Каталог
Архитектура GF100 под микроскопомХотя из-за нескончаемого потока слухов и новостей о Fermi кажется, что прошло больше времени, NVIDIA анонсировала свою новую архитектуру в сентябре 2009 года. Тогда компания сфокусировалась на не слишком интересных для простого пользователя вычислительных возможностях GPU, которому было суждено получить кодовое название GF100. На CES же все внимание было уделено структуре новинки применительно к "домашнему" использованию. Следящие за новостями читатели наверняка знают, что GF100 состоит из 512 SP, которые NVIDIA отныне называет CUDA Cores, как бы намекая на широкие возможности Fermi, не ограниченные лишь графическими расчетами. Самостоятельно работать они не в состоянии, и организованы в блоки по 32 ядра, которые называются Streaming Multiprocessor (SM). Те, в свою очередь, объединены четверками в Graphics Processing Cluster (GPC). Наконец, сам чип GF100 состоит из четырех таких вычислительных кластеров. Так и получается заявленное NVIDIA число в 512 ядер CUDA (32 x 4 x 4 = 512).
Когда NVIDIA впервые приоткрыла завесу над GF100, мы не знали ничего о ROP, текстурных блоках и прочих необходимых GPU функциональных модулях. Сегодня эта информация стала доступна. Тогда как GF100 во многом напоминает GT200, если рассматривать данный GPU в качестве вычислительного многоядерного процессора, в игровом плане новинка далеко ушла от предыдущего поколения унифицированной шейдерной архитектуры NVIDIA. Наибольшее отличие состоит в том, что привычные по чипу GT200 (и его предкам начиная с G80) блоки фиксированных по функциональности модулей графического конвейера были полностью перестроены. По сути, переход от GT200 к GF100 напоминает выпуск Intel CPU Core i7 после Core 2 Duo. Базовые компоненты, входящие в состав чипа, претерпели сравнительно небольшие изменения, тем не менее, их новая структура и связки (плюс важнейшие новые модули) были созданы "с нуля", для того чтобы обеспечить гибкость и масштабируемость. Взгляните на подробную блок-схему новой разработки NV:   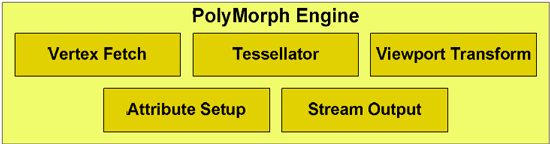 Хотя описанная структура геометрических движков могла показаться вам простой, не стоит недооценивать это нововведение. NVIDIA не просто перенесла старые геометрические блоки на новое место, продублировав их 16 раз. Ранее, как и в случае с Raster Engine, построение геометрии было отдельной фиксированной стадией рендеринга. Теперь же, с разделением и реструктуризацией геометрия рассчитывается совершенно по-новому. Компания сама создала для себя здесь огромный объем работ высокой сложности. Возникает логичный вопрос: зачем все это надо было делать? Оказывается, для параллелизма и внеочередного исполнения. Принципиальный ответ на вопрос, зачем потребовалось так усиливать геометрическую производительность чипа и укреплять возможности по установке треугольников и их последующей растеризации, находится в самой истории аппаратных графических 3D-ускорителей. Дело в том, что на разных этапах развития игростроя на первый план поочередно выходили различные аспекты построения картинки. Скорость текстурирования, возможность обработки как можно большего числа треугольников в сцене, попиксельные шейдерные эффекты, наконец. В конце концов, перевес в математической производительности, по-видимому, оказался чрезмерным, и было решено улучшать геометрические возможности, на которые долгое время не обращали особого внимания. NV приводит данные, согласно которым производительность GT200 (GeForce GTX 280) по шейдерным вычислительным превосходит NV30 (GeForce FX 5800) более чем в 150 раз. В тоже время, разница в геометрической скорости — лишь трехкратная! Включив аппаратную поддержку тесселяции в DirectX 11, Microsoft очень сильно повлияла на развитие игровых технологий и проектирование GPU. Конечно, не стоит думать, что это инициатива исключительно одной корпорации, но факт остается фактом — достигнув высот в пиксельной обработке графики, индустрия сфокусировалась на геометрическом качестве моделей. Безусловно, единым порывом решить проблему относительно малого (по сравнению с той же трехмерной кинематографической анимацией) числа обрабатываемых треугольников невозможно. Ведь к имеющимся сегодня математическим возможностям шли не один год и не одно поколение архитектур и чипов. Но, сделать большой скачок, пойдя не простым путем линейного наращивания исполнительных блоков, а внедрив качественно-новую технологию, можно. Это в свое время еще в Xenos пыталась сделать ATI (однако тесселяция не получила особого распространения на Xbox 360), теперь же тесселятор является обязательным DX11 условием. На него делается ставка в ключе повышения уровня проработки 3D-моделей. В паре с возможностью наложения карт смещения, тесселяция поистине творит чудеса. Технология обладает большим количеством достоинств, таких как поддержка динамической геометрии, или низкие требования к пропускной способности шин благодаря малым размерам исходных данных.  Запаздывая с анонсом своего нового чипа, и будучи связанной жесткими требованиями DX11, NVIDIA не оставалось ничего другого, кроме как заложить в дизайн Fermi уникальные возможности, которые обеспечили бы не только текущую победу над конкурентом, но и перспективное развитие в будущем. Ведь выпуская серию GTX 400 с таким опозданием, NVIDIA необходимо перехватить инициативу не только в краткосрочном периоде. К тому же и момент довольно удачный — экстенсивно получить из Evergreen вдвое мощную карту AMD уже не сможет, а на разработку новой архитектуры нужны ресурсы, и, в первую очередь, время. Как NVIDIA решила использовать шанс? Сделав ставку именно на основные требования DirectX 11.
Безусловно, внедрение поддержки GDDR5, усовершенствование алгоритмов сглаживания, развитие самих SP, иная группировка модулей — все это важно, но, не побоимся этого слова, революционное изменение структуры конвейера рендеринга с внедрением внеочередного исполнения команд для этапов построение геометрии, пожалуй, наиболее интересное новшество Fermi. Кстати, данный факт говорит о том, что, несмотря на все возможности GF100 по GPGPU вычислениям, NVIDIA пока позиционирует свои решения именно как графические карты. Следует понимать, что на данном этапе каждый PolyMorph Engine в отдельности является довольно простым модулем с очередным исполнением. Тем не менее, так как самих блоков в чипе целых 16, возникает необходимость постоянно отслеживать их состояние и загруженность, так же как это делается в современных CPU. Ведь нельзя допускать, чтобы какой-либо из PME "убегал" вперед, а другие, напротив, простаивали без работы. В таком случае может не сохраняться целостность результатов. Для того чтобы препятствовать появлению коллизий при такой структуре полиморфных движков, все они обладают общим выделенным каналом связи для синхронизации. Очень трудно заставить работать корректно и эффективно такой массив параллельных вычислительных модулей. Нельзя недооценивать всю сложность такого подхода. Перед инженерами NVIDIA стояла трудная задача, и компания гордится, что ее удалось решить. Однако, вместе со всеми положительными эффектами от увеличившейся скорости работы чипа и возможностями для будущего увеличения геометрической производительности, у введения PolyMorph Engine есть и обратная сторона. Хотя представители компании не говорили об этом открыто, похоже, что именно сложностями с PME обусловлена задержка анонса. С одной стороны, калифорнийская корпорация подготовила почву для дальнейшего роста, и создала уже сейчас крайне мощное решение на базе архитектуры Fermi. Остается лишь один вопрос — насколько эффективным окажется данное вложение ресурсов на сегодня? Сделав ставку на улучшение геометрической составляющей GPU и полную перебалансировку конвейера, NVIDIA создала действительно новую архитектуру. Более чем удвоенное количество усовершенствованных SP определяет лидерство GF100 среди одночиповых решений (даже с учетом возможности низких частот работы). Но упущенного времени компании уже не вернуть. В тоже время DX11 вместе с продвинутым аппаратным тесселятором являются технологиями будущего, которые без соответствующей программной поддержки будут попросту простаивать. А на данный момент игровых приложений, написанных под 11 версию API Microsoft, можно сказать, нет. Появятся ли они до того момента, как конкуренция между графическими гигантами пойдет на новый виток, и оправдает ли себя задержка GF100 из-за кардинального редизайна ключевых модулей графического конвейера, покажет лишь время. Возвращаясь к фактическим данным GF100, стоит отметить, что, так как теперь полиморфный и растровые движки находятся в кластерах, разные версии Fermi будут отличаться более существенно. Ведь в любом из предыдущих чипов, скажем, G92 или RV770/870, конвейер рендеринга оставался фиксированным, тогда как в GTX 400 его общая скорость работы будет зависеть от количества активированных блоков в чипе.  Была усовершенствована и подсистема памяти.  Наконец, претерпели изменения и сами ROP. Нетрудно догадаться, что и их реорганизовали. Теперь доступно целых 48 модулей, в 6 связках по 8 блоков. Каждую из этих связок обслуживает один 64-битный контроллер памяти. Каждый ROP может за такт обрабатывать 1 пиксель 32-битной точности, 1 FP16 за два такта, или же 1 FP32 за 4 такта. То есть, максимальная производительность ROP составляет 48 пикселей за такт. Эти модули должны обладать впечатляющей эффективностью, так как имеют доступ к массивному по меркам GPU L2. Стоит отметить, что, хотя общая разрядность шины памяти уменьшилась по сравнению с GT200, где было 8 контроллеров, пропускная способность памяти за счет использования недоступной ранее прогрессивной GDDR5 только возрастет, и сужение шины сполна компенсируется высокими эффективными тактовыми частотами. К тому же, положительным эффектом от такого упрощения может стать и снизившаяся сложность дизайна печатной платы для GF100. Интересно, что частоты теперь считаются не от базового ядра, множителями, а от шейдерного домена, делителями. Лишь ROP и L2 являются независимыми. Текстурные модули, новые полиморфные и растровые движки работают на половинной частоте ядер CUDA (GPC Clock в терминологии NVIDIA), тогда как сами SP и кэш L1 функционируют на полной частоте. Совершенно точно, что для разгона GF100 потребуются совершенно иная методика, нежели привычная еще со времен 8800GTX. [N3-Улучшенное качество графики] Четко определенные спецификации DX11 не дают производителям особой свободы. Без поддержки со стороны Microsoft практически невозможно встроить какую-то новую функцию по своему усмотрению. И даже если это удается, есть риск создания модуля, который разработчики никогда не будут использовать, как произошло с тесселятором в AMD Radeon 2000-4000. Поэтому инновации приходят не со стороны расширения и без того достойных возможностей API, а со стремления улучшить качество графики различными техниками, которые минимизируют врожденные недостатки "плоской" 3D-графики. Мы не просто так упомянули DX11. Дело в том, что хотя требования Microsoft однозначны касаемо предоставляемого набора возможностей, компания не пытается навязать свое мнение в технической реализации. Так, конвейеры GF100 и RV870 принципиально разнятся "в железе", но полностью совместимы программно. Еще один схожий пример: jittered sampling. Данная техника применяется, например, при расчете теней и в разных пост-процессинговых фильтрах. Обычно JS используют для создания мягких теней из карты теней — случайным образом выбирается семпл ближних текселей, и на этой базе вычисляется сглаженная граница тени. Самая большая проблема с таким методом — в скорости работы, так как требуются "тяжелые" вычисления. Поэтому jittered sampling не всегда может быть применен.   Не может не радовать, что прибавку в производительности получили режимы и с использованием антиалиасинга. Как и AMD, при разработке нового GPU, NVIDIA усовершенствовала ROP для уменьшения падения производительности при 8x MSAA. С таким сглаживанием фреймрейт в большинстве требовательных игр был слишком низок. Компания заявляет о росте скорости работы ROP более чем в два раза относительно GTX 285 в частных случаях.
Безусловно, работа новинки при MSAA 8x требует более детального рассмотрения, но мы не слишком уверены, что падение производительности в этом режиме соответствует улучшению качества. Еще одним интересным решением для повышения качества изображения является улучшенный и переработанный Coverage Sample Anti-Aliasing. CSAA был впервые представлен в G80. Данный легковесный метод при количестве семплов в 8x не столь качественен, как, например, MSAA, но зато практически не требует ресурсов (либо же достигает лучшего качества при тех же затратах).
В связи со спецификой своей работы, на G80 и GT200 CSAA мог сглаживать только края полигонов. Алгоритм свою работу выполнял эффективно, однако был беспомощен перед артефактами других типов. Основные проблемы возникали с различного рода полупрозрачными поверхностями, такими как текстуры заборов, листьев, кустиков травы, которые являются некоторого рода компромиссом и упрощением, так как при тщательной проработке потребовали бы невероятного количества геометрических ресурсов, а результат качественно не соответствовал бы затратам. Так как такие текстуры обладают большой площадью и не содержат внутри никакой геометрии, прошлая реализация CSAA пасовала перед сглаживанием содержимого. Справедливости ради стоит отметить, что данный недостаток не присущ лишь этой технологии. Ведь даже для MSAA полноценное решение вопроса пришло только в DX10 с представлением технологии alpha-to-coverag |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Источник: www.anandtech.com/