меньшей мере, 12 инструкций. С добавлением SAD в SPU исполнение инструкции занимает один единственный такт, и, по словам AMD, это должно более чем в два раза убыстрить кодирование видео силами GPU. Несколько удручает, что SAD не является обязательной частью DirectX 11 или OpenCL, а это значит, что написанные под DX программы не могут вызывать ее, то же справедливо и для OpenCL, но для этого API хотя бы существует необходимая библиотека. С другой стороны, эти API не ограничивают жестко поведение GPU, поэтому динамический компилятор AMD может на лету распознать возможности оптимизаций (например – упомянутую выше цепь из 12 инструкций) и заменить необходимые части общего кода на более эффективные для данной конкретной архитектуры. То есть, даже если программист и не вызывал какие-либо нужные функции вручную, интеллектуальные алгоритмы смогут компенсировать это упущение самостоятельно. Так выглядит список инструкций, который блок SP Cypress может исполнять за один-единственный такт:
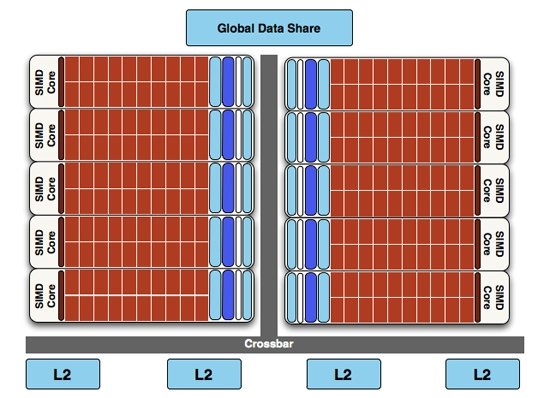
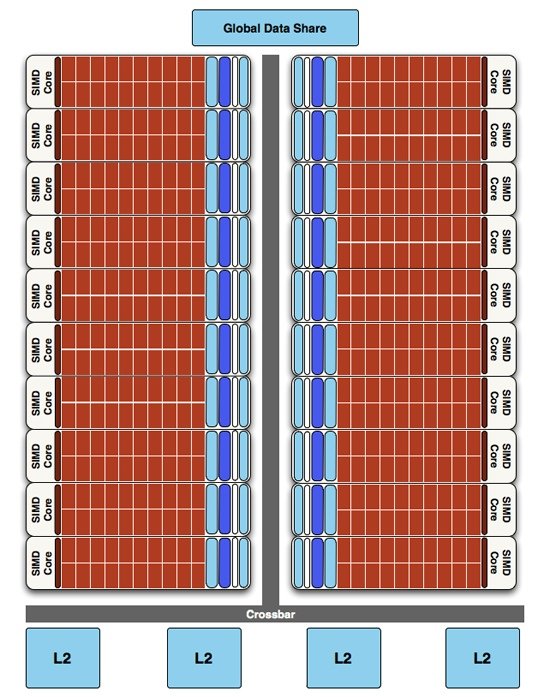
 Текстурные модули были также переработаны. Первое из внесенных изменений – добавленная возможность чтения сжатых AA цветовых буферов для более рационального использования пропускной способности. Второе – в AMD задались целью повысить скорость интерполяции, и реализовали это довольно интересным способом. Текстурные модули попросту лишили этой способности, перенеся ее в обязанности SP (это часть спецификаций DirectX 11). Это позволило значительно увеличить быстроту выполнения операций данного типа. Вследствие этого текстурные модули в Cypress имеют более высокую скорость закраски (филрейта), чем в RV770. Данное обстоятельство будет хорошо отражено в синтетических тестах. AMD утверждает, что чип способен в совокупности достигать показателя в 68 миллиардов билинейно отфильтрованных текселей в секунду, что является результатом переброски интерполяции на SP и проделанных оптимизаций для более рационального расходования пропускной способности. Наконец, снова делая шаг вверх по лестнице архитектурных уровней, мы добрались до основной причины превосходства в производительности RV870 над своим предшественником. AMD удвоила количество SIMD блоков с 10 до 20 штук. Это означает двукратное количественное превосходство по всему, начиная от SP и кончая текстурными модулями. Это довольно банальное изменение, в отличие от добавления новых низкоуровневых команд или переработки кэшей, зато наиболее действенное.  Естественно, для того, чтобы максимально эффективно загружать работой такое количество потоковых процессоров, были внесены и доработки в алгоритмы распределяющего диспетчера Ultra-Threaded Processor, 4 кэша L2 были удвоены с 64 до 128 Кб, причем одновременно с этим они получили ускорение в работе. Ранее они были связаны со сверхбыстрой памятью первого уровня на скорости до 384 Гб/с, теперь – 435 Гб/с. Наконец, общий буфер данных был увеличен в 4 раза, до 64 Кб. То есть, возвращаясь к нашему утверждению в начале статьи о необходимости расширения внутренних кэшей, мы видим, что AMD не только банально удвоила все исполнительные блоки и расширила их функциональность, но и позаботилась об отсутствии возможных узких мест.
Далее, для того, чтобы обработать все то, что рассчитывают SIMD процессоры, удвоили и ROP блоки. Это значит, что их число в Cypress возросло до 32 штук. Сами ROP также подверглись косметической переработке, в результате чего их производительность также несколько увеличилась. Теперь блоки растеризации способны проводить быструю цветовую очистку, согласно исследованиям AMD, многие игры сотни раз проводят такие операции между кадрами. Так же ROP ответственны и за некоторые этапы нового метода SSAA сглаживания, представленного ATI вместе с 5000 линейкой карт, но этого момента мы коснемся несколько позже. И, наконец, последнее усовершенствование по списку, но не по значимости – так называемый AMD Graphics Engine. 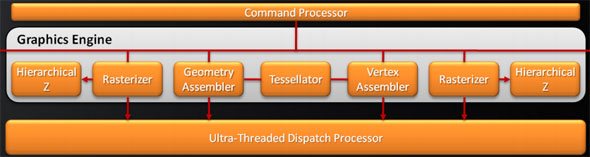 Блок аппаратной тесселяции появился еще в RV770, однако, несмотря на свои широкие возможности, разработчики игр практически не использовали его, обходя стороной. В DX11 появилось требования обязательного наличия такого блока в GPU, и имеющийся в RV770 был усовершенствован для соответствия спецификациям DX11. Причем если в RV770 такой модуль был один, для лучшего баланса и равномерности загрузки массива из 20 SIMD, в RV870 добавили второй. [N7-DirectX 11 Redux] С ранним выпуском 5800 серии AMD оказалась в довольно выигрышном положении. Компания предлагает пользователям графические решения с поддержкой DX11 на месяц раньше, чем станет доступен сам DirectX 11 с релизом Windows 7. NVIDIA же, углубившись в разработку своей новой архитектуры, в отношении внедрения возможностей DX11 в свои чипы довольно существенно отстала от ATI. Помимо очевидных маркетинговых преимуществ, Cypress впервые за долгое время стал стандартом де-факто для API Microsoft нового поколения. Ведь с ранним выходом чипа от AMD и отсутствием отлаженного и доведенного до ума конкурента от NVIDIA разработчики игр, желающие начать использование следующей версии библиотек DX уже сейчас, просто не имеют альтернативы. А, значит, игры будут разрабатываться в первую очередь с упором на архитектуру AMD, стремясь максимально полно задействовать ее возможности (а, как мы выяснили недавно, это не так просто), и стараться сглаживать недостатки. В прошлый раз ATI испытывала такой триумф только в 2002 году, когда Radeon 9700 PRO открыл эру DirectX 9; DX10 появился вместе с уникальной для своего времени унифицированной архитектурой G80, и долгое время NVIDIA доминировала из-за постоянных задержек и неудач канадской фирмы. Тем не менее, как и всегда, конечным пользователям не стоит судить о возможностях той или иной видеокарты по наличию поддержки API определенной версии. Во-первых, на данный момент пока нет даже каких-либо инструментов для оценки производительности RV870 в среде DirectX 11. Во-вторых, в первую очередь DirectX - это инструмент разработчика, и именно программист волен использовать те или иные инструменты, разработанные в Microsoft. Мы рассмотрим основные нововведения DX11 ниже. Стоить помнить, что DirectX 11 версии построен на базе DX10 (в то время как десятая модель API кардинально отличалась от своего предшественника), поэтому AMD не потребовалось проводить коренных изменений для трансформации видеоконвейера RV770 в то, что мы можем наблюдать в Cypress. 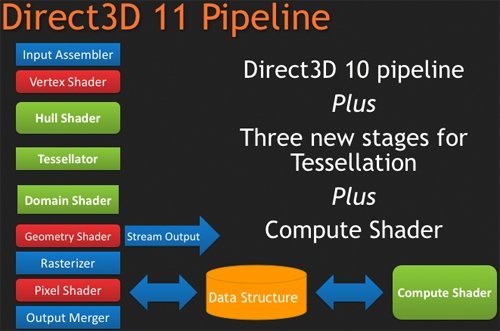 Наиболее значимыми нововведениями Direct3D стали система тесселяции, которая разбита на три этапа, и вычислительные шейдеры (Compur Shader). Первым делом на этапе подготовки к процессу тесселяции (после вершинных, до геометрических и пиксельных шейдеров) используются Hull Shader («скорлупка», из следующего абзаца будет легко понять, почему разработчики так назвали его). Этот тип шейдеров несет ответственность за выборку необходимых для формирования лоскутов модели и контрольных точек (направлений тесселяции). Затем в работу вступает отдельный аппаратный вычислительный блок высокого уровня сложности, в обязанности которого входит построение на базе изначальной геометрической модели и информации, просчитанной из Hull шейдеров, более сложной и детально проработанной структуры. Этот этап разработан для того, чтобы несколько разгрузить процесс формирования базовой геометрии сцены, когда излишняя проработка деталей требует огромной вычислительной мощности. С помощью процесса тесселяции в DX11 стало возможным без существенных затрат получить значительно более сложную модель объекта. Нет необходимости тратить дополнительные тысячи и десятки тысяч полигонов – с помощью Hull шейдеров отныне разработчик может создавать детальную модель, не нагружая GPU чрезмерно. Не стоит путать данную технологию с распространенными картами нормалей и бампмэппингом – хотя цель у этих разработок близка, алгоритмы различны, и, естественно, аппаратная тесселяция силами графического процессора – более прогрессивный, быстрый, и качественный вариант создания детализированных трехмерных объектов. Стоит отметить, что тесселятор не является непосредственно программируемым, он просто формирует новые поверхности на основании данных, которые поступают из шейдера с описанием точек «скорлупы». Тем не менее, фиксированный набор функций, который может быть рассчитан модулем, достаточно широк. После того, как сам процесс тесселяции завершен, результаты вычислений вместе с изначальными данными Hull шейдера попадают в Domain Shader, который, в свою очередь, уже производит все необходимые операции по совмещению и оценке полученных данных. Именно на этом этапе могут быть применены карты нормалей. Естественно, данное действие не является обязательным и приведено лишь в качестве примера. В зависимости от имеющихся инструкций, Domain шейдер может просто передать совокупные данные в обработку геометрическому шейдеру. Как вы видите, тесселяция является очень интересным способом получения более детализированной и, соответственно, реалистичной картинки. Тем не менее, использование этой функции целиком зависит от разработчика, ведь из конвейера D3D 11 версии эта стадия может быть вообще убрана, RV870 просто предоставляет аппаратную реализацию возможности стандарта, но никак не применяет тесселяцию в тех случаях, где это не предусмотрели программисты. Вообще, рассмотренная технология во многом появилась в DirectX 11 благодаря AMD. Первые версии блоков тесселяции компания ATI представляла еще в 2001 году, однако ни разу они не были оценены разработчиками по достоинству и не набрали популярность на PC (конечно, важная причина кроется и в отсутствии поддержки разработки у NVIDIA). Тесселятор, например, используется в Xbox 360, графический чип которого под кодовым названием Xenos разработан ATI, хотя его консольная реализация на порядок проще имеющейся сейчас в Cypress. В том же виде, в котором он присутствует в приставке Microsoft, тесселятор перешел в R600, но распространения, опять же, не получил. Но теперь, с введением стадий тесселяции в конвейер DX11, оба графических гиганта будут иметь чипы с поддержкой этой возможности, и, надеемся, со временем она будет применяться повсеместно. Принятие тесселяции на вооружение в DX11 – настоящая награда для AMD за длительные годы разработки этой возможности. Еще одно важнейшее нововведение в грядущем поколении Direct3D – вычислительные шейдеры. Они позволяют программам получать прямой доступ к математическим ресурсам GPU и работать с ним напрямую как с вычислительным, а не графическим процессором. Данный тип шейдеров может быть использован как в игровых приложениях, так и в программах любого другого типа, но во втором случае, когда эта возможность задействуется вне графического конвейера, обычно упоминается термин «прямых вычислений», DirectCompute, вместе вычислительных шейдеров. В любом случае, смысл от этого не меняется. А имеющиеся уже сейчас программы, использующие CUDA у NVIDIA и FireStream у ATI, показали, сколь огромным может быть ускорение от переноса вычислений некоторого типа с CPU на GPU (эта тенденция получила общее название GPGPU – General Purpose GPU, использование графических процессоров для вычислений общего типа). Безусловно, именно DirectX 11 (вместе с OpenCL) наконец-то сможет стать единым инструментом для проведения вычислений такого типа, однако в данный момент мы рассматриваем в первую очередь игровую видеокарту, и, как это ни странно, AMD предложила очень интересное применение, казалось бы, неуместным в обычной компьютерной игре вычислительным шейдерам. Речь идет об обсчете прозрачных текстур силами Compute Shader. Технология получила название Order Independent Transparency (внеочередная обработка прозрачности). Ее достоинство – возможность однопроходного рендеринга прозрачных поверхностей в оптимальном порядке. Хотя и раньше такой техникой пользовались, реализуя ее, например, средствами пиксельных шейдеров, с помощью вычислительных Compute Shader проделать необходимые операции можно будет существенно быстрее.  Естественно, поддержка тесселяции и нового типа вычислительных шейдеров – отнюдь не все, что отличает DirectX 11 от предшественника. В одиннадцатой версии API серьезные изменения претерпели стадии текстурирования Direct3D конвейера. Например, максимальный размер текстур был увеличен до 16K x 16K, то есть теперь могут быть использованы изображения вплоть до огромного разрешения в 256 Мп. На практике это означает, что DX11 позволяет работать с текстурами сколь угодно огромного размера – скорее закончится локальная видеопамять, чем будет достигнуто программное ограничение API. Также были добавлены две новых схемы сжатия текстур, BC6H и BC7. Как и в случае с добавлением тесселяции в конвейер D3D, их можно назвать детищем AMD. Дело в том, что эти алгоритмы компрессии были разработаны именно ATI, и затем включены в DX11 Microsoft. BC6H – первый в мире метод сжатия текстур, специально оптимизированный для HDR графики. Ранее для данных целей применялись менее эффективные BC3/DXT5. Он способен достигать впечатляющего соотношения компрессии 6:1 (с потерями качества). В то же время, BC7 теоретически должен стать заменой распространенным BC3/DXT5 в случае со стандартными RGB текстурами, он позволяет в три раза уменьшать размер изображений. Несмотря на то, что без реальных игр все эти теоретические рассуждения бесполезны, мы оцениваем значимость введение обязательной поддержки аппаратной тесселяции и новых методов сжатия текстур в DX11 очень высоко. Ведь фактически это серьезный толчок к росту качества графики компьютерных игр, на новый уровень выводятся как геометрическая, так и текстурная составляющие картинки. Тесселяция может без особых потерь производительности создавать более детализированные и проработанные 3D-модели, а новые технологии компрессии позволят натягивать на геометрический каркас текстуры более высокого разрешения и качества, не выходя за разумные пределы потребления видеопамяти. Мы надеялись представить в материале какие-либо скриншоты для сравнения изображения, полученного методами DX10 и DX11, но, к сожалению, найти достойные варианты вовремя не удалось. Тем не менее, по синтетическому бенчмарку, показанному Microsoft на GameFest 2008, можно верно оценить ценность нововведений. 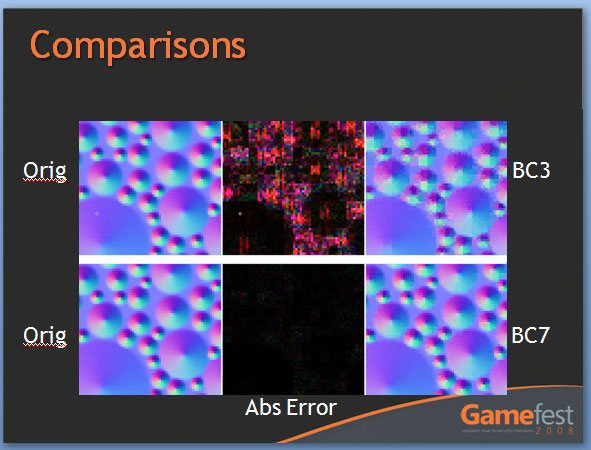 Переработке подвергся не только конвейер рендеринга Direct3D, еще одним значимым моментом DirectX 11 является улучшенная поддержка многопоточных вычислений. Отныне API поддерживает возможность получения указаний на создание ресурсов, управление состояниями или, скажем, принудительное завершения исполняемой команды от нескольких активных нитей. Ранее DX мог обрабатывать такой управляющий поток только в случае использования единственной нити. Эта оптимизация направлена на более рациональное использование ресурсов CPU, а значит, в ситуациях, когда производительность в графических приложениях будет упираться в видеокарту, мы сможем получить пусть небольшой, но заметный в критических ситуациях выигрыш в скорости. То есть это нововведение нацелено не на помощь самому CPU в случаях, когда его производительности не хватает, а именно на лучшее использование графической карты. Справедливости ради стоит отметить, что данная возможность не требует DX11 (может быть реализована с помощью специальной надстройки в DX10/10.1), однако впервые она будет представлена именно с DX11. Наконец, DirectX 11 вводит в обращение новый высокоуровневый язык шейдеров (High Level Shader Language) версии 5.0, в котором был добавлен ряд инструкций, сфокусированных на ускорении стандартных операций. Впервые появились классы и интерфейсы, которые позволят писать более структурированный и сегментированный код. Все это идет рука об руку с новыми алгоритмами интеллектуальных динамических связей шейдеров и их менеджмента. [N8-Первые игры DirectX 11] Каждый раз с выпуском новой версии DirectX и выхода карт, ее поддерживающих, встает вопрос о доступности игр для этой связки. Естественно, для разработки программных продуктов под очередной API, для начала требуется хотя бы иметь аппаратную платформу, соответствующую его требованиям. Это и служит логичным объяснением того, что какой бы «мягкой» ни была смена поколений DirectX, сначала на рынок выходит аппаратное обеспечение, и лишь затем игры. Не имея на руках видеокарт, девелоперы попросту не могут выпустить свои новинки одновременно с поступлением в продажу GPU. Вместе с выпуском Radeon HD 5800, AMD называет и первые игры с поддержкой новых технологий. Первая из них – Battleforge от Electronic Arts, карточная онлайн RTS. Изначально не планировалось, что игра и HD 5870 выйдут одновременно, однако EA и AMD смогли взять ситуацию под контроль и выпустить «сладкую парочку» одновременно. Таким образом, у AMD есть полное право утверждать, что существует DX11 игра, максимальное качество графики в которой может быть достигнуто с использованием только лишь аппаратного обеспечения ATI. Правда, похоже, что из всех нововведений DirectX 11 игра задействует только лишь High Definition Ambient Occlusion, но факт остается фактом.  Следующим большим тайтлом с DX11, на который AMD обращает внимание, является S.T.A.L.K.E.R.: Зов Припяти. Игра уже сейчас доступна на полках магазинов. К сожалению, точно неизвестно какие именно из нововведений DX11 использовали при разработке GSC Game World, однако Сталкер всегда был требователен к мощности PC, так что будет очень интересно в дальнейшем исследовать производительность карт нового поколения в этой игре. Еще одна игра, вокруг которой AMD старательно создавала ажиотаж на пресс-брифингах – DiRT 2. Эта аркадная гонка уже вышла на консолях, набрав немало положительных обзоров и высоких итоговых баллов, релиз на ПК намечен на 11 декабря. Задержка обусловлена именно доработкой графического движка и внедрением интересных функциональных возможностей. Так, DiRT 2, похоже, будет первой игрой, которая в полной мере использует основные возможности DX11, будь то тесселяция, более качественная фильтрация теней и т.д. Более того, игра даже поддерживает AMD Eyefinity (об этой технологии, позволяющей выводить изображение на связку из 6 мониторов, мы поговорим позже), так что фанатам инновационных решений и продвинутым геймерам определенно стоит подождать PC-версию игры и запастись при этом последними видеокартами AMD.  Наконец, Rebellion Games совместно с AMD недавно представила на суд общественности первые детали и подробности о своем проекте Aliens vs. Predator. Наверное, эта игра оказалась наиболее впечатляющей изо всех продемонстрированных, так как Rebellion показывали действите тесселяции и HDAO в реальном масштабе времени. К сожалению, скриншоты не передают всего шарма картинки, отличия наиболее заметны в движении. В любом случае, пока что продукт все еще находится на стадии разработки, и новую игру серии AvP не стоит ожидать раньше первого квартала следующего года.  Так, ни у AMD, ни у NVIDIA попросту нет готовой реализации OpenCL для Windows и Linux. NVIDIA реализовала OpenCL на своих картах восьмой серии и старше для Mac OS X 10.6 Snow Leopard, под той же ОС работают и платы 4800 семейства у AMD, но по понятным причинам провести тестирование HD 5870 на Mac не представляется возможным. По нашим сведениям, обе конкурирующие на графическом рынке компании разрабатывают OpenCL драйвера и модули для Windows. Уже сейчас существуют тестовые сборки, которые распространяются среди разработчиков, однако говорить о времени финального релиза пока рано. Стоит заметить, что даже текущие тестовые реализации OpenCL изначально разрабатывались под DX10 платформу, поэтому, скорее всего, после выхода первых реализаций OCL нас в скором времени ждут новые версии. Уже сейчас AMD говорит об OpenCL версии 1.1, которая должна использовать в полной мере возможности карт с поддержкой DirectX 11. Все это, по идее, не должно никак волновать конечного пользователя, однако такое положение вещей вряд ли приемлемо для разработчиков, а значит, реально работающий, эффективный и отлаженный софт появится еще не скоро. DirectCompute, напротив, находится в лучшей форме. NVIDIA уже сейчас поддерживает этот стандарт на своих DX10 картах, бета драйвера AMD, которые использовались в сегодняшнем тестировании, также реализуют DC на платах Radeon HD 5800. К сожалению, все DX10 GPU более ранних выпусков, будь то 2000, 3000 или 4000 серии, пока что обделены такой возможностью, однако AMD обещает внедрить для них полную поддержку DirectCompute в финальном Catalyst 9.10. Да и в целом уже сейчас ясно, что, несмотря на хорошую рекламу и раскрутку OpenCL, DirectX реализация DirectCompute более продуманна. Мы не будем предвосхищать события и делать необоснованные прогнозы, но, похоже, OpenCL останется более популярной именно на Mac OS, так как в этой UNIX-системе DirectCompute попросту отсутствует и альтернативы у Apple нет. У DC имеются и некоторые преимущества перед OCL. Например, четко выделено три уровня реализации стандарта – для DX10 (4.0), DX10.1 (4.1) и DX11 (5.0) графических карт. Чем выше версия, тем больше продвинутых возможностей доступно программистам. Хотя именно старший DirectCompute 5.0 является существенным шагом вперед по сравнению с предыдущими версиями, так как именно DX11 карты впервые разрабатывались именно с оглядкой на внедрение DirectCompute. Так, например, именно эта реализация языка впервые позволила работать с числами с плавающей запятой двойной точности и комбинированными операциями. В AMD считают, что разработчики в первую очередь должны ориентироваться именно на наиболее прогрессивный DirectCompute 5.0, но цель такого утверждения вполне ясна. Вполне естественно, что компания занимает такую позицию, при которой будут обеспечены максимальные продажи новых разработок. Тем не менее, как мы уже отметили, карты DX10/DX10.1 поколения не оставлены за бортом, и это однозначно радует. Ведь на данный момент доля DX11 решений ничтожно мала (всего две карты и доступны на рынке – HD 5870 и 5850), тогда как DX10 GPU широко распространены. Девелоперам было бы глупо отвергать DC 4.0, тем самым собственноручно сужая целевую группу потребителей ПО. Так что стоит ожидать первых программ для архитектуры DirectCompute именно четвертой версии. По мере развития рынка будет понятно, какой реальный выигрыш дают новые версии языка, и стоит ли игра свеч. Кстати говоря, ситуация с софтом для DirectCompute на данный момент полностью аналогична положению с DirectX 11 играми, которое будет позже в этом году. Разработки в этом направлении ведутся – так, Cyberlink уже показали за закрытыми дверьми новую версию PowerDirector, которая задействует мощности GPU, но сколько осталось ждать до выхода программы в свет, пока еще не ясно. Тем временем, для AMD продвижение прикладных программ DC, по сути, не столь важно, как DX11 игр, так что сроки появления последних более четко определены. Принимая во внимания тот факт, что DirectCompute – единственный реально работающий на железе обоих вендоров GPGPU API, мы попытались провести сравнительное тестирование. Несмотря на отсутствие системных программ для DC, в наличии у нас оказалось техническая демонстрация. К сожалению – производства NVIDIA. Естественно, в таких условиях нельзя назвать бенчмарк полностью честным, ведь демо полностью заточено под микроархитектуру чипов NV, однако вряд ли поклонники ATI будут разочарованны результатами новых Radeon.  Демонстрация рендеринга океана силами DirectCompute (задействованы быстрые преобразования Фурье) запускается на GPU. Расчеты генерируют направления волн и являются хорошо распараллеливаемой математической нагрузкой. Программа написана на DirectCompute 4.0, так как предназначена для запуска на DX10 картах NVIDIA. Вопреки опасениям, никаких проблем с запуском демонстрации производства NVIDIA на Radeon HD 5870 не возникло, причем, несмотря на игру «не на своем поле», карта легко превзошла GTX 285. Странную картину мы могли наблюдать с многочиповыми конфигурациями – тогда как SLI/Crossfire достаточно хорошо масштабировались, GTX 295 оказалась медленнее GTX 285. Так как это просто техническая демонстрация, не стоит делать скоропостижных выводов; скорее мы просто проверили реальную работоспособность DirectCompute на серии 5800. Интересно, что на презентации видеокарт AMD продемонстрировали свою разработку в области GPGPU – симуляцию реалистичной физической модели с использованием портированной на DC бесплатной библиотеки Bullet Physics. Хотя вряд ли компания признает этот факт, но, похоже, AMD надоело находиться в позиции отстающего на поле конкуренции с NVIDIA PhysX, а Bullet Physics – демонстрация того, что Radeon также может успешно обсчитывать физику. Тем не менее, мы не считаем, что технология пойдет дальше пресс-брифингов ATI. Слишком малая распространенность библиотеки у разработчиков и проблемы, с которыми столкнулась NVIDIA при внедрении PhysX (нежелание использовать какие-либо другие движки физики в играх кроме Havok), - все это говорит о том, что вряд ли физика силами GPGPU изменится в ближайшее время. Похоже, только приход сторонней коммерческой разработки, заточенной под DirectCompute или OpenCL, которую разработчики смогут лицензировать для своих игр, сможет изменить ситуацию. Причем совершенно неважно, будет ли это следующее поколение Havok, или же в игру включится новая сторона. Наконец, вспомним и о старых разработках компании, касающихся вычислений силами GPU. Сегодня AMD целиком и полностью нацелилась на поддержку DirectCompute и OpenCL, оставляя за бортом имеющиеся наработки. Среди них и высокоуровневый язык программирования Brook+, который в недавнем прошлом был выложен на Sourceforge в качестве открытого проекта. Compute Abstract Layer (CAL), на котором по сути базируется реализация OpenCL AMD, хотя и не брошен на произвол судьбы, но застыл в своем развитии на версии 1.4; корпорация всячески приветствует переход с CAL на OpenCL, хотя поклонники High Performance Computing (HPC) продолжают использовать возможности FireStream для того, что бы выжать максимум возможностей из имеющихся карт. [N10-Eyefinity] Приблизительно в 2006-2007 годах ATI начала разрабатывать спецификации технологии, которой было суждено появиться в серийном варианте лишь сейчас в RV870. В данном случае речь идет уже не о многострадальном аппаратном блоке тесселяции, а об Eyefinity. При проектировании GPU, компании производители ориентируются не только на свое видение конечного продукта, но и учитывают пожелания разработчиков программного обеспечения, крупных OEM заказчиков, а иногда даже и разумные предложения простых пользователей. В случае с Eyefinity предпосылки к ее созданию появились после анализа потребностей OEM сегмента. Дело в том, что дискретным мобильным графическим чипам оказалось нужно большое количество видеовыводов, вплоть до шести штук. Хотя одновременно активными могли быть только два. Производители запрашивали такую схему подключения, при которой пара выходов использовалась бы для самих панелей ноутбука (уже сейчас некоторые производители экспериментируют с такими нестандартными устройствами), пара (один DisplayPort и, например, один DVI/VGA/HDMI) имелась для подключения внешних дисплеев, и еще пара выводилась бы на докстанцию. Опять же, одновременно задействованы должны быть только два, поэтому в GPU требовалось создать только лишь шесть выводных каналов, но нужды таком количестве полноценных цепей со своими RAMDAC и т.п. модулями не было. Но AMD решила не принимать половинчатых решений, и заложила в RV870 возможности одновременного вывода изображения на шесть экранов! Конечно, не все исполнения карт реализуют эту возможность, например, на референсе, уже описанном нами выше, попросту физически недостаточно видеовыходов для подключения шести дисплеев. Однако несколько позже в этом году ATI представит карту, на которой будет размещена шестерка mini-DisplayPort для подключения до шести мониторов.  Нетрудно догадаться, что для такой сложной технологии нужна не только аппаратная, но и программная поддержка. Об этом в AMD так же позаботились. Как хорошо видно по фотографии, при использовании плат серии Radeon HD 5000 допускается объединение до шести мониторов в один так, чтобы ОС и игры воспринимали бы конструкцию как один дисплей с огромным разрешением. Для своих тестов Eyefinity мы использовали группу из 24” мониторов Dell U2410s. Их недостаток – лишь в высокой цене. При стоимости порядка 600 евро становится неочевидным смысл создания такой связки. Ведь по задумке AMD Eyefinity должна дать возможность подключения нескольких дешевых Full HD панелей, которые в совокупности будут стоить сравнимо с одним 30” дисплеем, но обеспечивать лучшее погружение в игровую вселенную. Чтобы проверить универсальность Eyefinity, для подключения мониторов Dell мы задействовали все доступные типы выходов на имеющемся в наличии HD 5870: один DVI, один HDMI и один DisplayPort.  При запуске Windows с тремя подключенными мониторами изображение, согласно заводским настройкам, дублируется. Правильное конфигурирование может быть произведено из панели управления ATI Catalyst Control Center в пункте группировке экранов: 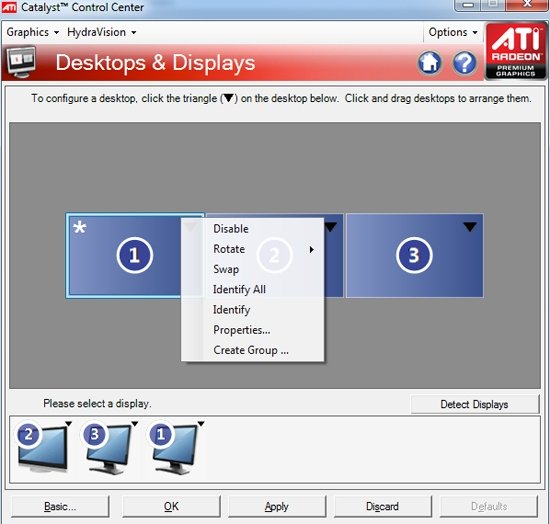 С тремя дисплеями в драйвере были доступны две схемы подключения – 1x3 и 3x1, которые позволили задействовать экраны как в горизонтальном, так и в вертикальном режимах. Конечно, можно выбрать и меньшее количество мониторов для группы, но мы хотели использовать предоставленные возможности по максимуму.  Следующим шагом станет определение относительного положения экранов. Драйвер предложит вариант с автоматическим распределением изображений по мониторам. 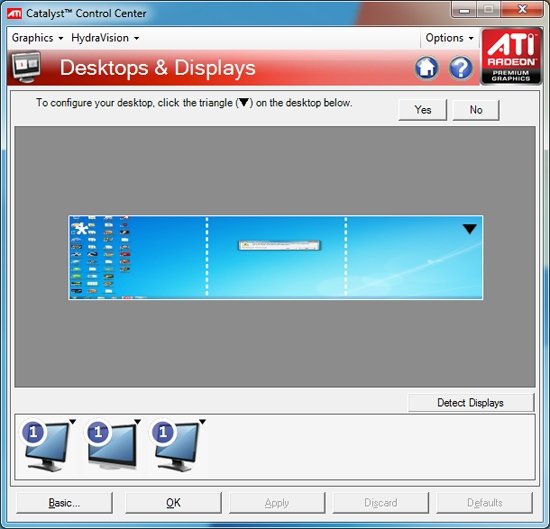 В случае, если предположение окажется неправильным, допустима и ручная перенастройка.  После того, как программная составляющая Eyefinity настроена, в Windows и программах/играх становится доступен вывод на дисплей с огромным разрешением (в нашем случае – 5760x1200), Single Large Surface в терминологии ATI, который и является группой, созданной ранее в CCC.  Нетрудно догадаться, что, как и у любой новинки, тем более такого высокого уровня сложности, у Eyefinity есть проблемы. Первую, и самую главную из них, вы могли наблюдать на предыдущем скриншоте – соотношение сторон. В то время как рабочий стол Windows физически увеличивается в размерах настолько, чтобы занять всю площадь трех мониторов, в некоторых играх картинка попросту растягивается для соответствия высокому разрешению. Так, в Batman Arkham Asylum выбор Single Large Surface был доступен, однако при рендеринге движок игры вместо того, что бы рисовать изображение в честном 5760x1600, попросту сжимал до него 5760x3240 (16:9). Естественно, происходило совершенно ужасное изменение пропорций всех игровых объектов, так что с тремя мониторами играть оказалось совершенно невозможно. Зато после увиденного небольшие искажения, происходящие при растяжении формата 16:9 на 16:10 перестали так бросаться в глаза.
В других играх вылезали проблемы иного рода. Хотя Resident Evil 5 корректно определял разрешение, даже сжатия с неправильными пропорциями до площади дисплеев, как в Batman AA, не происходило. Иными словами, игра не придавала особого значения тому, что имеющиеся мониторы не могут выводить картинку в 16:9, и показывала только нижнюю часть полного изображения от 5760x3240 на 5760x1200. Забавно, что в таком режиме даже оказалось не видно главное меню игры, что уж говорить о возможности игры. Кроме того, в случае с предварительно записанными роликами на движке игры, которые не были предназначены для таких высоких разрешений, или же двухмерными статичными изображениями вроде меню или деталей интерфейса, также возникают проблемы. Они не желают даже растягиватьс |
||||
Источник: www.anandtech.com/