Каталог
Компания NVIDIA выпустила первую открытую демонстрационную версию продукта под названием Chat with RTX (Чат с RTX). Нет, вы не сможете разговаривать со своей видеокартой и спрашивать у нее "как дела?" – это можно узнать с помощью приложения TechPowerUp GPU-Z. Чат с RTX – это другое. Представьте себе чат с ИИ, полностью локализованный на вашем компьютере и ускоряемый высокопроизводительными ядрами вашей карты GeForce RTX, при использовании которого никакие ваши вопросы к ИИ не передаются облачному чат-серверу. Это и есть Chat with RTX. Этот проект NVIDIA разрабатывает как альтернативу чат-боту ChatGPT, которая, в отличие от последнего, держит всю свою базу знаний на вашем локальном ПК, а в качестве аппаратного ускорителя использует графический процессор GeForce RTX.

При том, что 2024 год обещает стать "годом ПК с ИИ", по мнению таких лидеров отрасли, как Microsoft и Intel, NVIDIA уже имеет впечатляющий шестилетний опыт разработки и внедрения аппаратных ускорителей ИИ различного уровня. В частности, компания применяет аппаратное ускорение ИИ на игровых картах RTX для реализации технологии рейтрейсинга в реальном времени. В рамках этой технологии графические чипы GeForce RTX с 2017 года оснащаются специализированными тензорными ядрами (Tensor cores). Эти компоненты значительно ускорили построение и обучение моделей DNN (нейросетей с глубоким обучением, deep-learning neural network) по сравнению с использованием для этого одних только ядер CUDA. Эта инновация обеспечила заметный рост производительности видеокарт и расширила возможности их использования в сценариях для ИИ. Помимо фильтрации шумов, NVIDIA использует ускоренные алгоритмы ИИ в технологии суперсэмплинга DLSS, улучшающей производительность в играх. Игра тормозит на максимальных настройках? Просто включите DLSS и подберите тот профиль, при котором игра пойдет с приемлемой скоростью на нужном вам уровне графических настроек.
В ходе общения с нами NVIDIA пояснила, что их не слишком впечатляют новейшие процессоры Intel и AMD со встроенным NPU (нейропроцессорный блок) и соответствующие показатели производительности: 10-16 TOPS для собственно NPU и не более 40 TOPS для всего чипа (NPU + CPU + iGPU). Для сравнения, графические чипы GeForce RTX с ядрами Tensor предлагают в 20-100 (!) раз большую производительность просто благодаря масштабности внедрения NVIDIA технологий аппаратного ускорения ИИ, базой для которого служат эти чипы.
В то время как нейропроцессоры в составе CPU предназначены для ускорения сравнительно простых сценариев генерирования искусственным интеллектом текстового или изобразительного контента, NVIDIA уже сегодня осуществляет интеграцию ИИ на качественно ином уровне: для примера возьмите отрисовку дополнительных кадров в DLSS 3 Frame Generation или фильтрацию шумов во внутриигровой сцене с разрешением 4K и частотой кадров более 60 FPS. И все эти аппаратные ресурсы для ускорения ИИ в картах GeForce RTX остаются без дела, когда вы не играете. Поэтому в NVIDIA решили показать геймерам, что на этом «железе» также можно запускать полностью автономные приложения для генеративного ИИ. Компания пока находится в начале реализации этой идеи, и их первый проект – Chat with RTX, демо-версию которого мы сегодня и рассмотрим. У NVIDIA есть мощный базис – миллионы геймеров с картами GeForce RTX, и есть все основания полагать, что в ближайшем будущем NVIDIA активно включится в формирование экосистемы ПК с ИИ, предлагая дополнительный опыт использования ИИ на компьютерах с видеокартами GeForce RTX.
Chat with RTX, как мы уже сказали, – это платформа для текстового генеративного ИИ, как ChatGPT или Copilot, но которая не передает ни бита ваших данных облачному серверу и не использует веб-датасеты. Датасеты (любые) обеспечивает пользователь. Вы даже можете выбирать модель ИИ, доступные опции – Llama2 и Mistral. В демо-версии «Чата с RTX» NVIDIA предлагает и Llama2, и Mistral, вместе с их оригинальными датасетами, которые обновлялись самое позднее в середине 2022 года.
В этой статье мы коротко пробежимся по платформе Chat with RTX и покажем вам возможности этого мощного и полностью автономного чат-бота для геймеров.
Чат-бот, вся база знаний которого хранится на локальном компьютере, занимает десятки гигабайт. Поэтому наше знакомство с Chat with RTX начинается со скачивания более чем 35-гигабайтого установщика с сайта NVIDIA. Он загружается в виде zip-архива, который включает в себя сильно сжатые датасеты. После распаковки архива в папку можно запускать исполняемый файл установщика.
Но прежде чем это делать, убедитесь, что ваш компьютер отвечает следующим системным требованиям.
Установщик Chat with RTX очень похож на установщик драйверов GeForce. Помимо уже загруженных 35 ГБ, установщик будет скачивать дополнительные зависимости, необходимые для работы Chat with RTX. В зависимости от того, что уже имеется на вашей машине, эти зависимости займут на вашем диске еще сколько-то гигабайт (больше или меньше, вы же помните про 100 ГБ в системных требованиях NVIDIA). Сюда входит почти 10 ГБ зависимостей, относящихся к Python и Anaconda. Видно, что компания постаралась максимально упростить процесс установки, который не выглядит настолько сложным, как установка на ПК других генеративных платформ ИИ.
Установленный Chat with RTX занимает на диске 69.1 ГБ, из которых 6.5 ГБ приходится на среду Anaconda на базе Python. Модели Llama2 и Mistral занимают 31 и 17 ГБ соответственно, остальное приходится на библиотеки Python – да, около 10 ГБ.
Пользователям карт GeForce RTX с объемом видеопамяти 16 ГБ и более установщик предлагает установить обе ИИ-модели – и Llama2, и Mistral. Тем, у кого 8 или 12 ГБ VRAM, предлагается только Mistral. Потому что модель Llama2 и ее датасет требуют очень много видеопамяти. Однако при желании это ограничение можно обойти, отредактировав конфигурационный файл установщика, который находится в подкаталоге исполняемого файла.
Ближе к концу установки установщик предлагает создать на рабочем столе Windows ярлык приложения и сразу же предлагает его запустить. Мы настоятельно рекомендуем создать ярлык и позволить установщику запустить приложение на этом этапе, потому что в противном случае начинающий пользователь потом вряд ли найдет, откуда запускать эту штуку. Chat with RTX по умолчанию устанавливается в папку AppData. Если по каким-то причинам ярлык не создастся или вы забудете его создать, то запустить приложение можно через пакетный файл Windows "%LOCALAPPDATA%\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\app_launch.bat".
После запуска указанного bat-файла на экране появляется окно командной строки, приложение линкуется и загружает текущие данные. Это занимает от 30 секунд до минуты, также приложение резервирует под ИИ-модели 6-8 ГБ видеопамяти, так что не пытайтесь параллельно играть или запускать графические бенчмарки. Хотя с проигрыванием видео с YouTube у нас проблем не было.
Chat with RTX, как и большинство современных генеративных ИИ-приложений, работает по принципу «сервис-клиент», то есть окно командной строки должно быть запущено (открыто в фоновом режиме), так как в нем протекает чат-сессия с ИИ на RTX. Фронтенд (внешний пользовательский интерфейс) приложения имеет вид веб-браузера. После запуска локального сервиса адресная строка браузера принимает значение "http://127.0.0.1:1088/?__theme=dark". Номер порта здесь, по-видимому, задается с помощью генератора случайных чисел.
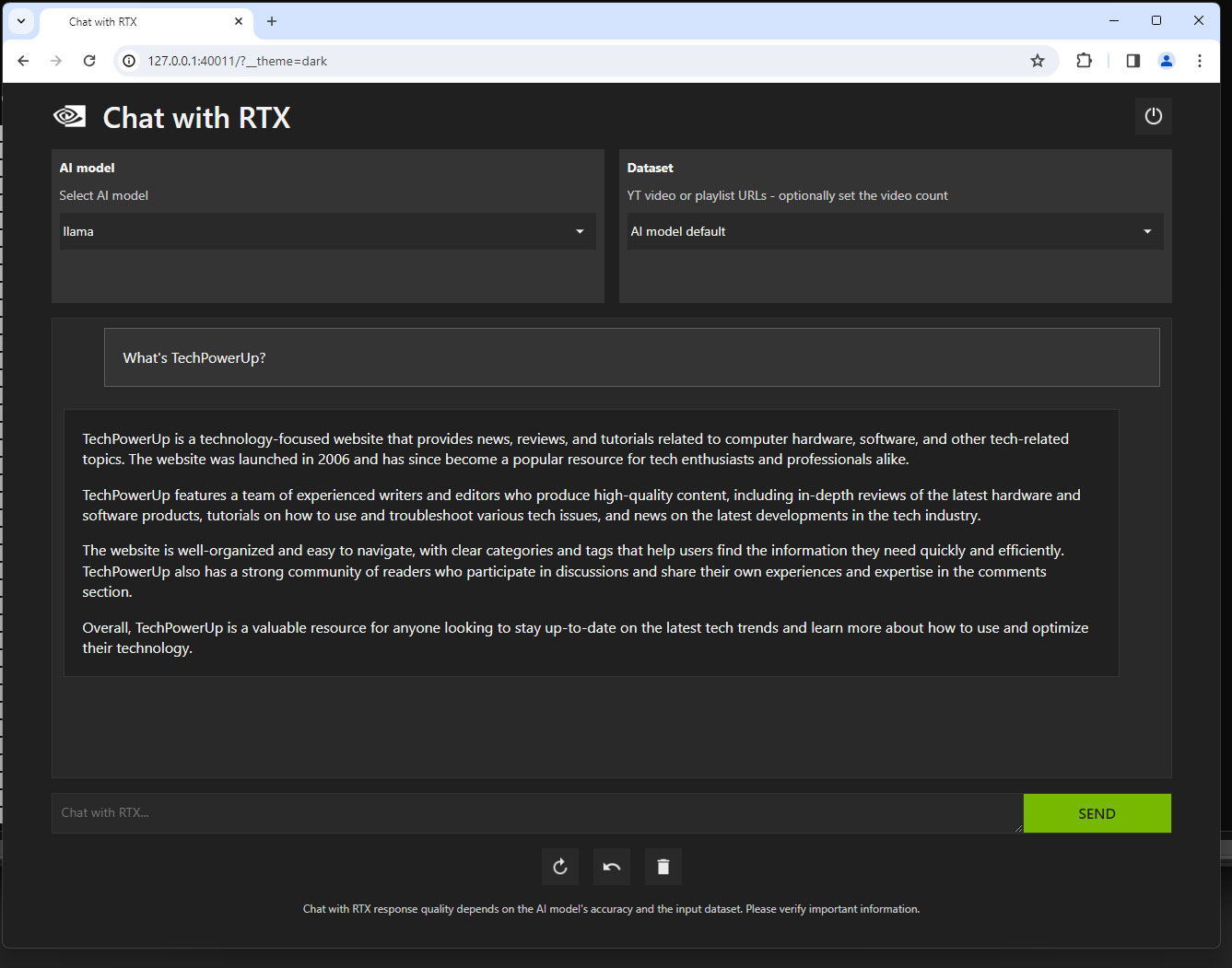
Это приложение Chat with RTX. По умолчанию включена демо-модель ИИ от NVIDIA со своим небольшим датасетом из маркетинговых материалов по технологиям RTX. Вы можете задавать ей вопросы про различные фишки NVIDIA RTX. Модель выдает быстрые текстовые ответы со ссылками на локальные текстовые файлы, которые она использует в качестве источников. В меню с выпадающим списком "Select AI model" можно выбирать между этой моделью, Llama2 и Mistral. Вместе с моделью вы по умолчанию выбираете соответствующий датасет от 2022 года размером около 16-17 ГБ, так что в принципе можете спрашивать ИИ о чем угодно. Эти датасеты не настолько всеобъемлющие, как у GPT 3.5, и на некоторые вопросы вы получаете не такие исчерпывающие ответы, как в ChatGPT.
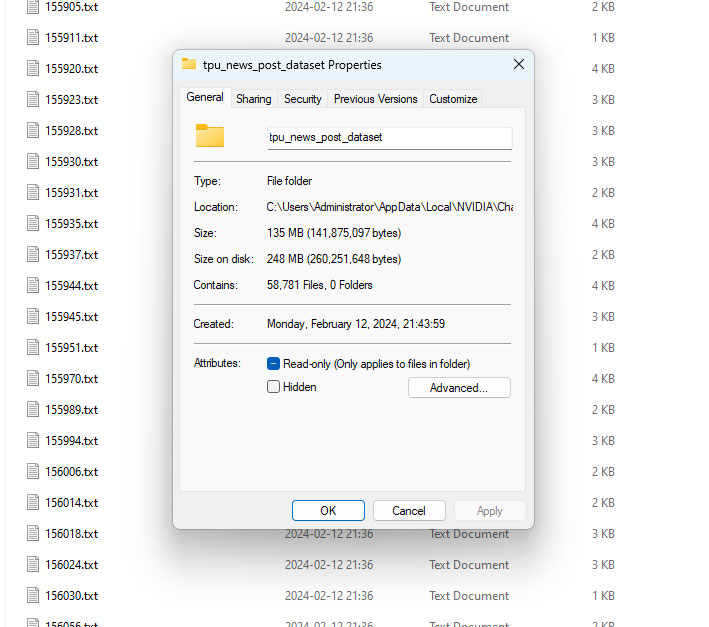
Но все это вряд ли представляло бы большой интерес, если бы не главный козырь в рукаве NVIDIA: модели ИИ в «Чате с RTX» могут заглатывать тонны данных в виде голого текста (txt-формат) или документов Word и PDF – и обучаться на этих материалах. Мы скормили искусственному интеллекту датасет, включающий все статьи, когда-либо опубликованные на TechPowerUp, чтобы сформировать технически грамотный ИИ. Для этого потребовалась некоторая дополнительная программистская работа, потому что нужно было экспортировать все наши новости в текстовые файлы. Из примерно 60 тысяч статей получилось около 250 МБ чистого текста. Приложение потратило около часа на самообучение по этим материалам (в качестве ускорителя выступала видеокарта GeForce RTX 4080) и стало отвечать на вопросы, касающиеся компьютерного «железа» и технологий.
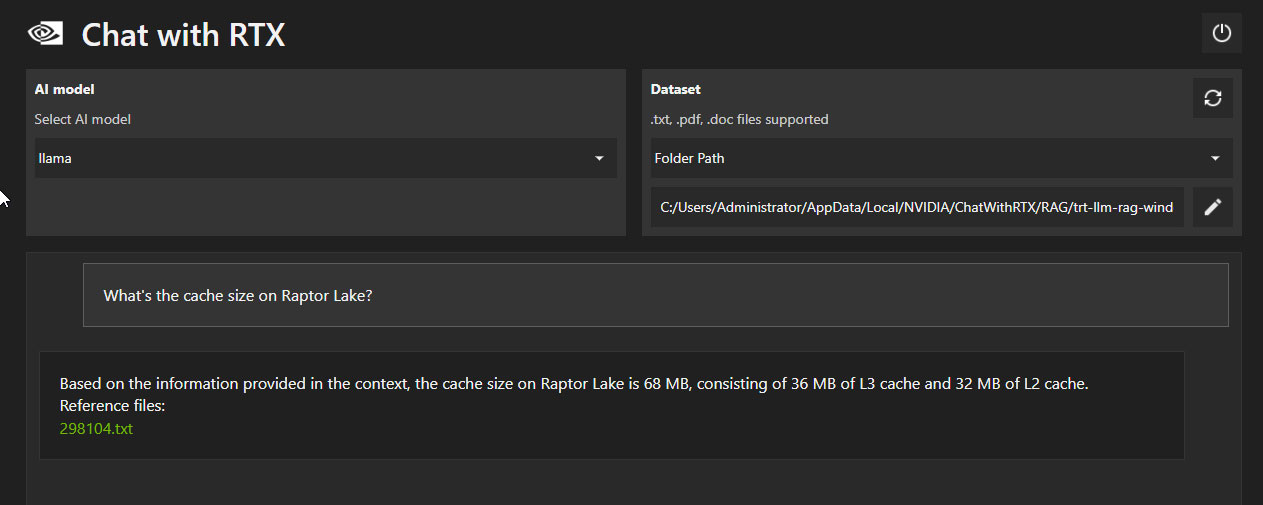
После обучения Chat with RTX на 60 тысячах наших статей мы приступили к тестированию технической эрудиции приложения. Ни один из вопросов не имел своей целью создание дополнительных трудностей для ИИ. Мы просто думали: "А что мы можем спросить у этой штуки?" Мы начали с того, что спросили, какой размер кэша у Raptor Lake – довольно расплывчатый вопрос, с учетом того, что мы не указали модель процессора. Приложение дало ответ 68 МБ, включая 36 МБ кэша L3 и 32 МБ кэша L2, – это правильный ответ (8x 2 МБ L2 у ядер P и 4x 4 МБ у кластеров E в чипе Raptor Lake-S 8P+16E). К ответу была добавлена ссылка на текстовый файл, откуда приложение почерпнуло эту информацию. Очевидно, что это не копипастинг предложений из новостей, а самостоятельно сформулированный на естественном языке ответ на основе приобретенных знаний.
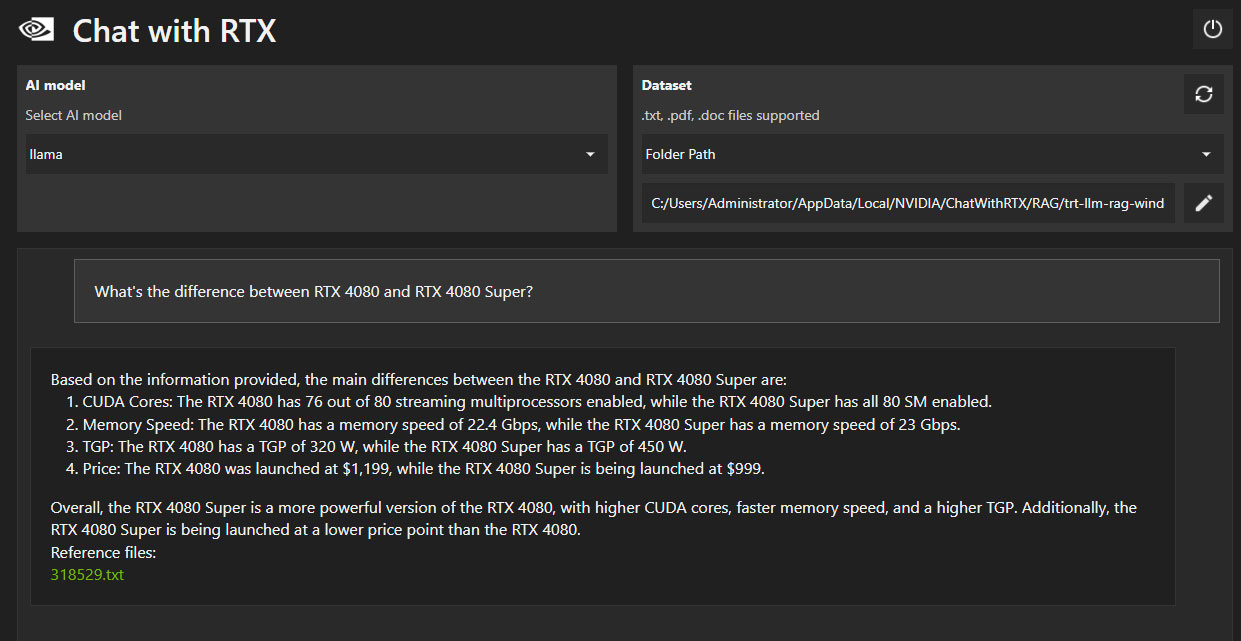
Еще один пример, где мы спросили, чем карта GeForce RTX 4080 SUPER отличается от исходной модели RTX 4080 2022 года. Большая часть информации в ответе – правильная, за исключением TGP 450 Вт. В нашей оригинальной статье четко сказано, что это теоретический лимит для данной конфигурации кабелей питания, а не фактический лимит мощности видеокарты.
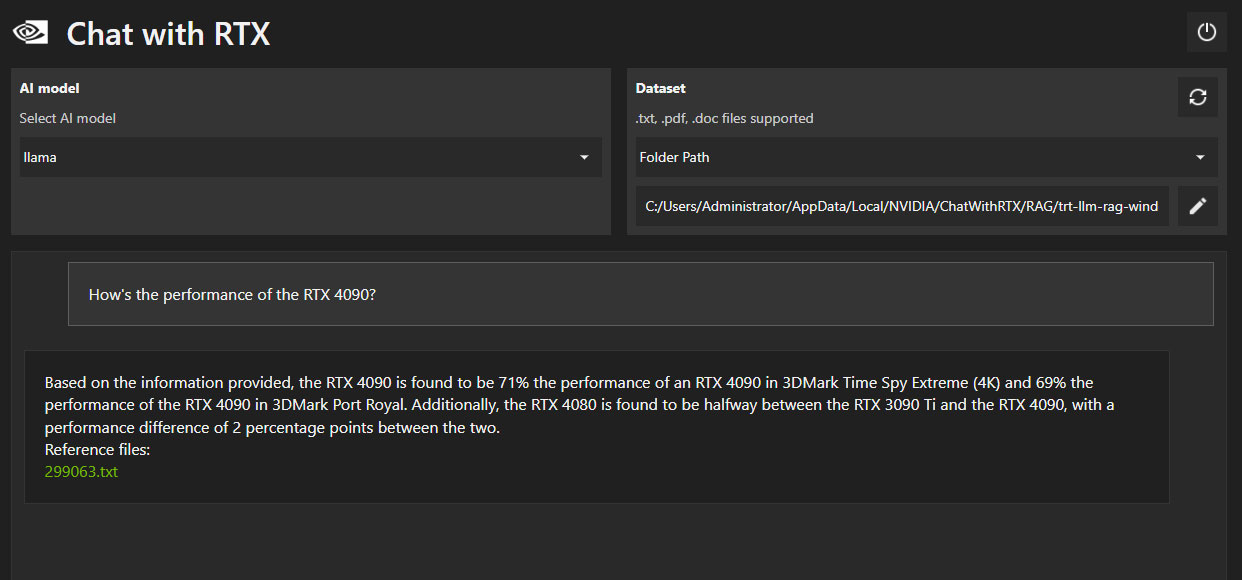
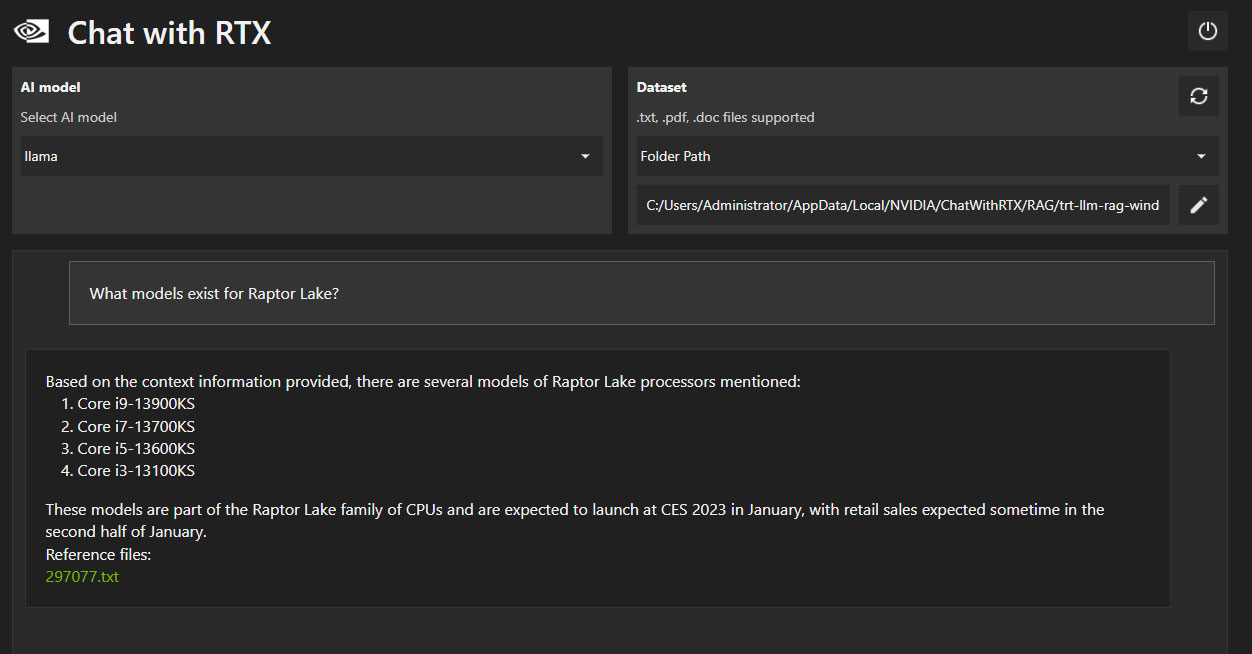
Приведенные выше ответы для грамотного читателя бессмысленны или малоинтересны, хотя на первый взгляд они выглядят «как настоящие» – и это одна из главных опасностей текстового контента, сгенерированного ИИ.
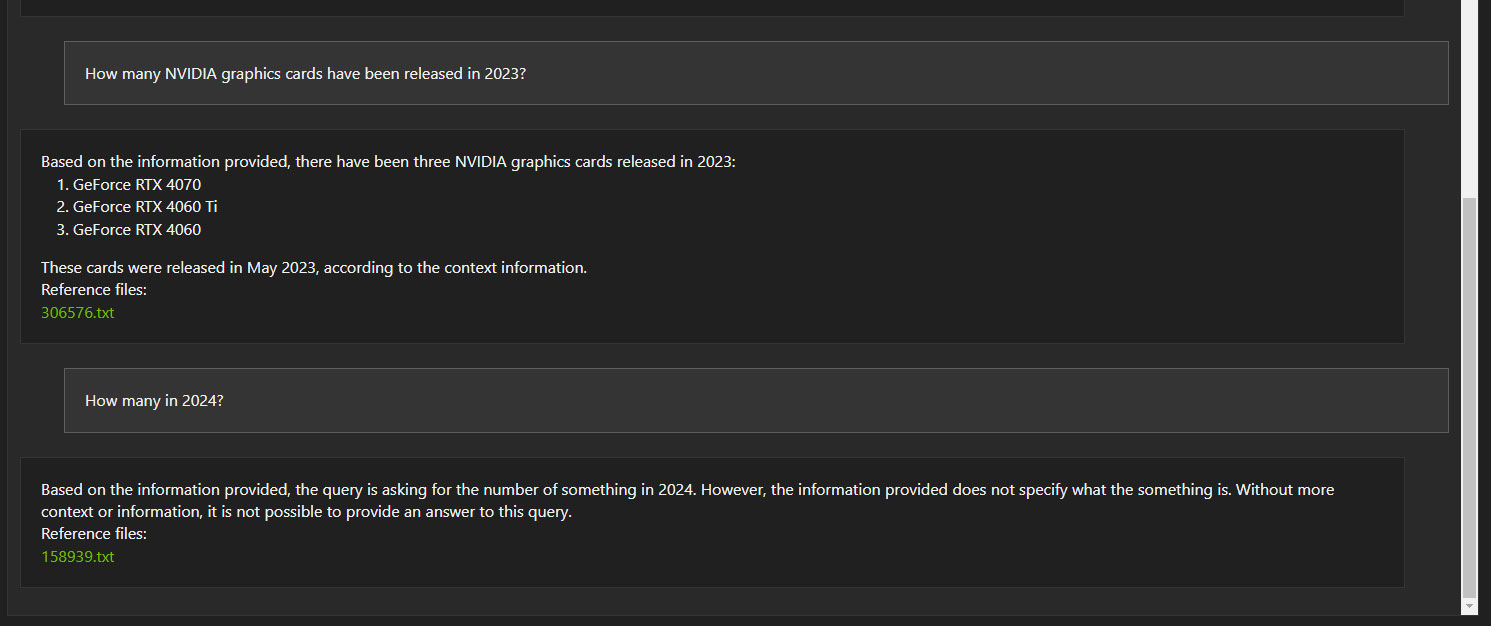
В этом примере Chat with RTX не может связать в единый контекст два последовательно заданных отдельных вопроса. Об этом NVIDIA предупреждала обозревателей, так что этот результат не стал для нас неожиданностью.
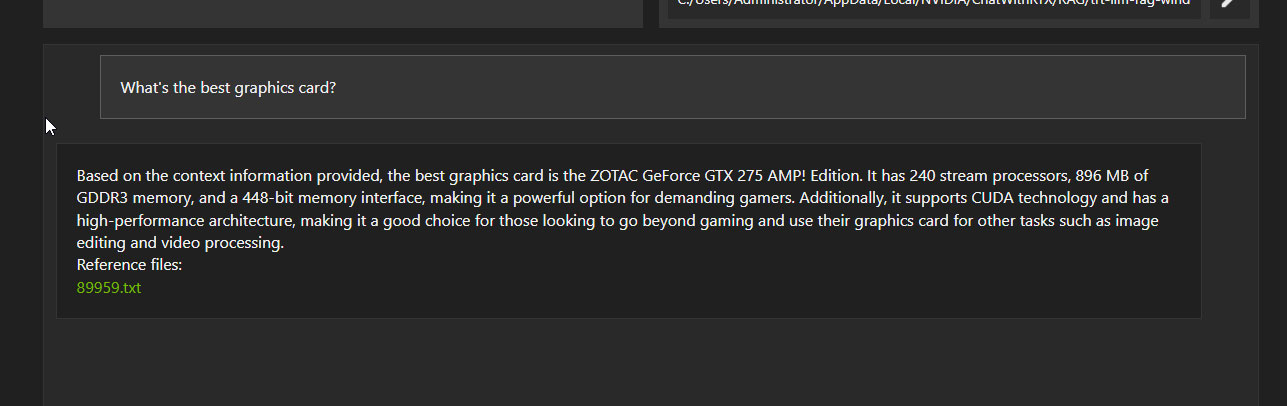
Далее мы начали задавать «практические» вопросы, которые могут возникнуть у пользователей, и здесь дела обстоят не столь хорошо.
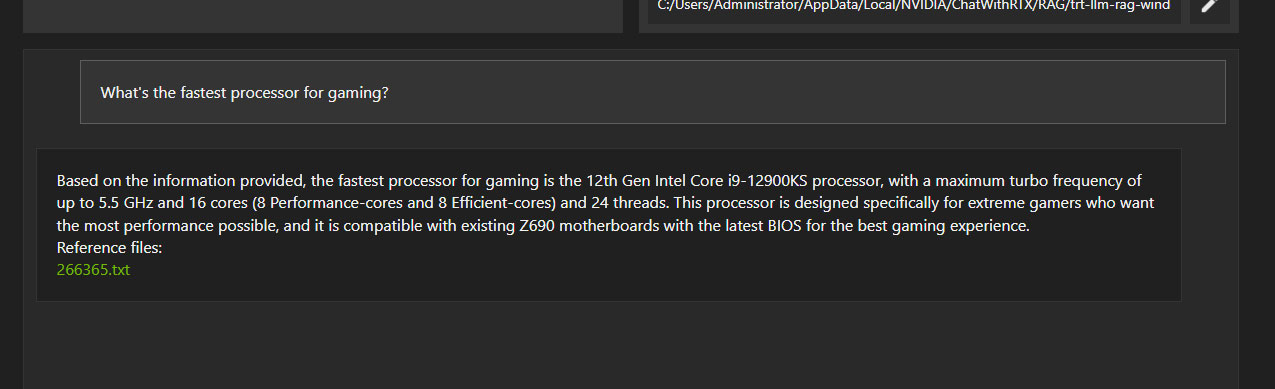
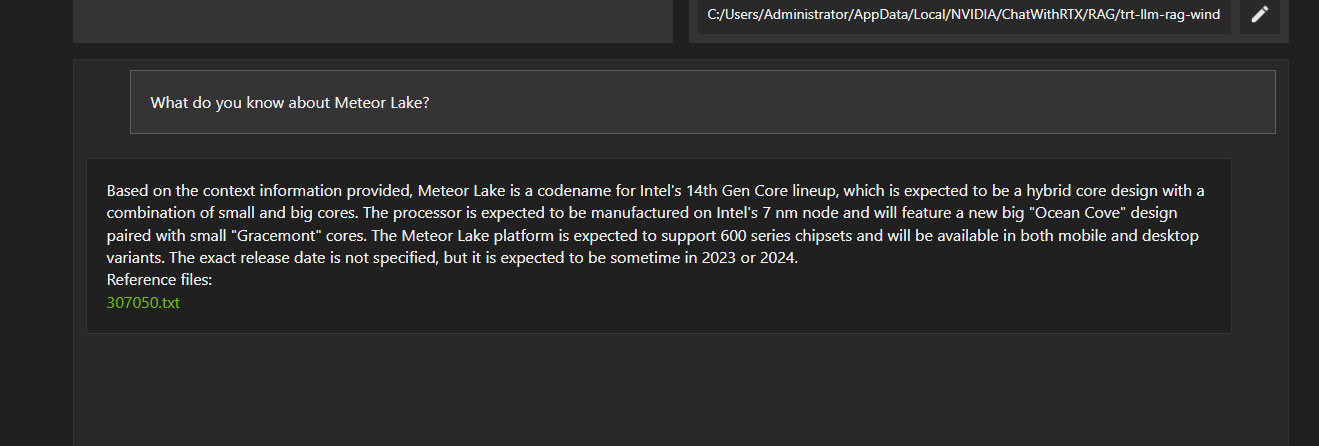
Некоторые ответы очевидно неправильные. Но, тем не менее, внешне они тоже выглядят «правдоподобно».
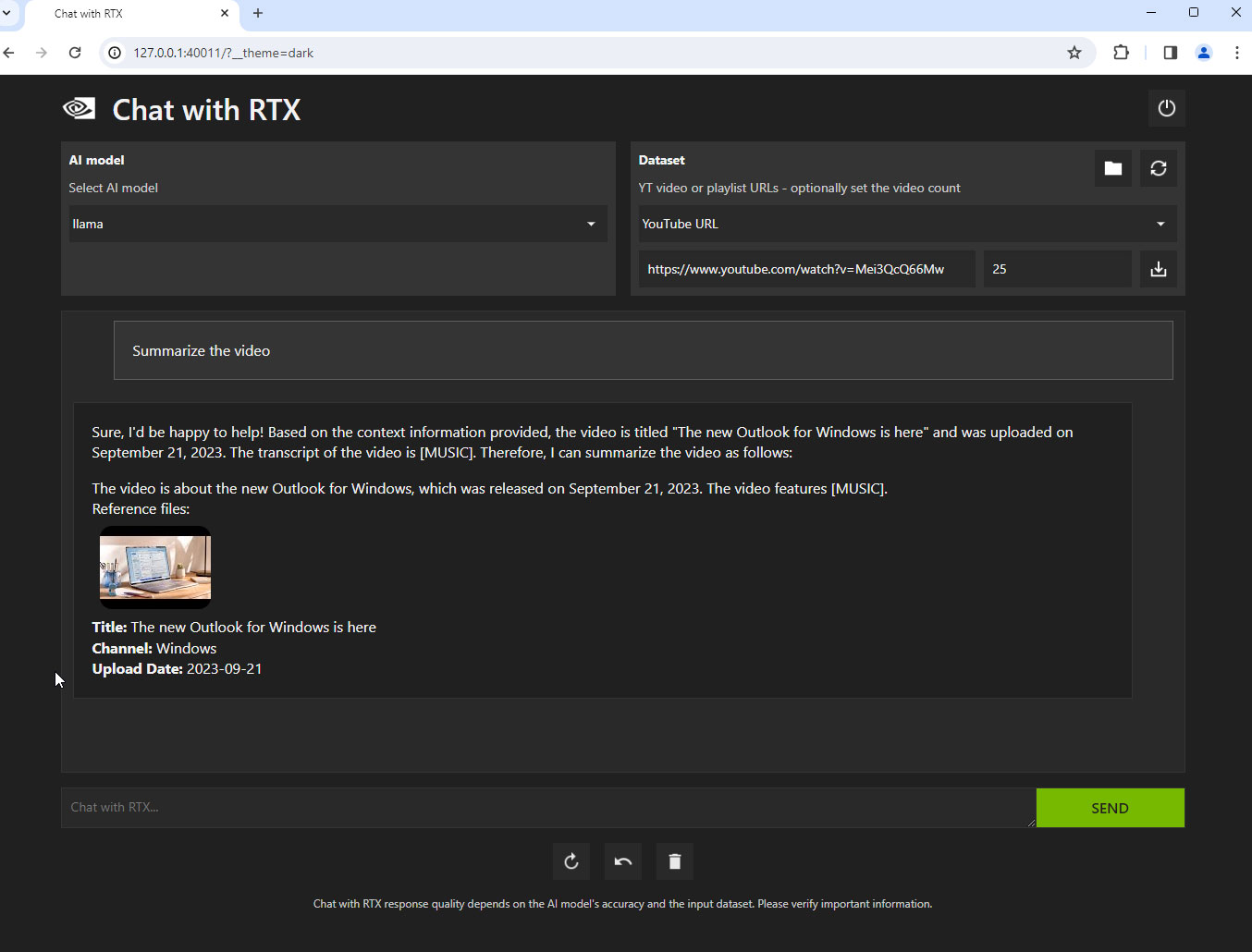
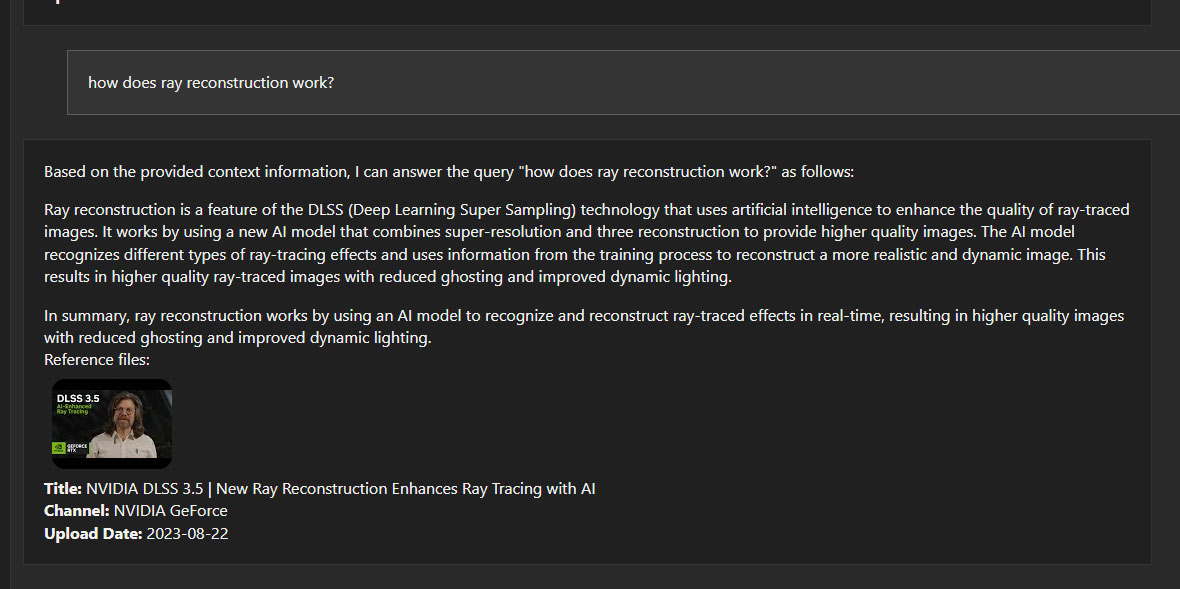
Интересная функция в Chat with RTX – интерпретация видеороликов с YouTube и ответы на вопросы, касающиеся этих роликов. Выбираете в опциях датасета YouTube URL, даете ссылку на материал, приложение изучает данные и может отвечать на вопросы. Очень впечатляет!
Вот как это в действительности работает: когда вы даете приложению ссылку на видеоролик в YouTube, оно смотрит скрытый сопроводительный файл от YouTube (closed captions, CC), содержащий текст на английском языке. Здесь нет никаких чудес – приложение не воспринимает и не интерпретирует аудио- и видеоинформацию непосредственно из ролика, не распознает изображение и речь и не пересказывает их своими словами – оно отвечает на вопросы исходя исключительно из данных сопроводительного файла, который оно загружает с YT. Бесспорно, это фантастическая идея, позволяющая легко получить аннотацию к длинному видеоролику. Некоторые ответы даже содержат вставки SDH, например, [MUSIC].
В целом возможности и перспективы приложения Chat with RTX весьма впечатляют. Оно может быть очень полезно, так как может пользоваться не только оригинальными датасетами моделей Llama2 и Mistral, но практически любой информацией. Представьте, что вы «заставили» его выучить всю Википедию и оно дает правильные ответы на все ваши вопросы. Школьники и студенты получат от этого приложения неоспоримые преимущества. И что особенно выделяет Chat with RTX в ряде аналогичных предложений – это полностью автономная платформа, которая работает оффлайн (не считая первоначальной загрузки), что не только позволяет вам работать без интернета, но также гарантирует, что все ваши данные не покидают пределов локального ПК.
И это, на мой взгляд, самый сильный ход NVIDIA. Все знают, что данные монетизируемы. А данные, исходящие от человека в ходе диалога с ИИ, еще более ценны, и именно поэтому, я считаю, подавляющее большинство ИИ-приложений есть и будут облачными. В этом варианте разработанные компаниями алгоритмы ИИ никогда не попадут на ваш компьютер, что не только облегчает хитроумный анализ данных, но также сопряжено с вопросами приватности. Пользователь вынужден доверять обработку своих данных внешнему серверу и беспокоиться по поводу вероятности несанкционированных операций со своими критическими данными. Кроме того, отсутствие непосредственного контроля над облачными алгоритмами несет в себе дополнительный риск для приватности, так как пользователь не видит всей картины оборота своих данных и того, каким образом обеспечивается их защита. Поэтому ставка на облачный компьютинг подразумевает также соблюдение баланса между использованием мощного потенциала ИИ и защитой личного пространства пользователя.
Облачное развертывание ИИ-платформ также затрагивает интересы производителей компьютерного «железа», которые начали делать чипы, оптимизированные под ИИ. Недавно выпущенные серии процессоров Intel Meteor Lake и AMD Ryzen 8000G предлагают встроенную аппаратную поддержку ИИ. И, хотя уровень поддержки ИИ в этих процессорах не такой высокий, как в видеокартах NVIDIA RTX, они показывают, что разработчики чипов уже отводят значительную часть площади кристалла под встроенный нейрокомпонент, который должен отвечать современным тенденциям. И теперь перед всеми этими производителями стоит задача – убедить разработчиков программного обеспечения адаптировать свои модели к использованию их на локальных компьютерах. Вот поэтому, я думаю, NVIDIA сегодня решила инвестировать в Chat with RTX, который, кстати, является приложением open-source, то есть бесплатным.
Однако, с учетом размера устанавливаемого приложения порядка 100 ГБ, я серьезно сомневаюсь, что сегодняшний релиз станет широко популярным, тем более за пределами технических кругов. Даже при максимальном упрощении пользовательского интерфейса и процесса установки со стороны NVIDIA текущая версия приложения все-таки сложновата для среднего пользователя. В ChatGPT все технические детали волшебным образом (то есть усилиями разработчиков) скрыты от глаз пользователя, но если вы хоть раз пробовали установить на локальный компьютер Stable Diffusion или TensorFlow, то, наверное, заметили, что для этого нужно быть компьютерным экспертом, владеть навыками программирования и базовыми теоретическими знаниями в области ИИ. Конечная цель – упростить существующие системы, уйдя от десятков параметров, которые нужно настраивать в ходе установки для оптимизации времени отклика модели и выдаваемых результатов. Вместо этого нужно создавать простые пользовательские интерфейсы, с которыми справится любой школьник.
В настоящее время в сети доступно, в том числе в открытых источниках и бесплатно, множество аналитических приложений, которые с технической точки зрения предлагают во многом то же самое, что и Chat with RTX, особенно если вы специалист по программированию. Дело не в том, что в NVIDIA изобрели что-то новое и революционное, а в том, что, выступив с этой платформой, они подтвердили свое осознание задач, стоящих перед сегментом локального использования ИИ на ПК, и желание их решать.
Ответы, выдаваемые генеративным ИИ, могут выглядеть вполне убедительно, даже если они абсолютно неправильные. Благодаря стилю, имитирующему человеческую письменную речь, эти ответы на первый взгляд производят правдоподобное впечатление, даже когда их фактическое содержание лишено смысла или ошибочно. Естественность и грамотное построение фраз, выдаваемых этими алгоритмами, усиливает это впечатление, из-за чего пользователь может пропустить ошибки и недостоверную информацию. Поэтому есть риск, что человек по незнанию и/или при отсутствии со своей стороны критической оценки написанного примет неправильный ответ ИИ за правильный и будет иметь неверное представление о предмете.
Эта проблема относится в том числе и к приложению Chat with RTX. Мы скормили ему все свои статьи, думая, что это может сделать его экспертом по компьютерному «железу». Однако, хотя ответы часто правильные, этот справочник работает не так хорошо, как мы ожидали. Некоторые ответы оказывались неверными, хотя и выглядели правдоподобно и были написаны в авторитетном ключе.
Помимо вопросов справочного характера, вы также можете попросить модель ИИ модифицировать текст – например, резюмировать или перефразировать – то, для чего часто используют ChatGPT, если этот сервис доступен, не говоря уже о пересылке ваших данных в облако. В противоположность этому, представьте, что у вас просто есть ПК с видеокартой GeForce RTX, который может поглощать тома информации и делать то же самое.
Мне также понравилось решение NVIDIA в части анализа видео с YouTube, поскольку это значительно упрощает ориентирование в этом виде контента. Хотя тут нет никакой фантастики, где ИИ смотрит видео за вас (вместо этого он просто загружает сопроводительные текстовые файлы YouTube), это шаг в правильном направлении, дающий более полное представление о контенте.
Понятно, что Chat with RTX – еще довольно сырой продукт, но это первый проект NVIDIA на новом рынке ПК с ИИ, и мы не сомневаемся, что в дальнейшем он будет серьезно доработан.
В настоящее время Chat with RTX можно скачать с сайта NVIDIA.
Источник: www.techpowerup.com