Каталог
GF110: новые трюки в арсенале FermiПришло время ознакомиться более подробно с характеристиками «сердца» GTX 580 — GPU GF110. О том, каким будет GF110, ходило множество слухов. Одно было ясно наверняка — последователь GF100 недалеко уйдет от своего предка из-за ограничений 40 нм производства. Ведь физический размер чипа был и без того огромным, и ожидать чего-то более массивного при сохранении технологических норм было просто недальновидно. Напротив, провести оптимизации существующего решения, внести в него легкие коррективы, и задействовать весь потенциал NVIDIA было вполне по силам. Что, собственно говоря, и было сделано. Многие из этих оптимизаций мы уже видели в GF104, и, если бы месяц назад автора этих строк спросили, каким ему представляется GF110, он бы нарисовал в воображении некий гибрид GF100 и GF104. Реструктуризация SM по подобию GTX 460 с 48 ядрами CUDA в одном мультипроцессоре для повышения максимальной теоретической производительности и внедрение возможностей суперскалярного исполнения вместе с дополнительными текстурными блоками и модулями специальных функций выглядело бы логичным шагом; ведь в GF104 это привело к существенному повышению быстродействия. Однако проектировщики NV исходили из каких-то иных соображений, поэтому GF110 имеет все же больше общего с GF100, чем с GF104. Впрочем, это не означает, что GTX 580 не был обучен некоторым новым трюкам.
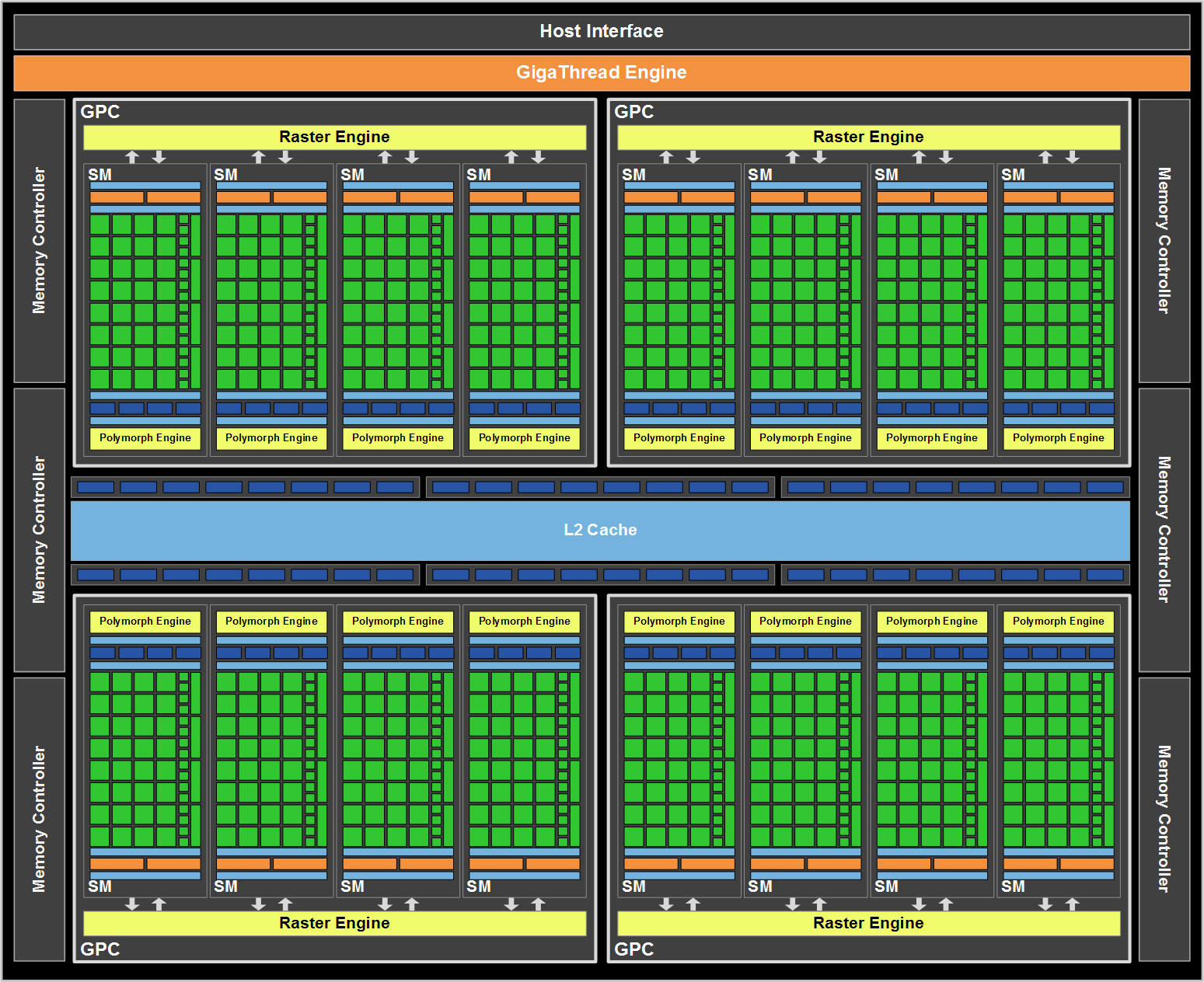
На фундаментальном уровне архитектура GF110 идентична GF100, особенно если говорить о массиве вычислительных процессоров. 512 ядер CUDA распределены по 4 кластерам GPC, каждый из которых содержит по одному растровому движку и четырем мультипроцессорам SM. В свою очередь, каждый SM наделен 32 потоковыми процессорами, 16 модулями загрузки/хранения, 4 SFU, 4 текстурными блоками, 2 планировщиками варпов с диспетчером загрузки на каждом из них, 1 полиморфным юнитом (содержащим аппаратный тесселятор), 48 Кб + 16 Кб кэша первого уровня, регистрами и прочими не слишком важными для нас компонентами (с пользовательской точки зрения). Разработав такую структуру, NVIDIA полагается на высокий уровень параллелизма в нитях команд (TLP) для максимально эффективного использования имеющихся ресурсов потоковых процессоров. Кроме того, в состав чипа входят ROP и L2 кэш объемом 768 Кб, который служит определенного рода буфером между шестью 64-битными контроллерами памяти и SM. Можно констатировать, что удельная вычислительная мощность в расчете на 1 МГц частоты GF110 не изменилась относительно GF100, так как в структуру графического процессора не было привнесено никаких количественных изменений (если не брать во внимание тот факт, что в GTX 480 так и не были задействованы все имеющиеся на кристалле модули). Напротив, с качественной стороны, важной для рендеринга игровой графики, были произведены некоторые улучшения. Пускай структура шейдерных процессоров GF104 не была перенесена в GF110, зато от него были взяты улучшенные текстурные модули. Тогда как в GF100 каждый текстурный блок был способен вычислять 1 текстурный адрес и выбирать 4 32-битных/INT8 текстурных семпла за такт, 2 64-битных/FP16 семпла, или же 1 128-битный/FP32 семпл, в GF104 есть возможность работы сразу с 4 семплами за такт для 32 и 64-битной точности. Такие же способности теперь есть и у GF110, так что 64-битные/FP16 выборки происходят вдвое быстрее, чем у GF100. Это первое из двух главных новшеств, реализованных NVIDIA для повышения быстродействия отрисовки графики на GF110.
Как это часто бывает с различного рода оптимизациями, эффект от них будет заметен в ограниченном круге игр. В данном случае, речь идет о влиянии на новые приложения, разработанные с использованием техник 64-битной FP16 фильтрации. Именно в них прирост будет наиболее ощутим. В старых же играх, которые такими задачами видеокарту не нагружают, вряд ли будет существовать хоть какая-либо разница. Также обратим ваше внимание на то, что тогда как текстурная фильтрация точности FP16 была ускорена, в ROP никаких усовершенствований внесено не было — для обработки 64-битных FP16 пикселей блокам растеризации по-прежнему требуется 2 такта (и 4 для 128-битной FP32 точности). Стоит заметить и то, что соотношение возможностей текстурирования к скорости математических вычислений осталось прежним. По сравнению с GF100, в GF104 было удвоено количество текстурных юнитов при увеличении числа шейдерных процессоров на 50% в одном SM; в результате на 32 обработанных текселя приходилось 96 вычисленных инструкций (с учетом того, что шейдерный домен работает на удвоенной базовой частоте ядра), что и давало пропорцию 1:3. В GF110 же сохраняется привычное по GF100 соответствие 1:4 (16:64). Поэтому, хотя по вычислительной мощи GF104 и GF100 существенно разнятся, наличие 64 текстурных модулей в обоих чипах уравнивает их по быстроте текстурирования. Второе заметное усовершенствование, впервые появившееся у NVIDIA в GF110, направлено на ускорение тесселяции. Речь идет о технологии отбрасывания невидимых поверхностей Z-culling, которая была модернизирована для GTX 580. У читателя может возникнуть резонный вопрос, каким образом это понятие вообще связано с тесселяцией. Перед тем, как ответить на него, напомним кратко суть данной методики. Она необходима для того, чтобы увеличивать быстродействие GPU путем отбрасывания пикселей, которые не попадут в кадр при выбранном игроком угле поворота камеры и соответствующем взгляде на сцену. Технология работает уже на первых этапах рендеринга изображения. Алгоритм сравнивает глубину и прозрачность нового пикселя с уже существующим в Z-буфере, определяя таким образом, появится ли точка в видимой игроку зоне. Те пиксели, которые попадают за непрозрачные объекты, далее не обрабатываются, тем самым экономя вычислительные ресурсы GPU и пропускную способность памяти. Этот принцип применялся долгие годы, но с момента разработки и внедрения под названиями HyperZ у ATI и Lightspeed Memory Architecture у NVIDIA, по сути, серьезно не обновлялся.
С GF110 ситуация меняется. Нельзя сказать, что NV совершила революцию в Z-culling, скорее речь идет о тонкой подстройке алгоритма для лучшей работы с учетом особенностей аппаратной тесселяции. Компания не слишком распространяется об изменениях, но согласно проведенным энтузиастами на Beyond3D исследованиям, были введены новые размерности тайлов (внутренняя растеризация и Z-Culling происходит в этих так называемых группах пикселей), в частности, 4x2, для лучшей совместимости с мелкими треугольниками, получаемыми вследствие работы тесселятора. Опять же, это означает, что эффект будет заметен только в играх, широко использующих тесселяцию. В случае же с треугольниками типичных размеров особой пользы это не принесет, так как кардинальных изменений в сам принцип определения невидимых поверхностей, скорее всего, внесено не было. Действительно, не самые впечатляющие изменения. Но критиковать NVIDIA по данному поводу не следует. Ведь тратить существенные временные и материальные ресурсы на серьезную модификацию и без того производительного чипа в рамках архитектуры одного поколения неразумно. Кроме того, сейчас GPU уже достигли такой сложности и размеров, что пора начинать забывать времена, когда производители могли порадовать нас серьезным обновлением линейки видеокарт пару раз в год. [N3-Новый подход к энергетическим характеристикам GeForce GTX] Помимо специфических архитектурных улучшений в GF110, которые мы обсудили ранее, NVIDIA переработала дизайн чипа и на более низком уровне в стремлении улучшить энергетическую эффективность GPU. Парочка GF100/GTX 480 быстро снискала репутацию горячего продукта, и нельзя сказать, что это было неоправданно. Даже притом, что в GTX 480 работали не все SM, карта имела заявленный уровень TDP в 250 Вт, и даже это чрезвычайно высокое для одночиповой платы значение могло быть превзойдено в ситуациях с экстремальной нагрузкой, вроде FurMark. Инженеры компании могли переработать систему охлаждения (и сделали это) для лучшего рассеивания тепла, но ограничение и снижение самого тепловыделения было не менее важно. Особенно в свете выпуска высокочастотных моделей со всеми активными блоками GF110 как на потребительском рынке в серии GeForce, так и на корпоративном в Tesla. Ведь если даже предположить, что в системных блоках игроков бывают установлены еще более горячие 3D-ускорители, то в HPC вопрос охлаждения стоит намного более остро. Понимая все это, NVIDIA принялась за оптимизацию дизайна новинки на транзисторном уровне. Полупроводники являются практически идеальными устройствами для перевода энергии в тепло, поэтому основная задача заключается в том, чтобы произвести как можно больше полезной работы, затрачивая при этом как можно меньше энергии. Это также напрямую связано с тем фактом, что динамическое питание (которое непосредственно используется для работы) формирует только часть энергопотребления — остальные ватты рассеиваются впустую из-за токов утечки. В случае с высокопроизводительным GPU, у NVIDIA нет строгой необходимости уменьшать динамическое питание чипа, так как это негативно повлияло бы на быстродействие графического процессора. Вместо этого, можно сконцентрироваться на минимизации рассеиваемой впустую энергии. Кроме того, не стоит забывать, что транзисторы начинают вести себя непредсказуемо именно на высоких частотах, и сделать с этим что-то практически невозможно, ведь стабильность находится в прямой зависимости от скорости переключения затвора.
Фокус состоит в том, что для создания энергетически эффективного кристалла необходимо использовать высокопроизводительные транзисторы (пускай и не идеально стабильные) там, где это необходимо, и ограничиться более медленными компонентами во всех прочих случаях. Именно по этому пути NVIDIA пошла в GF100, используя в основном 2 типа транзисторов, которые можно дифференцировать по описанному выше признаку. Мы не уверены, какого типа «переключатели» были использованы для конкретных функциональных блоков, однако с высокой степенью вероятности можно утверждать, что весь массив шейдерных процессоров и прочие устройства, работающие на увеличенной частоте, были «сконструированы» с использованием быстрых транзисторов с большими значениями токов утечки. Прочие же модули, работающие на базовой частоте, использовали медленные транзисторы. Несмотря на такой грамотный подход, энергопотребление GF100 все равно зашкаливало, что и выражалось в чрезмерно большом тепловыделении. Нельзя сказать, что выбранный подход оказался удачным. В структуру GF110 NVIDIA включила третий тип транзисторов, который в официальной презентации компании описывается как «обладающий усредненными свойствами относительно использовавшихся ранее CMOS-элементов». Другими словами, NV стала использовать транзисторы, токи утечки которых превышали таковые для самых медленных «переключателей» из состава GF100, но были меньше, чем у быстрейших элементов. Опять же, точной информацией о применении тех или иных типов транзисторов в определенных блоках мы не обладаем, но именно использование подобной тройной комбинации позволило заметно снизить энергопотребление GPU без его замедления. Фактически, только благодаря тщательной работе по реконструкции имеющихся модулей с новыми «стройматериалами», GTX 580 при более высоких тактовых частотах и полноценном чипе имеет более скромный аппетит, чем GTX 480. Заметим, что число транзисторов в GF110 не изменилось на сколько-нибудь значимую величину, так что можно считать энергетическую эффективность GTX 580 настоящим достижением NVIDIA. Естественно, подход к оптимизации энергетических характеристик GPU должен быть комплексным, поэтому NVIDIA не ограничилась только лишь снижением токов утечки. Так, открытым оставался вопрос соответствия заявленного уровня TDP реальному тепловому пакету карты. Сегодня оба ведущих производителя определяют TDP своих графических процессоров, основываясь на работе в «реальных» приложениях и играх, причем политика NVIDIA здесь обычно более агрессивна. В любом случае, в мире AMD и NVIDIA таких синтетических программ, как FurMark и OCCT, попросту не существует. Ведь действительно проще окрестить подобные утилиты «вирусными», чем полностью переделывать подсистему питания плат в расчете на нагрузки, которые практически недостижимы при использовании обычного ПО.  Для GTX 580 NVIDIA избрала иной, строгий подход. На этих платах система защиты еще более интеллектуальна; она не просто стремится уберечь дорогостоящее оборудование от повреждений, определяя нагрев компонентов. Две выделенных микросхемы, показанные на фотографии ниже, раздельно измеряют, какой ток забирает карта через слот PCI-Express от материнской платы и через дополнительные PCIe коннекторы. Информация передается драйверу GTX 580, и тот в случае слишком большого аппетита карты планомерно замедляет ее, чтобы не выходить за рамки TDP. Такой тип защиты нов для видеокарт, но в центральных процессорах он успешно применяется на протяжении довольно длительного времени. NVIDIA не скрывает причины для внедрения подобной технологии в свои видеокарты: необходимость что-либо противопоставлять программам вроде OCCT и FurMark. Для конечного пользователя они действительно могут представлять опасность — ведь даже если аппаратная защита препятствует поломке видеокарты, теоретически возможны и другие побочные эффекты от чересчур большой нагрузки на БП. Благодаря предложенному NV методу, риск порчи самой платы или иных компонентов ПК минимизируется. В тоже время, на уровне PR своей продукции, NVIDIA, похоже, очень хочет избавиться от негативных отзывов о GeForce, получаемых ими в результате запуска на них того же FurMark. Ведь пускай даже подготовленный читатель и верно оценит чрезвычайно высокое энергопотребление Fermi при взгляде на графики с результатами FurMark, новичок не будет знать, что в реальных приложениях требования GPU существенно понизятся. С новой системой защиты даже в FurMark и OCCT аппетиты GF110 должны быть приемлемыми. Несмотря ни на что, мы до сих пор считаем эти утилиты отличным инструментарием для определения «худших сценариев», и считаем важным предоставлять нашим читателям данные, которые можно использовать для построения системы с некоторым запасом прочности. Однако сложно поспорить, что с позиции NVIDIA действия по обеспечению контроля за TDP нелогичны.
Интересно другое. Хотя для работы алгоритма необходимо определенное аппаратное обеспечение, решение о срабатывании принимается программно. И, похоже, что для конкретных исполняемых файлов программисты NVIDIA создали систему профилей, аналогичную применяемой в SLI. Так, согласно нашим исследованиям, при запуске FurMark и OCCT GTX 580 действительно замедляется. В то же время, существуют аналогичные, но менее известные программы, с помощью которых нам удалось имитировать сходное высокое энергопотребление. Естественно, если бы система была реализована только лишь на аппаратном уровне и не зависела от драйверов, подобного бы не случилось, и любые попытки вывести TDP за рамки дозволенных пресекались бы. На текущий момент это все только упрощает, так как тревожиться за неполноценное использование ресурсов GPU нет нужды. Однако без каких-либо «но» нам хотелось бы видеть в официальных драйверах какой-либо индикатор, в каком режиме находится графический процессор в данный момент. Дело в том, что, как и в случае с GDDR5 EDC, при разгоне троттлинг цепей питания очень сильно усложняет нахождение предела стабильности, так как нет никакого четкого обозначения момента срабатывания защиты. Платы AMD сбрасывают частоты моментально, однако драйвер NVIDIA продолжает рапортовать, что GPU работает на полной частоте и напряжении. Похоже, что NVIDIA использует какую-либо инструкцию вроде NOP или HLT для искусственного замедления GTX 580, и даже энтузиасты на данный момент не могут точно определить факт срабатывания защиты. Наконец, разобравшись со средним и максимальным энергопотреблением, инженеры NVIDIA обратили свое внимание на систему охлаждения GeForce GTX. Требовалось не только более производительное (по скорости рассеивания тепла) решение, но и более тихое. У GTX 480 кулер был, мягко говоря, не венцом технической мысли. Конечно, со своей прямой обязанностью с учетом необходимости распределения до 300 Вт тепла он справлялся, но методы при его проектировании были выбраны странные. Так, тепловые трубки существенно выступали за пределы печатной платы, а радиатор был прикрыт дополнительной металлической пластиной, о которую было легко обжечься, особенно при тестировании на открытом стенде. Пожалуй, самой лучшей деталью подобной СО стали отверстия в текстолите, перешедшие с GTX 295; они позволяли вентилятору забирать воздух с обеих сторон платы. Тем не менее, в целом СО была далека от идеала. Поэтому кулер GTX 580 был практически создан с нуля. Уже с первого взгляда на новый топ NVIDIA становится понятно, что это качественно новое решение. Первенец на базе GF110 не выглядит столь громоздко и неуклюже, как в свое время GTX 480, а конструкция охлаждения близка скорее к полностью закрытым кожухам серии GTX 200, чем к флагману предыдущего поколения. Выпирающие тепловые трубки вместе с «грилем» радиатора остались в прошлом, а при беглом осмотре GTX 580 и вовсе нетрудно перепутать с GTX 285. Все это стало возможным благодаря применению NVIDIA испарительной камеры вместо уже ставших традиционными тепловых трубок.
Испарительные камеры присутствуют на рынке в составе готовых решений довольно давно. Впервые в паре с GPU такой кулер массово устанавливался на ATI Radeon 2900XT, но сейчас по большей части подобные камеры можно встретить в предложениях сторонних компаний для энтузиастов оверклокинга. Кроме того, для Sapphire данная технология является в некотором роде эксклюзивом серии Vapor-X. Из недавних референсных дизайнов с использованием испарительных камер можно припомнить только Radeon HD 5970. Теперь и NVIDIA пошла по данной дороге, проектируя стандартное охлаждение для GTX 580. Это означает отказ от тепловых трубок, так как испарительная камера должна обеспечивать более эффективную передачу тепла от крышки теплораспределителя графического процессора на алюминиевые пластины радиатора. Кроме очевидного плюса равномерного нагрева радиатора, это одновременно ведет и к уменьшению скорости вращения радиального вентилятора, так как необходимости в максимизации разницы температур между радиатором и GPU больше нет. Еще одним изменением стала модернизация самого вентилятора. Трудно не согласиться, что из-за свиста воздуха он является основным генератором шума в СО. Исследования NVIDIA показали, что применяемая на GTX 480 модель подвержена резонансным колебаниям, из-за которых возникают дополнительные децибелы громкости и неприятный высокочастотный свист. Теперь кулер снабжен дополнительным пластиковым кольцом, призванным снизить вибрации. Опять же, как и испарительная камера, это решение не является первым в своем роде (посмотрите на конструкцию HD 5800), но именно на GTX 580 оно было применено NVIDIA в референсном дизайне.
Наконец, отметим и оптимизированную для лучшего направления воздушного потока форму пластикового кожуха карты. Помимо небольшого расширения пространства у вентилятора для лучшего забора воздуха (при близком соседстве с прочими картами), в GTX 580 кожух сделали клиновидным. По словам NV, это улучшает циркуляцию воздуха вокруг установленных в SLI плат. [N4-Знакомство с GTX 580] Систему охлаждения новинки мы уже подробно рассмотрели, давайте же теперь взглянем и на прочие особенности флагмана GF110. На данный момент была представлена всего одна карта семейства GTX 500, а именно имеющая только референсный дизайн PCB GTX 580. В ближайшие недели станут доступны модернизированные партнерами NV версии с сохраненной печатной платой, но измененным кулером. В этом контексте особенно интересным выглядит решение, принятое NVIDIA о проведении обязательных тестов для предложений вендоров с СО, отличными от стандартной. На нашей памяти такое происходит впервые: компания постановила, что на рынок не будут допущены изделия, обладающие худшими акустическими и температурными показателями, чем у стандартного кулера. Мы считаем этот шаг очень правильным для защиты репутации бренда. Ведь громкий, некорректно спроектированный производителем самостоятельно GeForce (это не относится к GTX 580, но справедливо в целом) все равно остается GeForce.
Результирующая референсная карта оказалась очень похожей на гибрид GTX 285/480. От первой ей достался общий вид системы охлаждения, от второй — PCB. Длина новинки составляет 26,67 см, что полностью совпадает с соответствующим геометрическим измерением GTX 480 и несколько превышает длину GTX 285. Особых трудностей с установкой даже в средние компьютерные корпуса не предвидится. Что касается разъемов питания, TDP в 244 Вт определяет необходимость в схеме PCIe подключения 8 + 6 контактов (можно предположить, что будущей GTX 570 будет достаточно и упрощенной пары 6 + 6). Коннекторы располагаются сверху; это облегчает их подключение. Еще одним положительным моментом в конструкции охлаждения является возможность легкого снятия пластикового кожуха (например, для очистки радиатора от пыли) без затрагивания прочих элементов, причем в этот раз вместо ненадежных пластиковых крепежных элементов проектировщики решили использовать обычные винты.
На передней стороне PCB расположено 12 чипов GDDR5, которыми и набирается 384-битная шина. К сожалению, термопрокладки сделали надписи на микросхемах нечитаемыми, так что мы затрудняемся определить производителя и модель. Впрочем, точно известно, что, как и в GTX 480, используются 5 Гбит/с модули. В центре печатной платы располагается массивный GF110, прикрытый теплораспределителем. Это вполне стандартная для современных high-end решений NVIDIA картина. На нашем тестовом экземпляре был установлен чип ревизии A1, что во внутренней системе обозначений NV соответствует первому коммерческому степпингу. Кроме того, на плате находятся 2 коннектора для организации tri-SLI из GTX 580. Заметим, что разводка PCB не претерпела практически никаких изменений относительно GTX 480. Лишь от сквозных вентиляционных отверстий инженеры отказались, да немного упростили цепи питания GPU благодаря уменьшившемуся энергопотреблению/тепловыделению.   Как мы уже отмечали ранее, прямого соперника для GTX 580 у AMD нет. Ближайшими решениями, подходящими под определение конкурента GF110, являются две 6870 в CrossFire, либо двухчиповая 5970. Интересно и то, что цены на GTX 470 опустились до такого уровня, что можно приобрести пару данных видеокарт по цене GTX 580. А ведь схватка двух немного урезанных плат GF100 с одной, пускай и полноценной GF110, не будет слишком «честной»...
| ||||||||||||||||||||||||||||||||