В противоположность тому, что компания AMD продвигает технологию
hUMA как очередной революционный этап в развитии методов обработки данных, один из старших программистов в компании по разработке игр заявил о том, что не усматривает ценности новой архитектуры AMD. Как известно, для AMD и её фанатов архитектура hUMA (Heterogeneous Unified Memory Architecture) является революционным решением, по значимости сопоставимым с появлением APU AMD, т.е. чипов со встроенным видео.
В
процессорах AMD с интегрированной графикой (APU) общевычислительные и графические ядра расположены на одном кристалле, способствуя повышению вычислительной производительности благодаря тому, что в теории исполнение последовательной нагрузки процессорного компонента (CPU) ускоряется за счёт хорошо распараллеленных потоков графического компонента (GPU), обеспечивая невероятный прирост общей производительности в операциях с плавающей запятой. Однако эта совместная работа имеет врождённый недостаток: скорость движения такого конвейера ограничена задержками обращения к памяти ввиду раздельного сосуществования пула памяти для CPU и GPU. Работая в параллельном режиме, CPU- и GPU-сегментам приходится «пулять» данные туда-сюда между разными адресными пространствами с негативными последствиями в виде снижения производительности.

Технология AMD hUMA, по-видимому, призвана устранить падение эффективности путём создания единого адресного пространства памяти для GPU и CPU. Гипотетически наличие единого адресного пространства обеспечит гармоничный параллелизм, позволяющий CPU и GPU брать на себя выполнение только оптимальных для себя задач. На выставке Computex – 2013 представитель AMD Лиза Су (Lisa Su) расхваливала достоинства hUMA, обещая огромный прирост производительности в игровых приложениях как наиболее типичном для рядового пользователя примере взаимодействия
процессора с
видеокартой.
Всё бы ничего, но один программист решил высказать особое мнение. В электронном письме, направленном в адрес сайта VR-Zone, разработчик из Epic Games Тим Суини (Tim Sweeney) высказался в том смысле, что различия в языках программирования для СPU и GPU будут препятствием даже в случае с hUMA.

Ребята с VR-Zone обратились за комментариями к AMD, и вот что в этой связи сказал Фил Роджерс (Phil Rogers), специалист в области гетерогенных вычислений:
Судя по всему, Тим Суини, как и AMD, имеет чёткое представление о целях HSA на будущее: это единый источник и программы на языке высокого уровня с возможностью исполнения как средствами CPU, так и средствами GPU. Это как раз то, что, в конечном счёте, позволит Тиму и тысячам других программистов упростить написание софта с поддержкой аппаратного ускорения средствами HSA. Именно это является целью создания платформы HSA – объединение адресного пространства, обеспечение полной согласованности в работе памяти и расширение многопоточного потенциала GPU для полноценной поддержки C++. Мы заново изобретаем гетерогенную платформу с целью ликвидации всех барьеров, препятствующих оптимизации исполнения программ на C++ / Java за счёт перекладывания груза параллельных вычислений на плечи GPU.
Тим прав, когда говорит, что одного появления платформы HSA недостаточно, ведь обеспечение лёгкого доступа к возможностям ускоренного выполнения кода за счёт GPU требует ещё и совершенствования модели программирования. Появление OpenCL 2.0 и C++ AMP – большой шаг вперёд в этом направлении благодаря тому, что OpenCL 2.0 позволяет использовать единое адресное пространство и обеспечивает согласованное функционирование памяти, а C++ AMP реализует подход на базе принципа единого источника, когда добавление всего двух новых ключевых слов – “restrict” и “arrayview” – позволяет с помощью отдельных методов осуществлять компиляцию кода для исполнения на CPU и GPU, по возможности разгружая соответствующие ресурсы. Платформа HSA будет способствовать дальнейшему развитию обеих моделей программирования в направлении перехода к «чистой» модели программирования на языке C++ как наиболее понятном программисту инструменте.
Код и экономика
Программист из Epic Games задал хороший вопрос: какова экономическая целесообразность проекта hUMA? AMD от ответа уклонилась.
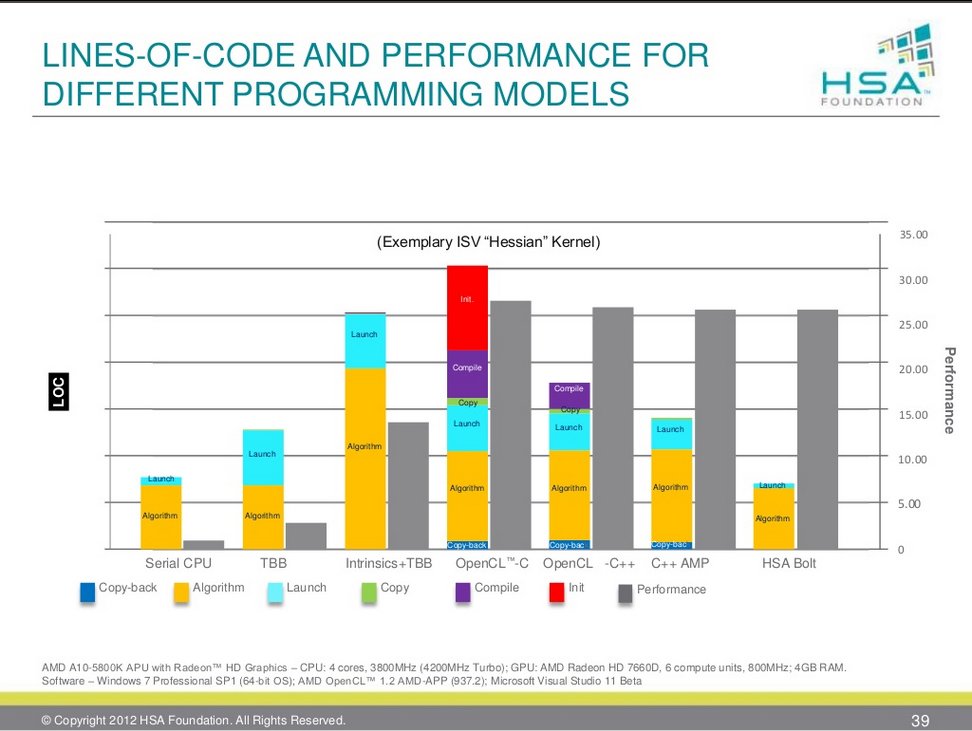
Как следует из представленного слайда, усложнение процесса кодирования в рамках платформы hUMA обеспечивает лишь незначительную отдачу в плане производительности. Применение аналогичной hUMA архитектуры в
Playstation 4 позиционируется как преимущество этой
игровой консоли следующего поколения над конкурирующими решениями. Однако тот факт, что некоторые разработчики не торопятся представить конкретные цифры в подтверждение реальных преимуществ hUMA, в лучшем случае вызывает сомнения относительно достоверности утверждения о революционной роли внедрения hUMA, по значимости сопоставимой с выходом APU.