Каталог
DirectCompute, OpenCL и будущее CALКак бы ни были интересны GPGPU вычисления, это одна из самых сложных для описания возможностей современных карт. Теоретически вычисления на GPU могут стать новой вехой развития ПК и даже привести в будущем к интеграции CPU и GPU, однако на данном этапе все плюсы технологии сложно ощутить на практике. На данный момент для этих целей у AMD и NVIDIA существуют несовместимые друг с другом API. Хотя OpenCL и DirectCompute изменят сложившийся порядок вещей, обновленное программное обеспечение подоспеет еще нескоро. Так, ни у AMD, ни у NVIDIA попросту нет готовой реализации OpenCL для Windows и Linux. NVIDIA реализовала OpenCL на своих картах восьмой серии и старше для Mac OS X 10.6 Snow Leopard, под той же ОС работают и платы 4800 семейства у AMD, но по понятным причинам провести тестирование HD 5870 на Mac не представляется возможным. По нашим сведениям, обе конкурирующие на графическом рынке компании разрабатывают OpenCL драйвера и модули для Windows. Уже сейчас существуют тестовые сборки, которые распространяются среди разработчиков, однако говорить о времени финального релиза пока рано. Стоит заметить, что даже текущие тестовые реализации OpenCL изначально разрабатывались под DX10 платформу, поэтому, скорее всего, после выхода первых реализаций OCL нас в скором времени ждут новые версии. Уже сейчас AMD говорит об OpenCL версии 1.1, которая должна использовать в полной мере возможности карт с поддержкой DirectX 11. Все это, по идее, не должно никак волновать конечного пользователя, однако такое положение вещей вряд ли приемлемо для разработчиков, а значит, реально работающий, эффективный и отлаженный софт появится еще не скоро. DirectCompute, напротив, находится в лучшей форме. NVIDIA уже сейчас поддерживает этот стандарт на своих DX10 картах, бета драйвера AMD, которые использовались в сегодняшнем тестировании, также реализуют DC на платах Radeon HD 5800. К сожалению, все DX10 GPU более ранних выпусков, будь то 2000, 3000 или 4000 серии, пока что обделены такой возможностью, однако AMD обещает внедрить для них полную поддержку DirectCompute в финальном Catalyst 9.10. Да и в целом уже сейчас ясно, что, несмотря на хорошую рекламу и раскрутку OpenCL, DirectX реализация DirectCompute более продуманна. Мы не будем предвосхищать события и делать необоснованные прогнозы, но, похоже, OpenCL останется более популярной именно на Mac OS, так как в этой UNIX-системе DirectCompute попросту отсутствует и альтернативы у Apple нет. У DC имеются и некоторые преимущества перед OCL. Например, четко выделено три уровня реализации стандарта – для DX10 (4.0), DX10.1 (4.1) и DX11 (5.0) графических карт. Чем выше версия, тем больше продвинутых возможностей доступно программистам. Хотя именно старший DirectCompute 5.0 является существенным шагом вперед по сравнению с предыдущими версиями, так как именно DX11 карты впервые разрабатывались именно с оглядкой на внедрение DirectCompute. Так, например, именно эта реализация языка впервые позволила работать с числами с плавающей запятой двойной точности и комбинированными операциями. В AMD считают, что разработчики в первую очередь должны ориентироваться именно на наиболее прогрессивный DirectCompute 5.0, но цель такого утверждения вполне ясна. Вполне естественно, что компания занимает такую позицию, при которой будут обеспечены максимальные продажи новых разработок. Тем не менее, как мы уже отметили, карты DX10/DX10.1 поколения не оставлены за бортом, и это однозначно радует. Ведь на данный момент доля DX11 решений ничтожно мала (всего две карты и доступны на рынке – HD 5870 и 5850), тогда как DX10 GPU широко распространены. Девелоперам было бы глупо отвергать DC 4.0, тем самым собственноручно сужая целевую группу потребителей ПО. Так что стоит ожидать первых программ для архитектуры DirectCompute именно четвертой версии. По мере развития рынка будет понятно, какой реальный выигрыш дают новые версии языка, и стоит ли игра свеч. Кстати говоря, ситуация с софтом для DirectCompute на данный момент полностью аналогична положению с DirectX 11 играми, которое будет позже в этом году. Разработки в этом направлении ведутся – так, Cyberlink уже показали за закрытыми дверьми новую версию PowerDirector, которая задействует мощности GPU, но сколько осталось ждать до выхода программы в свет, пока еще не ясно. Тем временем, для AMD продвижение прикладных программ DC, по сути, не столь важно, как DX11 игр, так что сроки появления последних более четко определены. Принимая во внимания тот факт, что DirectCompute – единственный реально работающий на железе обоих вендоров GPGPU API, мы попытались провести сравнительное тестирование. Несмотря на отсутствие системных программ для DC, в наличии у нас оказалось техническая демонстрация. К сожалению – производства NVIDIA. Естественно, в таких условиях нельзя назвать бенчмарк полностью честным, ведь демо полностью заточено под микроархитектуру чипов NV, однако вряд ли поклонники ATI будут разочарованны результатами новых Radeon.  Демонстрация рендеринга океана силами DirectCompute (задействованы быстрые преобразования Фурье) запускается на GPU. Расчеты генерируют направления волн и являются хорошо распараллеливаемой математической нагрузкой. Программа написана на DirectCompute 4.0, так как предназначена для запуска на DX10 картах NVIDIA. Вопреки опасениям, никаких проблем с запуском демонстрации производства NVIDIA на Radeon HD 5870 не возникло, причем, несмотря на игру «не на своем поле», карта легко превзошла GTX 285. Странную картину мы могли наблюдать с многочиповыми конфигурациями – тогда как SLI/Crossfire достаточно хорошо масштабировались, GTX 295 оказалась медленнее GTX 285. Так как это просто техническая демонстрация, не стоит делать скоропостижных выводов; скорее мы просто проверили реальную работоспособность DirectCompute на серии 5800. Интересно, что на презентации видеокарт AMD продемонстрировали свою разработку в области GPGPU – симуляцию реалистичной физической модели с использованием портированной на DC бесплатной библиотеки Bullet Physics. Хотя вряд ли компания признает этот факт, но, похоже, AMD надоело находиться в позиции отстающего на поле конкуренции с NVIDIA PhysX, а Bullet Physics – демонстрация того, что Radeon также может успешно обсчитывать физику. Тем не менее, мы не считаем, что технология пойдет дальше пресс-брифингов ATI. Слишком малая распространенность библиотеки у разработчиков и проблемы, с которыми столкнулась NVIDIA при внедрении PhysX (нежелание использовать какие-либо другие движки физики в играх кроме Havok), - все это говорит о том, что вряд ли физика силами GPGPU изменится в ближайшее время. Похоже, только приход сторонней коммерческой разработки, заточенной под DirectCompute или OpenCL, которую разработчики смогут лицензировать для своих игр, сможет изменить ситуацию. Причем совершенно неважно, будет ли это следующее поколение Havok, или же в игру включится новая сторона. Наконец, вспомним и о старых разработках компании, касающихся вычислений силами GPU. Сегодня AMD целиком и полностью нацелилась на поддержку DirectCompute и OpenCL, оставляя за бортом имеющиеся наработки. Среди них и высокоуровневый язык программирования Brook+, который в недавнем прошлом был выложен на Sourceforge в качестве открытого проекта. Compute Abstract Layer (CAL), на котором по сути базируется реализация OpenCL AMD, хотя и не брошен на произвол судьбы, но застыл в своем развитии на версии 1.4; корпорация всячески приветствует переход с CAL на OpenCL, хотя поклонники High Performance Computing (HPC) продолжают использовать возможности FireStream для того, что бы выжать максимум возможностей из имеющихся карт. [N10-Eyefinity] Приблизительно в 2006-2007 годах ATI начала разрабатывать спецификации технологии, которой было суждено появиться в серийном варианте лишь сейчас в RV870. В данном случае речь идет уже не о многострадальном аппаратном блоке тесселяции, а об Eyefinity. При проектировании GPU, компании производители ориентируются не только на свое видение конечного продукта, но и учитывают пожелания разработчиков программного обеспечения, крупных OEM заказчиков, а иногда даже и разумные предложения простых пользователей. В случае с Eyefinity предпосылки к ее созданию появились после анализа потребностей OEM сегмента. Дело в том, что дискретным мобильным графическим чипам оказалось нужно большое количество видеовыводов, вплоть до шести штук. Хотя одновременно активными могли быть только два. Производители запрашивали такую схему подключения, при которой пара выходов использовалась бы для самих панелей ноутбука (уже сейчас некоторые производители экспериментируют с такими нестандартными устройствами), пара (один DisplayPort и, например, один DVI/VGA/HDMI) имелась для подключения внешних дисплеев, и еще пара выводилась бы на докстанцию. Опять же, одновременно задействованы должны быть только два, поэтому в GPU требовалось создать только лишь шесть выводных каналов, но нужды таком количестве полноценных цепей со своими RAMDAC и т.п. модулями не было. Но AMD решила не принимать половинчатых решений, и заложила в RV870 возможности одновременного вывода изображения на шесть экранов! Конечно, не все исполнения карт реализуют эту возможность, например, на референсе, уже описанном нами выше, попросту физически недостаточно видеовыходов для подключения шести дисплеев. Однако несколько позже в этом году ATI представит карту, на которой будет размещена шестерка mini-DisplayPort для подключения до шести мониторов.  Нетрудно догадаться, что для такой сложной технологии нужна не только аппаратная, но и программная поддержка. Об этом в AMD так же позаботились. Как хорошо видно по фотографии, при использовании плат серии Radeon HD 5000 допускается объединение до шести мониторов в один так, чтобы ОС и игры воспринимали бы конструкцию как один дисплей с огромным разрешением. Для своих тестов Eyefinity мы использовали группу из 24” мониторов Dell U2410s. Их недостаток – лишь в высокой цене. При стоимости порядка 600 евро становится неочевидным смысл создания такой связки. Ведь по задумке AMD Eyefinity должна дать возможность подключения нескольких дешевых Full HD панелей, которые в совокупности будут стоить сравнимо с одним 30” дисплеем, но обеспечивать лучшее погружение в игровую вселенную. Чтобы проверить универсальность Eyefinity, для подключения мониторов Dell мы задействовали все доступные типы выходов на имеющемся в наличии HD 5870: один DVI, один HDMI и один DisplayPort.  При запуске Windows с тремя подключенными мониторами изображение, согласно заводским настройкам, дублируется. Правильное конфигурирование может быть произведено из панели управления ATI Catalyst Control Center в пункте группировке экранов: 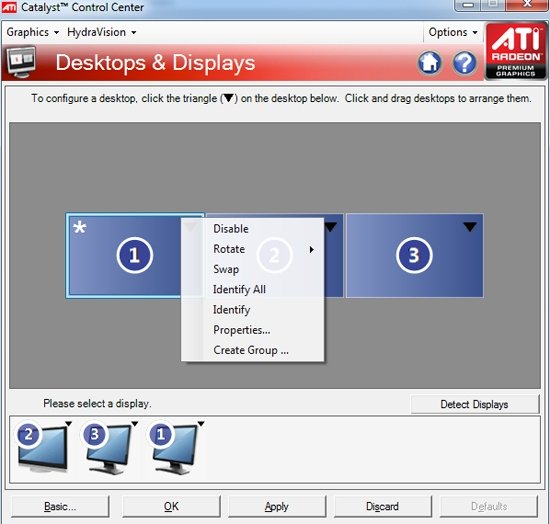 С тремя дисплеями в драйвере были доступны две схемы подключения – 1x3 и 3x1, которые позволили задействовать экраны как в горизонтальном, так и в вертикальном режимах. Конечно, можно выбрать и меньшее количество мониторов для группы, но мы хотели использовать предоставленные возможности по максимуму.  Следующим шагом станет определение относительного положения экранов. Драйвер предложит вариант с автоматическим распределением изображений по мониторам. 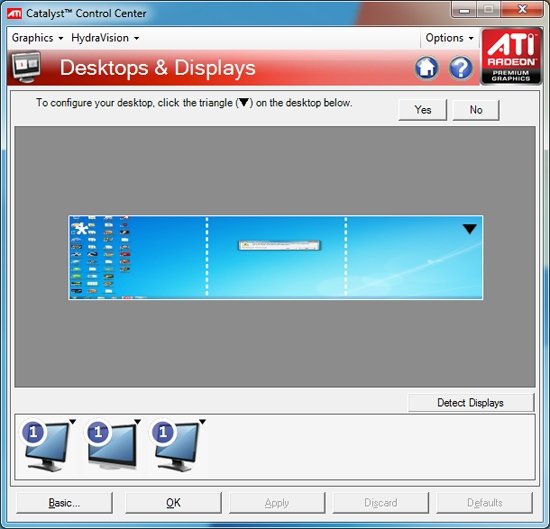 В случае, если предположение окажется неправильным, допустима и ручная перенастройка.  После того, как программная составляющая Eyefinity настроена, в Windows и программах/играх становится доступен вывод на дисплей с огромным разрешением (в нашем случае – 5760x1200), Single Large Surface в терминологии ATI, который и является группой, созданной ранее в CCC.  Нетрудно догадаться, что, как и у любой новинки, тем более такого высокого уровня сложности, у Eyefinity есть проблемы. Первую, и самую главную из них, вы могли наблюдать на предыдущем скриншоте – соотношение сторон. В то время как рабочий стол Windows физически увеличивается в размерах настолько, чтобы занять всю площадь трех мониторов, в некоторых играх картинка попросту растягивается для соответствия высокому разрешению. Так, в Batman Arkham Asylum выбор Single Large Surface был доступен, однако при рендеринге движок игры вместо того, что бы рисовать изображение в честном 5760x1600, попросту сжимал до него 5760x3240 (16:9). Естественно, происходило совершенно ужасное изменение пропорций всех игровых объектов, так что с тремя мониторами играть оказалось совершенно невозможно. Зато после увиденного небольшие искажения, происходящие при растяжении формата 16:9 на 16:10 перестали так бросаться в глаза.
В других играх вылезали проблемы иного рода. Хотя Resident Evil 5 корректно определял разрешение, даже сжатия с неправильными пропорциями до площади дисплеев, как в Batman AA, не происходило. Иными словами, игра не придавала особого значения тому, что имеющиеся мониторы не могут выводить картинку в 16:9, и показывала только нижнюю часть полного изображения от 5760x3240 на 5760x1200. Забавно, что в таком режиме даже оказалось не видно главное меню игры, что уж говорить о возможности игры. Кроме того, в случае с предварительно записанными роликами на движке игры, которые не были предназначены для таких высоких разрешений, или же двухмерными статичными изображениями вроде меню или деталей интерфейса, также возникают проблемы. Они не желают даже растягиваться на полную площадь экранов:  Наконец, хотя много игровых приложений работает с Eyefinity абсолютно корректно, есть и некоторые нюансы. Так, в Windows конфигурация из трех мониторов попросту некомфортна. Оптимально было бы, чтобы при переходе на рабочий стол, боковые экраны попросту отключались, и картинка концентрировалась на центральном дисплее в стандартном разрешении 1920x1200. Однако этого не происходит, из-за чего для того, чтобы взглянуть на время в трее необходимо повернуть голову направо, а чтобы запустить необходимую программу из меню Пуск, - налево. Конечно, мы несколько утрируем, но, например, набирать текст в Word или серфить по интернету на трех мониторах, которые отображают единое рабочее поле, неудобно. К тому же огромная ширина панелей отвлекает и в некоторых играх, где сервисные элементы HUD разнесены по углам (например, в Oblivion шкалы здоровья, маны и выносливости располагаются внизу слева).  Но не все так плохо, как могло показаться. Например, одной из самых больших проблем с Eyefinity могли бы стать толстые рамки дисплеев. Зачастую даже при использовании одного единственного монитора толстая рамка отвлекает от просмотра, непроизвольно захватывает внимание так же, как и битые пиксели на матрице. В случае с Dell U2410s размер окантовки оказался критичным только в портретном режиме. А, надо заметить, у этого монитора не самая тонкая рамка. Конечно, передать словами или на фото верные ощущения не получится, но, поверьте на слово, когда Eyefinity работает корректно (точнее – игры поддерживают вывод на дисплей большого разрешения и нестандартного соотношения сторон), погружение в игровой мир совершенно потрясающее. Примером такой игры может стать вездесущий World of Warcraft. Blizzard позаботилась о том, чтобы движок игры был способен выводить изображение такого размера, как позволяют экраны. То есть в WoW попросту расширяется угол обзора (прямо как увеличивается рабочий стол в Windows). Никаких диспропорций, растяжений или смещений. Игра выглядит просто сногсшибательно, когда два боковых монитора немного повернуты под углом так, чтобы их захватывало боковое зрение. Конечно, нечестно будет сказать, что можно в буквальном смысле видеть все вокруг себя, но банальная пробежка по пшеничному полю выглядит и чувствуется действительно реалистично. Что уж говорить о масштабном сражении, когда действо и на стандартном экране впечатляет, а на связке из трех мониторов в Eyefinity просто гипнотически притягивает. Действительно, при должной поддержке Eyefinity творит чудеса; остается только догадываться, как может впечатлить картинка на шести мониторах с большой диагональю и высоким разрешением. Перед тем, как мы испробовали Eyefinity самостоятельно, отношение к технологии было очень скептическое. Существовало слишком много «но» - толстые рамки у мониторов, бессмысленность самой идеи объединения нескольких мониторов. Тестирование полностью опровергло эти два пункта, технология показала свою состоятельность. Обеспеченным фанатам игр однозначно стоит присмотреться к возможностям, которые открываются с RV870. Тем не менее, проблем у Eyefinity также хватает. Без изменения конфигурационных файлов и применения неофициальных патчей лишь одна из четырех опробованных игр адекватно восприняла объединенный дисплей большого разрешения и смогла его корректно использовать. Также не совсем понятно, как поведет себя Eyefinity в Crossfire (ведь предыдущие реализации многочиповых GPU от AMD и NVIDIA не совсем корректно работали с несколькими дисплеями). Тем не менее, однозначно радует тот факт, что мощности одного Radeon HD 5870 хватает, чтобы даже на максимальных настройках обеспечивать вполне приемлемый фреймрейт в 5760x1200. Так, World of Warcraft был абсолютно играбелен с 48 FPS, а Batman Arkham Asylum показал отличные 66 кадров в секунду. [N11-Гонка окончена: 8-канальный LPCM, битстримминг TrueHD & DTS-HD MA] Более полугода минуло с момента, когда мы рассматривали довольно плачевную ситуацию с HD звуком с Blu-ray на ПК. Речь идет не столько о музыкальных дисках, сколько о высококачественных многоканальных дорожках для фильмов. Всю ту статью немалых размеров можно свести к одному утверждению: без дорогостоящей звуковой карты вывести сжатые Dolby TrueHD или DTS-HD Master Audio с HTPC на A/V ресивер или препроцессор домашнего кинотеатра попросту невозможно. Благодаря первым подвижкам, совершенным AMD на поле интегрированных чипсетов, сначала Intel, а чуть позже и NVIDIA решили данную проблему так, что HTPC, построенный на базе правильных IGP/GPU компонентов, самостоятельно декодировал бы аудиопотоки и пересылал их в уже разжатом виде по HDMI. Эта функция получила название восьмиканального LPCM звука, и сэкономила фанатам ДК и высококачественного звука $150-$250, которые ранее требовалось бы потратить на дорогостоящую звуковую карту вроде Auzentech HomeTheater HD или ASUS Xonar HDAV 1.3. Некоторое время назад появились неприятные слухи, что из-за стремления к снижению себестоимости ATI собирается отказаться от 8-канального LPCM в RV870. К нашей большой радости эти слухи не подтвердились. Radeon HD 5870, как и его предшественник, способен не только выводить восьмиканальный LPCM звук по HDMI, более того, Cypress обрел и новую функцию – теперь чип умеет передавать битстриммингом (прямая передача сжатого потока без декодирования силами ПК) Dolby TrueHD и DTS-HD MA! Это первая и пока что единственная видеокарта на рынке с такой возможностью. Хотя, скорее всего, в следующем году сходной функциональностью будут оснащены и конкурирующие решения от NVIDIA. Конечно, в первую очередь Radeon HD 5870 это игровая видеокарта, и если вы не стремитесь создать многоцелевой HTPC (на котором, скажем, будете помимо просмотра видео еще и ставить рекорды в NFS Shift), его мощность будет излишней. Хотя энергопотребление видеокарты в покое и мало, вряд ли ее стоимость будет оправдана без игрового применения. Так что, если время терпит, мы рекомендуем дождаться упрощенных версий RV870 с меньшим количеством функциональных блоков. Ведь их мультимедийная составляющая, как и в 4000 поколении Radeon HD, не будет урезана относительно старшей карты. Встроенный блок обработки видео ATI UVD2 (Universal Video Decoder) также никуда не делся из RV870. Он, как и раньше, поддерживает полноценное аппаратное декодирование H.264, MPEG-2 и VC1. Особых изменений по функциональности модуль не претерпел, доступны все те же фильтры и режимы для двух одновременных 1080p потоков. Из положительных моментов – UVD2 теперь функционирует в Aero режиме Windows Vista/7 (ранее при активации UVD тема оформления переключалась на базовый режим), однако это скорее софтовая доработка. Естественно, чтобы задействовать новые аппаратные возможности Radeon HD 5870, необходима и соответствующая программа-плеер. Один из самых продвинутых комбайнов Cyberlink PowerDVD 9 уже обучен работе с битстриммингом RV870. Пока что для конечных пользователей эта версия не доступна, но среди журналистов предрелизные сборки уже распространены. Для того, чтобы задействовать вывод сжатого звука напрямую на ресивер, в опциях программы следует выбрать пункт «Non-decoded high-definition audio to external device»: 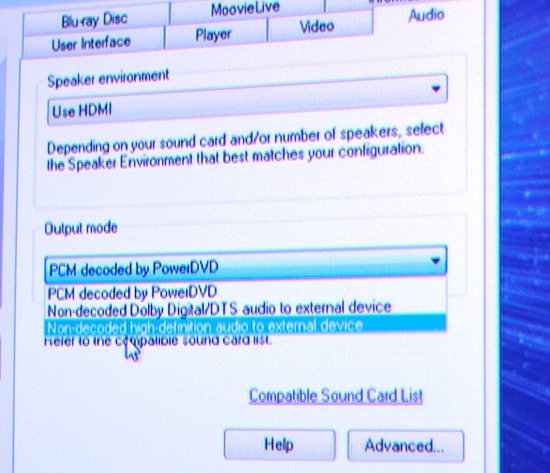 Этого достаточно, чтобы плеер не предпринимал никаких попыток для декодирования аудио, а просто передавал сжатый поток с диска через HDMI на ресивер. Данная функция была протестирована в паре с Integra DTC-9.8 и Blu-ray мультфильмом Вольт, звук в котором сжат по алгоритмам DTS-HD MA. К нашему искреннему удивлению, все заработало с первого раза, без каких бы то ни было проблем: 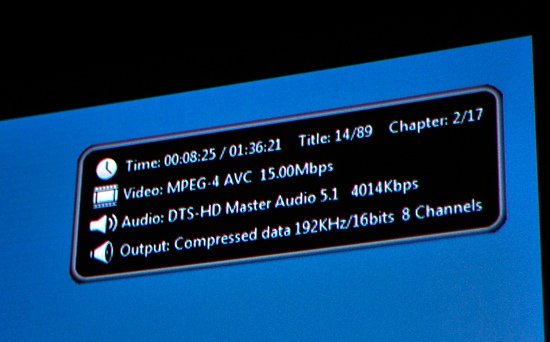 Никаких ошибок с HDCP, никакого странного поведения плеера – все было просто идеально.  Затем пришел черед проверки Dolby TrueHD. Для этого был использован диск American History X. К сожалению, все прошло не так гладко, как с DTS-HD. ПК отдавал только лишь обычный Dolby Digital. То же самое наблюдалось и с Трансформерами. Оказалось, что описанный баг присущ бетаверсии проигрывателя PowerDVD. Пара переключений режима аудиовыхода решила проблему. Cyberlink обещает, что в финальной версии никаких проблем с Dolby TrueHD наблюдаться не будет, и шаманства не потребуется. В любом случае, даже с ранней версией проигрывателя нам потребовалось лишь немного времени, чтобы заставить корректно выводить с Radeon HD 5870 на ресивер как DTS-HD MA, так и Dolby TrueHD:
Безусловно, тот факт, что наконец-то появилась видеокарта с полноценной поддержкой Protected Audio Path, не может не радовать. Скорее всего, в ближайшем будущем такой возможностью будут наделены как большинство дискретных, так и интегрированных графических карт. Но, в любом случае, RV870 останется первопроходцем в данной области. Отрадно, что не только в части архитектуры SIMD блоков и SPU/SP процессоров, но и в дополнительных возможностях Cypress является 100% преемником RV770, который в свое время впервые для дискретных карт предложил решение проблемы вывода высококачественного 8-канального HD звука с Blu-ray по LPCM. [N12-Сниженное энергопотребление в покое и лучшая защита от повышенной энергетической нагрузки] Одним из параметров, которому AMD уделяла особое внимание при разработке RV870, было энергопотребление. Под нагрузкой величина в 160 Вт, достигаемая HD 4870, находилась в разумных рамках. Безусловно, это немалая цифра, однако для уровня производительности 55 нм RV770 – более чем адекватная. Проблема крылась в другом – именно в состоянии покоя карта потребляла чрезмерно много энергии, порядка 90 Вт. Благодаря новой версии BIOS удалось скинуть еще несколько Ватт, однако о кардинальных переменах говорить не приходилось. Даже RV790 с измененной PCB был слишком горяч без нагрузки, потребляя примерно 60 Вт. Как следствие, в Cypress изначально закладывали конструктивные идеи, с реализацией которых энергопотребление карт 5000 серии Radeon было бы существенно ниже, чем у HD 4000. Цель, к которой стремились в ATI, - не более 30 Вт без нагрузки, треть от необходимой RV770 мощности. В конце концов удалось даже превзойти желанную цифру на 10% и добиться 27 Вт в покое для полноценного RV870 в полноценной карте Radeon HD 5870. Таким образом, Cypress в покое необходимо на 86% меньше энергии, чем под нагрузкой. Конечно, добиться такого впечатляющего улучшения было не так-то просто. Этому способствовали несколько факторов, и, пожалуй, пара самых главных из них – дополнительные регулирующие цепи питания на плате вместе с новым специализированным блоком ядра по контролю над потребляемым питанием. Заметьте – никаких Power Gate транзисторов, как в CPU Bloomfield/Lynnfield поколения Nehalem, которые выключали бы незадействованные элементы ядра, добавлено не было. Фактически, использовался метод снижения частот работы компонентов. Однако не все так просто, как может показаться на первый взгляд. Дело в том, что именно для того, чтобы достичь на HD 5870 столь низких частот в состоянии покоя/2D режиме (а именно – 150 МГц по ядру, и 300 МГц по памяти), и потребовались упомянутые выше изменения в разводке платы и дополнительный модуль в самом GPU. Напомним, что для RV770 частоты 2D режима составляли 550/900 МГц. Именно падение частоты ядра почти в 4 раза и обеспечило столь впечатляющую экономию питания. В случае с RV770 просто так снизить частоты было невозможно. Многие продвинутые пользователи, экспериментирующие с прошивками BIOS и регулировкой частот/напряжений/оборотов вентилятора, столкнулись с проблемой потери стабильности RV770 на низких тактовых частотах даже при номинальном напряжении чипа. В RV870 проблема была эффективно решена, так что 150 МГц по чипу отныне легко достижимы, и установлены штатно. Никаких дополнительных действий со стороны пользователя не требуется. Но это еще не все. Куда большие изменения претерпел контроллер видеопамяти в Cypress. Отныне он более полно соответствует спецификациям стандарта GDDR5, и потому может применять предусмотренные JEDEC механизмы для минимизации потребляемой энергии. Оказывается, что в RV770 КП реализовывал лишь базовые требования GDDR5, и фактически мог пользоваться только преимуществами огромной пропускной способности. Различные продвинутые функции, включая возможность сильного снижения частот, попросту не были реализованы в RV770 и прочих чипах, созданных на его базе. Поэтому в HD 4870 и прочих high-end картах ATI, имеющих изначально высокую частоту GDDR5 для 3D режима, в 2D ее значения не изменялись вообще. В Cypress AMD реализовала практически весь возможный набор энергосберегающих технологий для GDDR5, которые помогают снижать планку требуемой мощности как самих чипов, так и набортного контроллера в GPU. Как и в случае с ядром, основной плюс проделанной работы – в возможности серьезного снижения частоты и напряжения GDDR5 без присущих таким резким переключениям негативных побочных эффектов. Более того, теперь модули памяти могут переводиться в специальный энергосберегающий режим путем отключения механизма проверки правильности передачи данных. По словам AMD, в таком виде GDDR5 контроллер и память ведут себя как GDDR3, и это довольно точное описания для состояния, в котором находится подсистема памяти HD 5870, когда «тяжелые» функции, обеспечивающие необходимую стабильность и скорость под нагрузкой, выключены. Наконец, AMD провела оптимизации энергопотребления для Crossfire режима. Теперь ведомая карта (естественно, речь идет о конфигурациях, состоящих из RV800 чипов), может потреблять еще меньше энергии, порядка 20 Вт. Это минимум, которого возможно достичь с 40 нм чипом, когда плата вообще не используется в 2D, но при этом питание на нее подано. В таком режиме плата может при необходимости мгновенно «проснуться». Дальнейшее снижение энергопотребления лишило бы Cypress такой способности. Естественно, важность низкого энергопотребления мощного чипа без нагрузки нельзя недооценивать. Тем не менее, еще более значимо то, как ведет себя видео, или же центральный процессор под нагрузкой. И здесь в Cypress также можно встретить некоторые новшества. Перед тем, как приступить к их описанию, следует напомнить, что TDP не является абсолютным показателем максимального энергопотребления, скорее это разумный максимум, за который, как считает производитель, не должен выходить чип под максимальной нагрузкой. Однако можно искусственно создать такие обстоятельства, при которых расчетное TDP будет серьезно превышено, и это – большая проблема.  Почему мы вдруг так подробно решили рассмотреть проблему превышения TDP? Дело в том, что она была особенно актуальна для RV770. Для CPU уже достаточно давно существуют различные стресс-тесты, которые генерируют фиктивную сверхвысокую нагрузку. Однако материнские платы, сами процессоры и кулеры лучше подготовлены к такого рода нагрузкам, чем видеокарты, которые являются единым продуктом (цепи питания, охлаждение – все поставляется как составные части изделия). Тогда как даже Linpack не вызывает серьезных проблем у грамотно разогнанных систем (про штатный режим и говорить нечего), видеотесты нового поколения, такие как FurMark и OCCT могут привести в крайнем случае даже к поломке видеокарты. Оказалось, что для RV770 максимально возможная нагрузка и TDP сильно разнятся, а VRM карт не были рассчитаны на нагрузку, которая не может быть достижима в реальных приложениях (естественно, запас прочности присутствовал, но не столь значительный). Так было сделано потому, что AMD считает потоки инструкций, генерируемые OCCT и FurMark, совершено нереалистичными. Они не производят каких-либо фактических расчетов, а просто направлены на одновременную максимальную загрузку всех блоков GPU. Ни в играх, ни даже в GPGPU приложениях такого не встречается (естественно, если не симулировать специально бессмысленные вычисления). AMD даже называет такие программы не тестами на стабильность системы, а «энергетическими вирусами». Хотя мы не можем согласиться с компанией в используемой терминологии, в тестах мы на практике не раз находили подтверждение правоте такой точки зрения. Ни одна игра, ни в одном, даже самом сложном режиме, не разогревала видеокарты так, как OCCT и FurMark. Тем не менее, вне зависимости от того, как называть такие тесты, они создавали реальные проблемы, будучи запущенными на RV770. Надо четко понимать, что, хотя микроэлектроника очень сложна и хрупка, производители не в состоянии предусмотреть все условия ее эксплуатации. Ведь сколь бы ни были совершенны автомобили Ferrari, вряд ли они подойдут для суровых зим; и сколь бы ни были хороши процессоры Core i7, они не смогут долго проработать с напряжением ядра в 2.0 Вольта. Так и здесь – любую, даже самую защищенную технику можно вывести из строя, эксплуатируя ее в неправильных условиях. Хотя стресс-тесты и являются простыми компьютерными программами, они создают чересчур высокую нагрузку. В лучшем случае, Radeon HD 4870 просто отключались во избежание повреждений, в худшем – карты выходили из строя; AMD требовалось что-то предпринять. Для уже имеющихся в наличии RV770 и прочих сходных карт было создано программное решение – драйверы Catalyst сначала определяли запускаемую программу по имени исполняемого файла, и применяли в случае необходимости торттлинг; позже был введен адаптивный алгоритм, вычисляющий вредоносную программу по соотношению инструкций, которые задействую ALU и текстурные блоки. По нашей информации, NVIDIA применяет точно такую же схему для своих плат. Такой подход оберегал RV770 от повреждений, однако программными средствами полностью решить аппаратную проблему было невозможно. 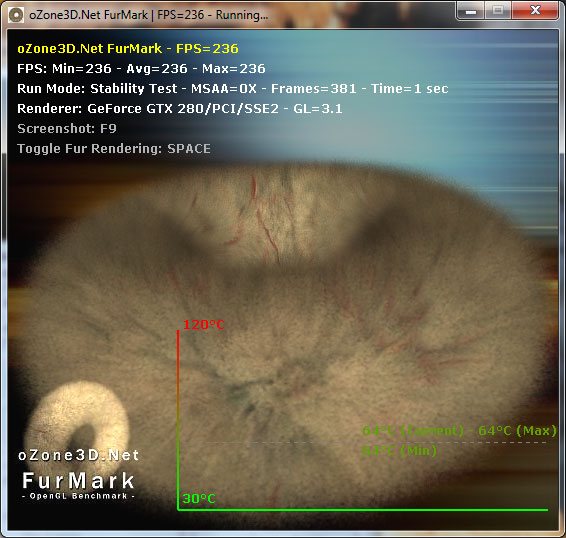 Естественно, разрабатывая чип следующего поколения, AMD постарались учесть допущенные просчеты. Для предотвращения описанных опасных ситуаций, в Cypress был добавлен выделенный блок мониторинга, среди функций которого – постоянное отслеживания состояния VRM и предотвращение критических нагрузок. Как только возникает тенденция неконтролируемого роста энергопотребления, RV870 мгновенно сбрасывает частоты. Если говорить точнее – спускается со своих номинальных значений на одну ступень PowerPlay. Карта продолжает работать в таком щадящем режиме до того момента, пока угроза повреждения VRM не исчезает. Если же нагрузка только возрастает, частоты падают еще сильнее – так, чтобы не создавать опасностей для подсистемы питания чипа. Еще раз уточним – никаких проблем из-за такого поведения в нормальных приложениях быть не может. Наше тестирование является тому доказательством. Мониторинг состояния чипа и VRM очень аккуратный, ни разу за все время, что карта подвергалась тяжелым тестам, частоты не были сброшены спонтанно. При запуске OCCT/FurMark же алгоритм срабатывал мгновенно. Таким образом, благодаря этому несложному механизму, карты на базе RV870 защищены от любых экстремальных ситуаций на аппаратном уровне. Совершенно неважно, какая программа попробует довести карту до критической точки – за четкую границу переступить не даст сама электроника. Это значит, что никаких дополнительных программных защит в драйвере больше не требуется. Хотя, безусловно, для RV770 уже разработанный механизм в Catalyst сохраняется. Интересной становится потенциальная разница в том, как поведут себя карты различных производителей в тяжелых условиях. Пока что на рынке доступны лишь референсные Radeon HD 5870, однако через некоторое время стоит ожидать появления моделей сторонних производителей. Одно из главных различий между картами и кроется в модифицированной системе питания. Какие-то вендоры, стремясь снизить конечную стоимость изделия, экономят, выбирая установку VRM минимально доступной мощности, какие-то, наоборот, создают солидный запас прочности. Хотя в случае с референсным изделием, как уже было сказано, троттлинг не срабатывал ни разу, не исключено, что в дешевых картах на базе RV870 такое явление будет встречаться. Также описанное нововведение касается и оверклокеров. Естественно, при разгоне карты начинают потреблять значительно больше мощности, токи возрастают. К счастью, алгоритм работы встроенного модуля мониторинга адаптивный, и не препятствует разгону. Первые тесты уже показали, что частотный потенциал 40 нм RV870 очень впечатляющий, скорее всего, появятся даже штатно разогнанные версии плат с частотой GPU в 1 ГГц. Сложности могут возникнуть при экстремальном разгоне с аппаратным вольтмодом, но такие тонкости уже выходят за рамки данного материала. Наконец, нельзя не сказать и о том, что новый модуль в ядре RV870 является одновременно еще и PWM контроллером. Это означает, что необходимость в отдельной дополнительной микросхеме на печатной плате отпала, а вместе с тем у производителей исчезла возможность сэкономить на данном элементе – с большой вероятностью мы не увидим больше плат с двухпиновым коннектором кулера. Все платы на основе Cypress и сходных с ним чипов изначально имеют возможность управления питания вентилятором, а потому и соответствующий четырехконтактный разъем. [N13-Еще о технологиях GDDR5: коррекция ошибок памяти и температурная компенсация] Как мы сообщали ранее, контроллер памяти GDDR5 в AMD Cypress отныне поддерживает большинство возможностей, предусмотренных спецификациями GDDR5. Речь идет не только о возросшей энергетической эффективности. В AMD поработали и над тем, чтобы платы могли достигать более высоких частот по памяти, а значит, и иметь большую пропускную способность. Главное из усовершенствований связано с механизмом коррекции ошибок. Одна из самых больших проблем, с которой приходится сталкиваться разработчикам при проектировании устройств с поддержкой столь скоростного типа памяти, как GDDR5, является необходимость в одновременно быстрой и широкой шине. Обычно эти параметры лежат по разные чаши весов, но в случае с пятым поколение GDDR их необходимо сочетать. Каждый чип GDDR5 на Radeon HD 5870 использует 32 контактные площадки для соединения с GPU и работает на базовой частоте в 1.2 ГГц. Это значит, что шина должна иметь чрезвычайно маленькие допуски и высокую точность. А ведь таких чипов, расположенных на многослойном текстолите карты, целых восемь, и общая разрядность составляет 256 бит. На таких частотах особенно при высокой плотности контактов и сложном алгоритме работы (ведь 1.2 ГГц соответствуют 4.8 эффективных гигагерц) очень тяжело избежать взаимных помех и наводок. Из-за подобных сложностей, связанных с созданием такой шины, именно она является слабым местом видеокарт с GDDR5. Сам контроллер памяти в кристалле графического процессора способен на большее, чипы памяти также могут достигать повышенной частоты, а «бутылочным горлышком» является именно способ соединения чипов и контроллера. Для того, чтобы справляться с негативными последствиями описанных выше причин, КП производят базовые операции по нахождению ошибок, как при чтении, так и при записи, с помощью встроенной функции хэширования CRC-8. Когда эта функция активна, то для каждых 64 бит переданных данных через специализированные выделенные 4 EDC контакта высчитывается и передается 8 бит хэша Cyclic Redundancy Check. Затем значение CRC используется для сверки хэша переданного контента на выходе, и на входе, чтобы определить, не произошло ли при передаче ошибок. Для GDDR5 точность определения CRC функцией ошибок в 1 и 2 битах составляет 100%. Чем больше битов передано с ошибками, тем ниже точность их распознавания. Это обусловлено используемым алгоритмом создания хэша, конкретной реализации CRC. По сути, это означает, что теоретически возможно такое совпадение, что хэш для выходных данных совпадет с хэшем некорректно переданных входных, и ошибка не будет найдена. Тем не менее, по статистике именно 1 и 2 битовые ошибки встречаются чаще всего. Если ошибка будет определена, контроллер GDDR5 запросит повторную передачу неверно принятых данных, и, пока информация не будет доставлена корректно, процесс будет повторяться. Также запрос на повторную передачу реинициализирует связь контроллера с чипами (это происходит в новой реализации GDDR5 у AMD довольно быстро), для того, чтобы исправить потенциально возникшие по вине внешних факторов проблемы. Это делается без каких-либо дополнительных операций вроде понижения частоты. Однако, если ошибки продолжают появляться и отслеживаться на установленных частотах, постоянные повторные запросы на передачу данных снизят итоговую производительность платы. Об этом стоит помнить при разгоне. 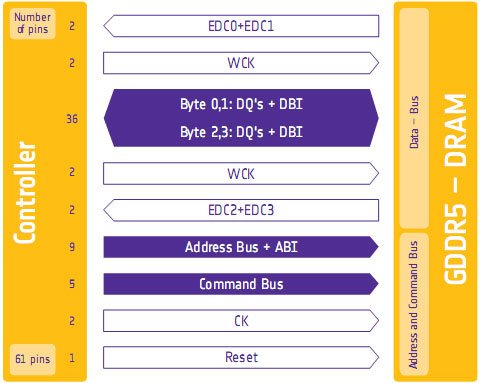 Наконец, следует акцентировать внимание на том, что данная схема работает только для определения ошибок, возникших по вине самой шины. Ошибки в самих чипах GDDR5, или же в контроллере, не распознаются, таким образом, отсутствие проблем во время самого процесса передачи еще не гарантирует корректности данных. Кроме того, как вы уже поняли, схема только лишь находит ошибки и не способна исправлять их на лету; при обнаружении неверных битов они просто передаются еще раз. То есть, оценивая данный алгоритм здраво, сложно признать его эффективным. Оказывается, что, несмотря на все трудности создания и работы высокоскоростной шины для соединения модулей и контроллером, стандартом не предусмотрено обязательное наличие механизма определения ошибок, он может быть отключаемым (именно это свойство использовано в состоянии покоя). По словам AMD, карты в любом случае должны быть до запуска в массовое производство отлажены так, чтобы никаких ошибок ни на номинальных, ни на разумно повышенных частотах, не наблюдалось. Иными словами, описанный выше механизм определения ошибок является скорее страховочным средством, нежели необходимым для достижения высоких частот механизмом. Так, крупный производитель памяти Qimonda в своих инструкциях дает лишь рекомендательный характер к использованию, говоря о возможных проблемах из-за хранения в памяти частей исполняемого кода. Ведь ошибки при работе с ним чреваты более серьезными последствиями (вроде вылета программы), нежели просто пикселем неверного цвета. Так что при нормальном режиме функционирования видеокарты, механизм попросту простаивает, осуществляя пассивный мониторинг. Кроме того, AMD были предприняты меры по улучшению разводки PCB, и, хотя число слоев платы осталось неизменным по сравнению с RV770, референсная карта Cypress должна достигать более высоких частот по памяти без появления ошибок. Кстати, как и в случае с новым блоком, на аппаратном уровне отслеживающим состояние VRM, изменения в механизме работы памяти должны ощутить на себе оверклокеры. Ранее при переразгоне карт, в тестах и играх просто начинали сыпаться ошибки и артефакты изображения. При первых признаках появления таких недугов следовало откатываться на предыдущее оттестированное стабильное значение. Теперь же, благодаря внедренному механизму коррекции ошибок, традиционный способ перестает быть работоспособным. Отныне вместо некорректного рендеринга изображения следствием переразгона будет служить падение производительности. Значит, при оверклокинге, помимо стандартных отслеживаемых параметров, необходимо будет постоянно тестировать и производительность карты. В идеальном варианте AMD могла бы предоставить пользователям фирменную утилиту, которая выдавала бы статистику по активности внедренного механизма коррекции ошибок памяти. На основании ее показателей можно было бы точно определить предел стабильных частот. Однако пока что это лишь наши фантазии. Итак, мы уже выяснили, что теперь контроллер памяти GPU способен снижать частоты во время простоя, задействовать механизм коррекции ошибок под нагрузкой, отключать его при необходимости; что инженеры AMD провели редизайн печатной платы с целью повышения порога стабильности работы. Однако, как оказывается, это еще не все. Помимо уже описанных функций механизма отлавливания ошибок он дополнительно способен следить за температурой чипов и при необходимости вновь мгновенно инициализировать связь GPU с чипами. Дело в том, что GDDR5 намного более чувствительна к перегреву, чем прошлые реализации Graphics Double Data Rate памяти. При нормальных условиях эта чувствительность ограничивала бы максимальные частоты работы, потому что постоянные изменения в скорости работы модулей при скачках температур делали бы невозможным сохранение стабильного соединения между памятью и КП GPU. Теперь же соединение может с минимальной задержкой реинициализироваться, как только наблюдается тепературный сдвиг, и более высокие тактовые частоты становятся достижимыми благодаря оперативному предотвращению сбоев шины. Хотя описание этой возможности звучит довольно просто, это не означает, что функция не важна. Мы уже несколько раз повторяли, что именно шина в прямом и переносном смысле является узким местом между чипами памяти и контроллером, а значит, малейшие усовершенствования (хотя и они дают довольно трудно) могут способствовать улучшению ситуации и достижению более высоких тактовых частот, а значит, и пропускной способности. [N14-Новый алгоритм анизотропной фильтрации] Уже несколько лет подряд можно наблюдать постоянное, но довольно медленное улучшения качества анизотропной фильтрации. Первые реализации алгоритмов как ATI, так и nVidia очень сильно зависели от угла наклона текстур. Многие издания даже проводили точные сравнения карт обоих производителей для того, чтобы определить, какие плоскости лучше удаются конкурирующим изделиям. В любом случае, какие бы сравнения не проводились, было очевидно, что была приемлема лишь анизотропная фильтрация высоких уровней. Однако время шло, и уже на прошлом поколении видеокарт качество анизотропии можно было назвать очень хорошим. NVIDIA почти вплотную приблизилась к созданию независимой от углов наклона фильтрации, AMD отставала ненамного. Тем не менее, ни одну из них нельзя было считать идеальной, хотя обе были хороши.
Видно, что у обоих производителей было, что улучшить. И AMD смогла достичь, казалось бы, еще недавно невозможного – с серией HD 5000 компания внедряет практически совершенный алгоритм, по-настоящему и полностью независящий от углов наклона. В прошлом остались различные трюки по улучшению качества и оптимизации. Взгляните сами:
Как хорошо видно, MIP уровни в нашем матером D3D AF тестере расположены по идеальным окружностям, что и является признаком независимой от угла наклона анизотропной фильтрации. С таким алгоритмом AF AMD однозначно побеждает NVIDIA на данный момент. Естественно, грядущий конкурент от калифорнийской корпорации наверняка обзаведется не менее эффективным и качественным алгоритмом анизотропии, но первой здесь все-таки, как и в случае с битмтриммингом DTS-HD MA или Dolby True HD, стала именно AMD. Лирическое отступление. Описывая многогранные изменения, которые произошли в RV870 по сравнению со своим предшественником, просто поражаешься, насколько был улучшен и без того удачный чип. Причем улучшен не только с точки зрения увеличения производительности (а ведь изначально Cypress многие воспринимали как удвоенный RV770), но и по множеству дополнительных, незаметных на первый взгляд мелочей. Именно такое внимание к деталям формирует мнение о продукте, и видеокарты здесь не исключение. Интересно, что AMD говорит о том, что скорость фильтрации при возросшем качестве осталась на прежнем с серией HD 4000 уровне; значит, существенного влияния на производительность активация AF производить не должна. При этом, однако, в реальных приложениях довольно сложно увидеть разницу между фильтрацией старого и нового поколений. Но это, естественно, не является недостатком HD 5870 и сходных карт – просто и старый алгоритм был очень эффективным, а новый доведен до совершенства. [N15-Возвращение Supersample AA] За годы существования различных техник сглаживания, методы антиалиасинга на видеокартах претерпели многочисленные изменения. На ускорителях первых поколений, таких как 3Dfx Voodoo 4/5, или решений ATI и NVIDIA с поддержкой DirectX 7, существовал по сути лишь один тип сглаживания – суперсемплинг. Его принцип был чрезвычайно прост. Картинка рендерилась в более высоком, чем у дисплея, разрешении, и затем масштабировалась до нужных размеров. Качество таких трансформаций было очень высоким – не только исчезали режущие глаза лесенки алиасинга, но и само изображение в целом становилась чуть более качественным благодаря тому факту, что изначально создавалась в более высоком разрешении. Однако суперсемплинг слишком сильно ударял по производительности, особенно на картах тех лет и не мог найти широкого применения из-за слишком сильной потери в скорости. Требовался новый, более совершенный алгоритм, и им стал мультисемплинг. Вместо того чтобы отрисовывать всю сцену в более высоком разрешении, обрабатывались лишь края полигонов для нахождения, и последующего устранения эффекта алиасинга. Общий уровень качества был не столь высок, однако скорость работы MSAA в разы превосходила суперсемплинг, причем разрыв только увеличивался с усовершенствованием технологии. Со временем стало понятно, что MSAA не слишком качественно выполняет свою работу на фоне улучшения прочих характеристик видеокарт, требовалась переработка мультисемплинга. Здесь суперсемплинг пережил свое второе рождение в виде новых адаптивных технологий ATI и NVIDIA, затрагивающих только определенные части кадра, Adaptive Anti-Aliasing(AAA) и Supersample Transparency Anti-Aliasing(SSTr) соответственно. В таком случае, SSAA использовался для сглаживания полупрозрачных текстур, ведь они были источником артефактов алиасинга, а MSAA не мог их обрабатывать потому, что они не являлись полигоном (AA мог применяться на краях объектов, для этого и был нужен дополнительный режим). Это все еще не полностью исправило все недостатки MSAA, но хотя бы проблем с прозрачными текстурами более не наблюдалось. Например, MSAA была не способна сглаживать шейдерные эффекты, что, скажем, выливалось в невозможность включения HDR+AA на GF седьмой серии. Словом, пертурбаций на пути развития AA было много. Чего только стоит крайне неудачный перенос функций сглаживания в R600 со стандартных ROP на шейдерные процессоры, из-за чего случались заметные потери производительности при включенном сглаживании на картах серий Radeon HD 2000 и 3000. Затем, правда, в AMD одумались, вернув базовый MSAA антиалиасинг на ROP, и задействовав потоковые процессоры только для прогрессивной постобработки картинки методом CFAA с фильтрами типа edge-detect. Стоит отметить, что в серии HD 5800, последние описанные алгоритмы сглаживания, которые, к слову, разумно жертвовали производительностью в угоду высокому качеству, были дополнены самым настоящим суперсемплинговым антиалиасингом, давно исчезнувшем из современных карт. Теперь у продвинутых геймеров вновь есть выбор между более быстрым сочетанием MSAA+AAA (в его различных вариациях), или же старый добрый полноэкранный SSAA антиалиасинг. В AMD посчитали данное действие разумным потому, что в действительности у карты огромная вычислительная мощность, которой можно позволить себе даже несколько поразбрасываться. К тому же, если производительности в самых новых, графически сложных играх и будет не хватать для этого режима, можно воспользоваться более легкой, но менее качественной техникой, которая была разработана еще для RV770. А в играх прошлых поколение SSAA хотя и скажется на производительности серьезно, но вряд ли непрофессиональные геймеры почувствуют разницу между 300 и 150 FPS на средних ЖК мониторах с частотой развертки в 60 Гц. Тогда как на глаз разница между CFAA и MSAA все же заметна. К тому же, MSAA попросту заблокирован для DirectX 10 и 11 игр, так что «старые игры» здесь ключевое слово. Тем не менее, ограничение сферы использования суперсемплинга DirectX 9 и OpenGL оправдано и закономерно – в играх с более новыми движками падение скорости было бы слишком серьезным. Запуск DX10 или DX11 игры с активированным SSAA автоматически вызовет переключение драйвера на одну из разновидностей MSAA. К тому же не стоит забывать, что в среде DirectX 10 и 11 у разработчиков есть более тонкие инструменты для сглаживания изображения, нежели способен дать драйвер. Ни для кого не секрет, что, например, в играх с использованием отложенного рендеринга, выставляемое из драйверов карт сглаживание вообще на деле не применяется. Для того чтобы таких несовместимостей было как можно меньше, AMD заблокировали SSAA для RV870. Тем не менее, компания обещает в будущем искать возможности активации этого режима для тайтлов DX10/11, но не стоит ждать такого нововведения в скором времени. К сожалению, наше тестирование показало, что режим SSAA на RV870 требует доработки. Для сравнения качества мы решили использовать одну из начальных сцен второго эпизода Half Life 2, насыщенную предметами, на которых хорошо виден алиасинг, - металлическими бочками, машинами и деревьями. Хотя, как это хорошо видно на паре нижних скриншотов, SSAA на HD 5870 полностью избавил картинку от лесенок, он ее к тому же довольно серьезно замылил. Это является в прямом смысле недоработкой – хотя суперсемплинг действительно должен придавать изображению мягкости, убирая алиасинг на всех сложных объектах, он никак не предназначен для создания дополнительного неуместного блюра.
После более подробного исследования проблемы оказалось, что дело здесь в баге движка Source, на котором базируются игры из используемого нами The Orange Box, а не в реализации SSAA в последней версии Catalyst. AMD надеется в скорейшем времени выпустить баг-фикс, устраняющий данное недоразумение, но сам факт не идеальной работы SSAA в первом же выбранном тесте говорит о несовершенстве технологии. К тому же игры на базе Source ограничены мощностью CPU, а не видеоподсистемы, а значит являются отличным кандидатом для использования суперсемплинга. «Но стойте!» - Скажете вы. - «Разве у NVIDIA нет реализаций SSAA? Как работают они?» По большому счету, замечание верное. Хотя официально SSAA не поддерживается уже на протяжении нескольких лет, из драйверов данная возможность полностью вырезана не была, и ее можно активировать в Direct3D играх посредством различных утилит вроде nHancer. На деле же SSAA от NVIDIA не может быть сравним по качеству с имеющейся у ATI, и вот почему.
На верхней схеме показан DX9 FSAA вид реализации режима 4x SSAA. Обратите внимание, что сетка с четырьмя геометрическими (красными) и четырьмя (зелеными) текстурными семплами повернута под углом. Чуть ниже – 4x MSAA от NVIDIA на GeForce GTX 280 с четырьмя геометрическими, и одним текстурным семплами. Наконец, на третьем рисунке – ровная сетка из четырех геометрических и текстурных семплов. Не будем углубляться в причины, почему уже давно используются повернутые сетки, но качество стандартной ровной матрицы будет однозначно хуже. Скриншоты подтвердят это теоретическое утверждение. На самом деле, запустив HL2: Episode 2 на карте NVIDIA в режиме SSAA, мы столкнулись с еще большем ухудшением качества изображения, чем у официально поддерживаемого SSAA у ATI. Сложно сказать, вызвано ли это именно стандартным расположением семплов, не использующимся уже давно, но вероятность этого велика, что бы ее игнорировать.
Если сравнить эти два скриншота, видно, что картинка с MSAA 4x практически идеальна, за исключением малозаметных артефактов в нижней/боковой частях вагончика. Если переключиться на 4x SSAA, эта лесенка исчезнет, однако появится другая проблема – ухудшившееся сглаживание прицела, и, что хуже, попросту исчезнувшие ветви деревьев. Тогда как MSAA аккуратно сгладил контрастные переходы, убрав все артефакты, SSAA попросту удалил их с изображения. По этой причине мы не рассматриваем SSAA сглаживание у NVIDIA и не сравниваем его с вариантом AMD. Во-первых, такой режим официально не поддерживается, а во-вторых, качество сглаживания при его активации страдает. Скажем больше – хотя мы и не приводим прочих скриншотов, нам встретились игры, в которых FSAA NVIDIA вызывал еще большие проблемы, чем в HL2. Таким образом, этот заблокированный режим вряд ли подходит для нормального использования. Возможно, ситуация изменится позже с выходом Fermi, но на данный момент SSAA – дополнительный микроплюс новинки от ATI, которому у NV на данный момент нечего противопоставить. [N16-Качество антиалиасинга и скорость его работы] Так как мы выяснили, что HL2 несколько некорректно работает с SSAA, для подробного исследования качества во всех режимах мы выбрали Crysis: Warhead, у которого никаких проблем ни с одним типом сглаживания не наблюдалось. Графика Warhead не только сложна для рендеринга, но и насыщена объектами, на которых эффект алиасинга хорошо заметен. На нашем конкретном примере стоит обратить внимание на листья слева и справа от ветрового стекла автомобиля, на установленную на крыше турель, а так же на боковое стекло в двери и зеркало заднего вида. Помните, что, так как текущая реализация AMD SSAA не работает с DX10 играми, в Crysis мы использовали DirectX 9 режим. Radeon HD 5870:
Radeon HD 4890:
GeForce GTX 280:
С точки зрения качества изображения трудно увидеть серьезную разницу между AMD Radeon HD 4890 и 5870 в соответствующих режимах. На наш взгляд, с включенным MSAA+AAA качество полностью одинаковое (что и логично – ведь никаких заявлений о переработке алгоритмов AA в RV870 относительно RV770 сделано не было). И, хотя карты разных вендоров несколько иначе отображают картинку (яркость неба разнится), работу по антиалиасингу все платы проводят образцово. Для AMD негативной стороной проведенного теста качества картинки является тот факт, что сложно говорить о превосходстве SSAA над |
||||||||||||||||||||||||||||||||||||||
Источник: www.anandtech.com/