Каталог
Компания Intel представила серию мобильных процессоров Core Ultra 200V под кодовым наименованием Lunar Lake. Эта серия знаменует собой фундаментальные преобразования концепции создания процессоров Intel, которая теперь опирается на высокую степень агрегированности микросхемы, включая встроенную память (Memory-on-Package, MoP). Процессоры Core Ultra 300 MX ориентированы на очень специфический класс устройств – тонкие и легкие ноутбуки, которые в то же время обладают потенциалом AI PC (ПК с ИИ) и поддерживают такие современные фишки, как Microsoft Copilot+, благодаря встроенным аппаратным ускорителям ИИ.
Компьютерная индустрия переживает бум клиентских приложений для ИИ – от простых моделей для редактирования изображений, размытия фона и т.п. или для синхронного перевода до сложных нейросетей, генерирующих контент. Microsoft считает, что большинство этих задач можно решать на локальном ПК силами встроенного нейропроцессора (Neural Processing Unit, NPU) и нескольких инференсов моделей ИИ. Центральный процессор (CPU) является энергетически неэффективным инструментом для ускорения ИИ, равно как и графический процессор (GPU) видеокарты. Все производители видеокарт сегодня интегрируют аппаратные ускорители ИИ в общую схему SIMD, и Microsoft может использовать их в таких функциях, как Windows Recall, которые требуют, чтобы ИИ был запущен все время; но постоянная активность видеокарты выливается в очень высокое энергопотребление. Решением этой проблемы становится NPU – специализированный аппаратный компонент, отвечающий определенным требованиям производительности (в данном случае, для Copilot+ требуется 40 TOPS) и потребляющий значительно меньшую мощность, чем ядра CPU или GPU.

Чип Intel Core Ultra 200V Lunar Lake – это не просто процессор, а так называемая система на кристалле (SoC), не предполагающая наличие чипсета за пределами данной корпусировки. Также нет отдельной системной памяти – процессор выпускается уже с 32 ГБ памяти LPDDR5X на борту. Процессоры с гибридными ядрами Intel делает много лет. Идея использования двух (или более) типов ядер CPU в одном чипе заключается в том, чтобы в процессоре были ядра, работающие в разных диапазонах производительности относительно потребляемой мощности, что позволяет процессору энергетически более адекватно реагировать на фактическую нагрузку. Высокопроизводительные ядра (или ядра P) предназначены для работы с интенсивной вычислительной нагрузкой; тогда как энергетически эффективные ядра (или ядра E) работают преимущественно с нагрузками низкой интенсивности или низкой приоритетности. Классификацией нагрузок и распределением их по соответствующим типам ядер занимается аппаратный компонент под названием Intel Thread Director.
В серии Lunar Lake Intel модернизирует микроархитектуру SoC по всем четырем ключевым аспектам: вычислительный комплекс CPU представлен новыми поколениями ядер обоих типов; встроенный графический компонент (iGPU) представляет новую графическую архитектуру; NPU усовершенствован в соответствии с требования Copilot+ и AI PC. Помимо этого, много изменений сделано в самой схеме SoC. В Intel решили использовать встроенную память по примеру конкурирующих процессоров – Apple M3 и Qualcomm Snapdragon X Elite, которые занимают очень мало места на печатной плате и имеют очень ограниченный бюджет мощности, однако при этом способны обеспечить современный опыт использования AI PC в тонком и легком форм-факторе. Intel применяет аналогичное решение, и, таким образом, чипы Lunar Lake в части компоновки и микроархитектуры базируются на инновациях серий Meteor Lake и Lakefield.
В этом обзоре мы подробно рассмотрим технические особенности процессора Core Ultra 200 MX и микроархитектуры Lunar Lake. На момент написания статьи Intel не анонсировала конкретных моделей чипов этой серии. Возможно, они сделают это на Computex.

Lunar Lake представляет новый вариант компоновки SoC. Она базируется на технологии Foveros и чиплетном подходе, которые мы видели в Meteor Lake, но здесь Intel меняет расстановку компонентов схемы. Если вы помните, Meteor Lake – довольно неоднородная микросхема: ядра CPU располагаются на плитке Compute Tile, которая базируется на техпроцессе Intel 4; плитки SoC и I/O базируются на техпроцессе TSMC 6 нм, плитка Graphics – на техпроцессе 5 нм; и все эти плитки сидят на 20-нм плитке-основании, которая содержит микроскопическую проводку высокой плотности, соединяющую остальные плитки, то есть служит физическим интерфейсом.
В Lunar Lake Intel объединяет плитки Compute Tile, Graphics Tile и большую часть логически нагруженных компонентов бывшей плитки SoC в одну плитку Compute, которая базируется на техпроцессе TSMC 3 нм, в то время как встроенные контроллеры и нагруженные компоненты I/O вынесены на отдельную плитку Platform I/O, которая базируется на техпроцессе TSMC 6 нм.

Плитка-основание сидит на стекловолоконной подложке, которая содержит проводку высокой плотности, подключенную к двум чипам памяти LPDDR5X; они обеспечивают систему двухранговой памятью LPDDR5X-8500 емкостью до 32 ГБ. Использование встроенной в процессор оперативной памяти снижает энергопотребление физического интерфейса памяти на 40% по сравнению с распайкой чипов памяти на материнской плате или использованием сокетированных модулей SO-DIMM или CAMM2.
Процессоры Intel Core Ultra 200V – это не прямые свежие аналоги Core Ultra 100 Meteor Lake, а скорее новый класс процессоров Intel для тонких и легких ноутбуков наподобие тех, которые оснащаются чипами Apple M3 или Qualcomm Snapdragon Elite X. И этим обусловлены специфические целевые характеристики новых процессоров Intel в части производительности CPU, графики и ускорения ИИ, а также энергетической эффективности, которая играет ключевую роль в обеспечении конкурентоспособности в сравнении с чипами Apple и Qualcomm.


CPU-комплекс Lunar Lake-MX содержит в общей сложности восемь ядер, четыре из которых – это новые высокопроизводительные (P) ядра Lion Cove, а остальные четыре – энергетически эффективные (E) ядра Skymont. В отличие от Meteor Lake, и вообще от всех предыдущих поколений гибридных процессоров Intel, здесь ядра P и E не используют общий кэш L3 и не висят на одной кольцевой шине Ringbus. Они просто вделаны в один и тот же кристалл и включены во внутреннюю высокоскоростную фабрику этого кристалла.

Четыре ядра P являются частью маленькой сети Ringbus с котроллерами доступа к кольцевой шине у всех четырех ядер и представляют собой сегменты 12-мегабайтного кэша L3, общего для всех четырех ядер. Кластер ядер E, со своей стороны, представляет собой "остров", аналогичный острову малопотребляющих ядер в Meteor Lake. 4-мегабайтный кэш L2 этого кластера работает как кэш последнего уровня, общий для четырех E-ядер Skymont. Обрабатываемые потоки могут беспрепятственно мигрировать между кольцом ядер P и островом ядер E. Intel добавила в блок Thread Director ряд усовершенствований, о которых мы еще поговорим.

Процессор Core Ultra 200V Lion Cove-MX содержит четыре высокопроизводительных P-ядра Lion Cove, которые совместно используют 12-мегабайтный кэш L3. Ядро Lion Cove разработано Intel с целью обеспечения максимально возможной производительности и совместимости в части архитектуры набора команд (ISA) без ущерба для энергетической эффективности. Самое интересное здесь – это то, что Intel не добавила в ядра Lion Cove поддержку многопоточности, то есть технологию Hyper-Threading (HTT).

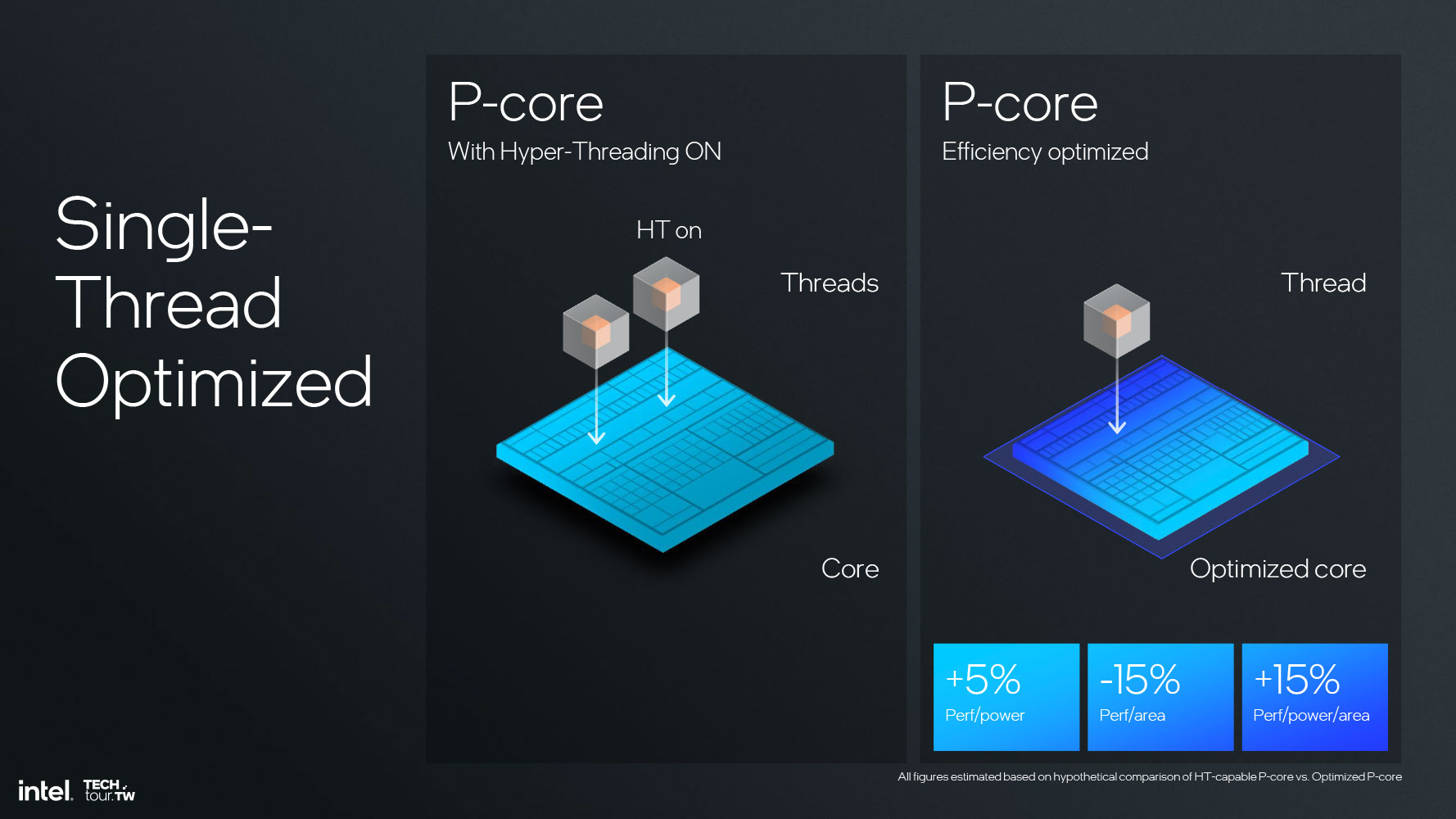
Технология HTT – это действительно очень хороший способ загрузить простаивающие аппаратные ресурсы ядра параллельной обработкой второго потока, прямо на аппаратном уровне, но это подразумевает наличие дополнительных аппаратных блоков маршрутизации второго потока. Это физические блоки, которые занимают место на кристалле – независимо от того, включена технология HTT в конкретной модели процессора или нет. В Intel решили убрать из схемы эти компоненты, обеспечивающие работу HTT, обосновывая это тем, что сэкономленную на этом энергию и площадь кристалла можно использовать для повышения тактовых частот и производительности IPC ядра, которая играет ключевую роль в достижении желаемых показателей эффективности (производительность на ватт потребляемой мощности) процессоров Lunar Lake. Без блоков HTT и при использовании соответствующего техпроцесса в Lion Cove экономится 15% площади кристалла, что дает 5%-ное увеличение производительности относительно потребляемой мощности и 15%-ное увеличение производительности относительно потребляемой мощности и площади кристалла.
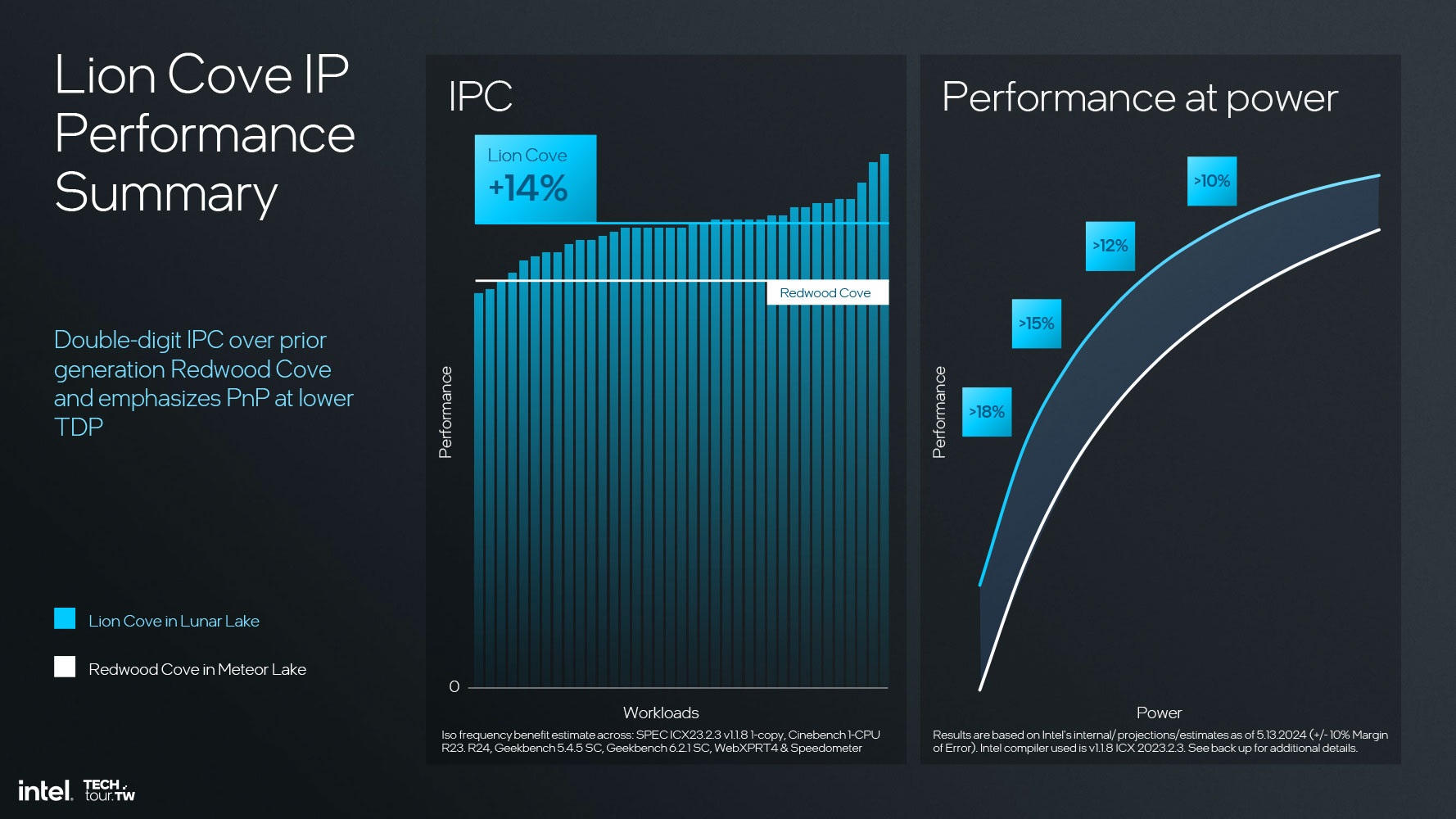
Intel заявляет значительное – 14%-ное – увеличение IPC в Lion Cove по сравнению с предыдущим поколением P-ядер Redwood Cove, которые используются в процессорах Meteor Lake. Они также демонстрируют график стабильного прироста производительности (до 18%) при тех же значениях потребляемой мощности.


Intel также существенно модернизировала систему управления напряжениями на уровне ядра, которая получила две новые фишки: контроллер авторегулирования с ИИ, снижающий тактовые частоты и энергопотребление, когда это целесообразно, и гораздо более точную настройку самих тактовых частот с интервалом 16.67 МГц вместо 100 МГц на основе множителя, как было в предыдущих поколениях ядер P.



Высвободив пространственно-энергетический ресурс за счет исключения из схемы ядер блоков HTT, Intel перестроила также саму микроархитектуру ядра. Усовершенствованы все ключевые компоненты, включая фронт конвейера, который теперь содержит в восемь раз больший блок прогнозирования ветвлений. Увеличена пропускная способность декодера команд и блока извлечения команд из памяти. Помимо увеличения емкости кэша микроопераций, Intel также вводит концепцию "наноопераций", которые представляют собой группы параллельно выполняемых аналогичных подзадач микроопераций.


Домены Integer и Vector, которые образуют движок внеочередного выполнения команд, теперь имеют раздельный доступ к очереди микроопераций, с независимыми планировщиками. Внеочередной движок обслуживает распределяемую очередь переименованных/перемещенных исключений, которая теперь расширена до восьми позиций (с шести в Redwood Cove). Очередь отложенных команд расширена в полтора раза, с восьми до 12 позиций. Глубина окна команд увеличена с 512 до 576 позиций. Количество исполнительных портов увеличено с 12 до 18.


Количество блоков ALU в домене Integer увеличено с пяти до шести, блоков адресного перехода – с двух до трех, блоков сдвига – с двух до трех, блоков умножения (MUL) – с одного до трех. Векторный исполнительный движок содержит четыре SIMD ALU вместо трех, два блока команд FMA (за четыре цикла) и два блока деления. Подсистема Load/Store содержит буфер DTLB, размер которого увеличен с 96 до 128 записей, и три генератора адресов STE вместо двух.

Intel также перестроила подсистему кэшей на уровне ядра, введя промежуточный кэш данных между 48-килобайтным L1 и L2. Кэш L1D теперь называется D-кэш L0 и сообщается со 192-килобайтным D-кэшем L1, который, в свою очередь, передает данные в кэш L2. Емкость кэша L2 в ядре Lion Cove процессора Lunar Lake составляет 2.5 МБ (2560 КБ, если говорить точно). В поколении Arrow Lake это ядро получит 3-мегабайтный (3072 КБ) выделенный кэш L2. Четыре ядра P в чипе Lunar Lake используют общий 12-мегабайтный кэш L3.
Но настоящие звезды Lunar Lake – это энергетически эффективные ядра E, о которых мы поговорим в следующем разделе.


Когда Intel стала включать E-ядра в массовые процессоры (начиная с Lakefield), это на первый взгляд выглядело как дешевый способ усилить CPU дополнительными ядрами. С выходом 12-го поколения Core Alder Lake стало понятно, какую идею продвигает Intel: клиентским ПК на самом деле не нужны кучи ядер CPU, и несколько высокопроизводительных P-ядер вполне могут справиться с высоконагруженными приложениями, а для легких и средних нагрузок, которые преобладают в клиентском компьютинге, можно использовать маленькие энергетически эффективные ядра, потребляющие только часть той мощности, которую потребляли бы в этих сценариях ядра P, даже при условии оптимального управления напряжениями и на минимальных тактовых частотах. Эта концепция была усилена в серии "Raptor Lake", где Intel увеличила в новых процессорах число ядер E, а не P.
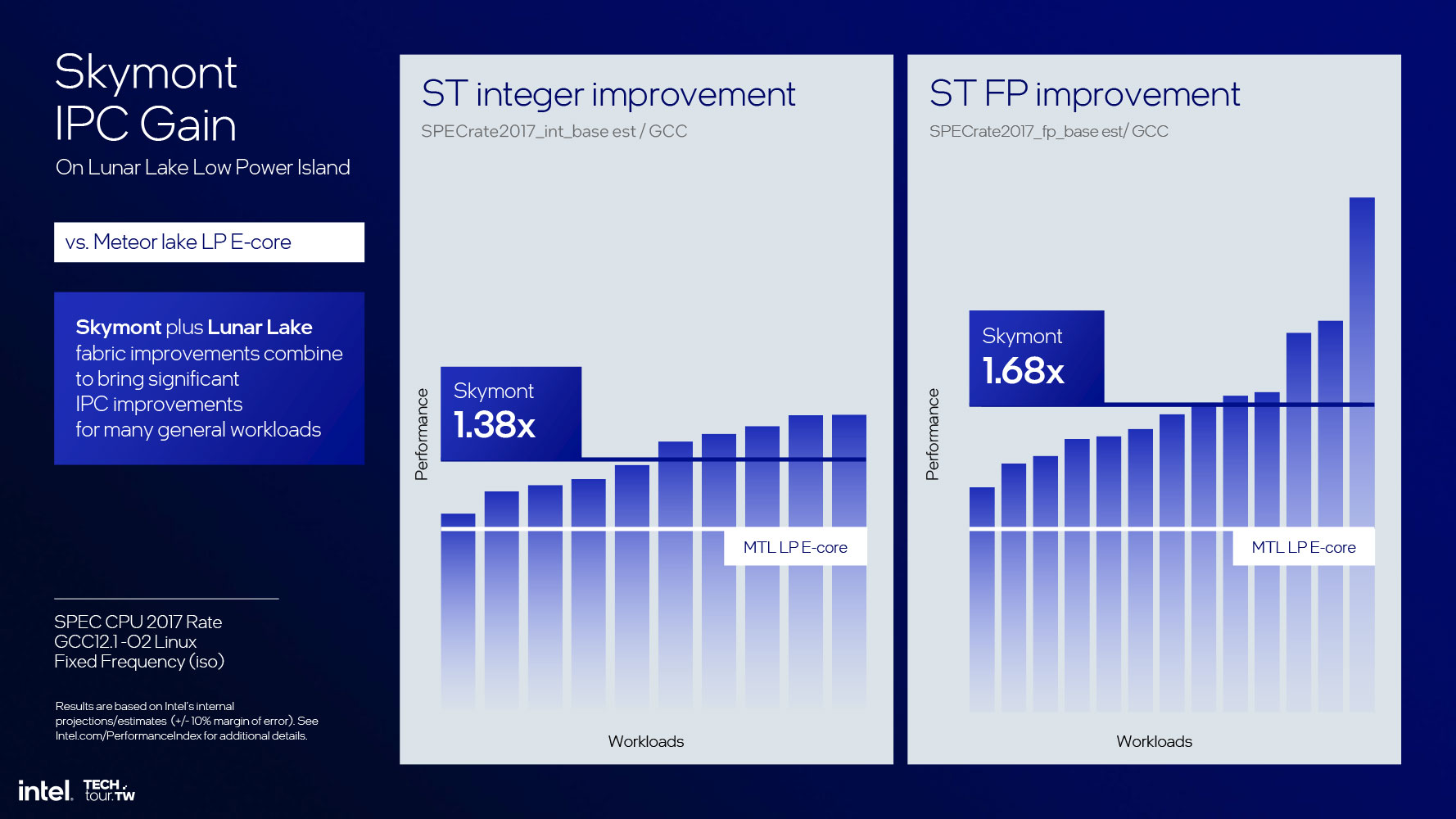
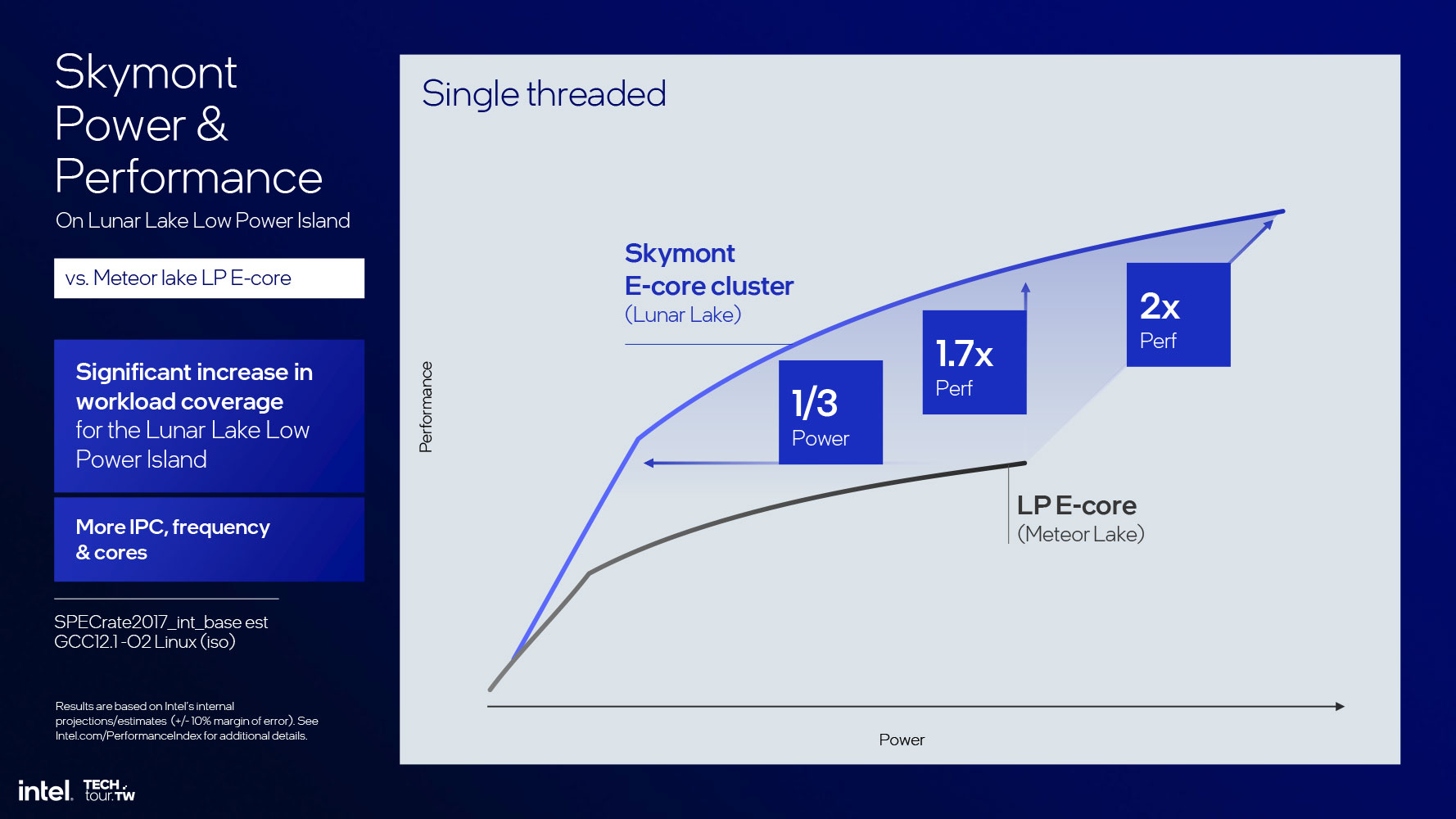
Достигнув значительных успехов в части показателей производительности относительно потребляемой мощности с E-ядрами Gracemont и их последующими аналогами Crestmont, которые обеспечили 4%-ное увеличение IPC, Intel решилась на эксперимент. Вопрос стоял так: "А что, если мы оптимизируем ядро E в рамках его характеристики отношения производительности к потребляемой мощности?" В результате появилось ядро Skymont, которое является главным энергетически эффективным компонентом процессоров семейства Lunar Lake и следующего семейства Arrow Lake.
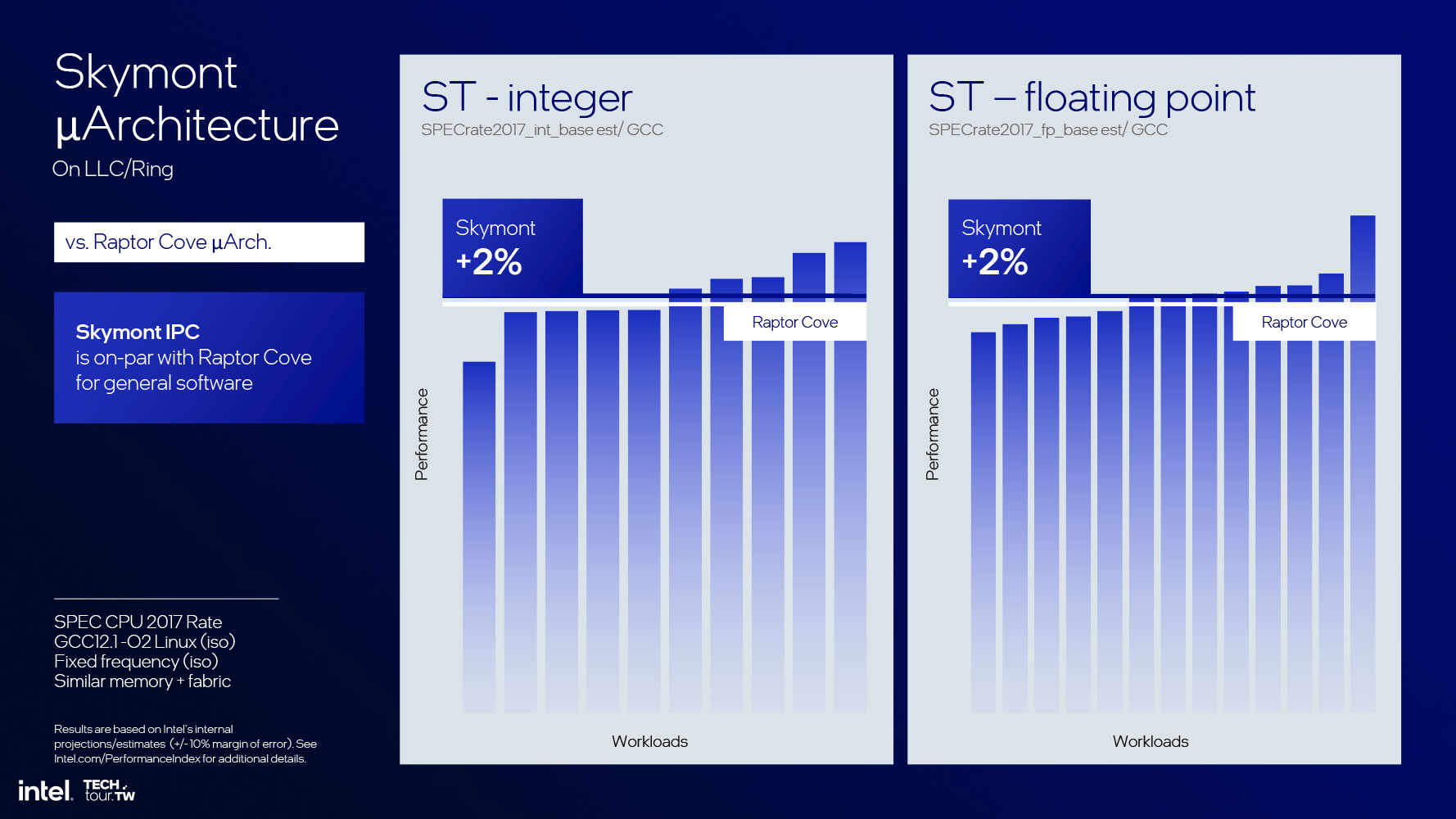
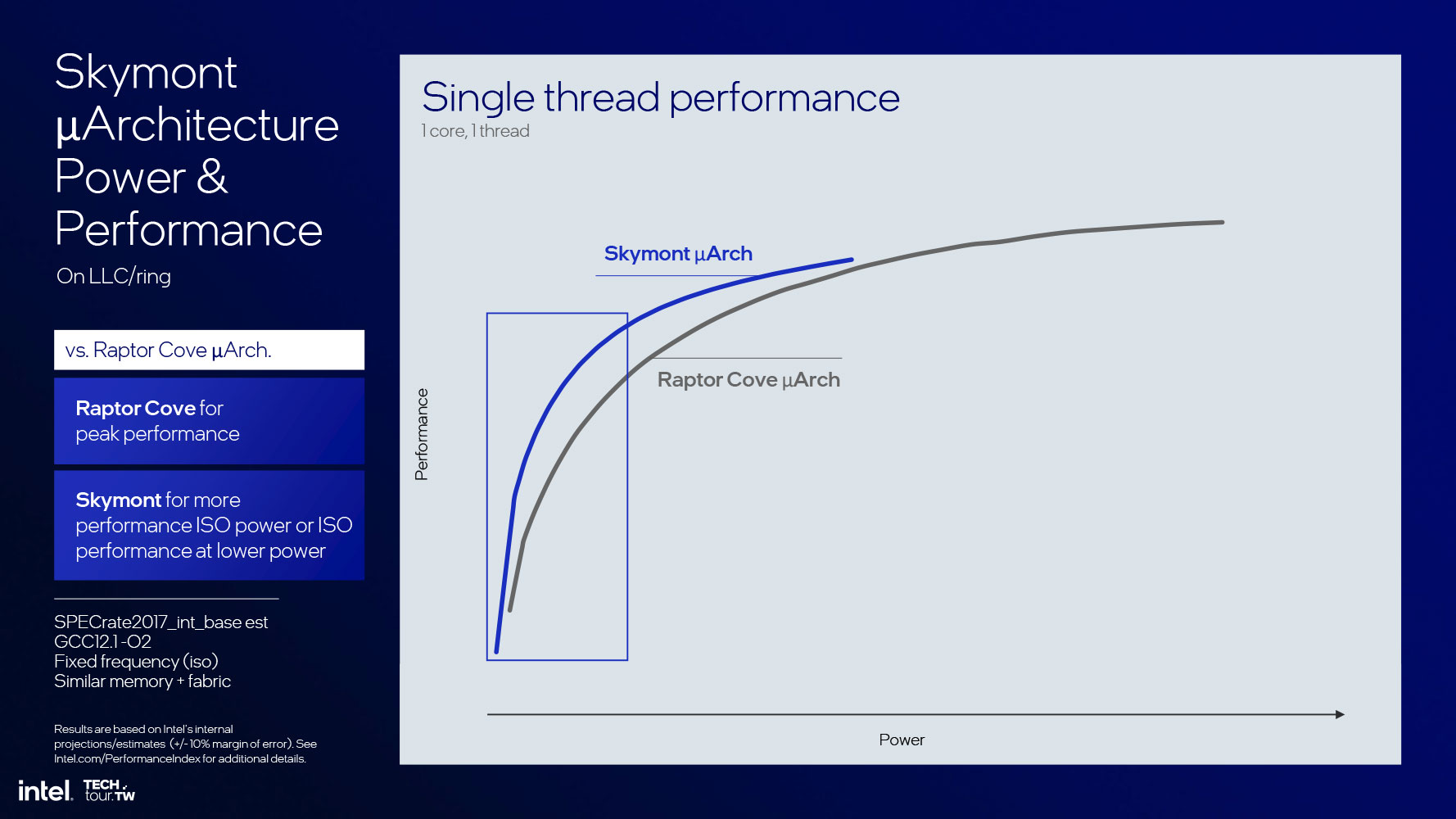
Прежде чем углубляться в архитектуру ядра, отметим достижения Intel: впечатляющий 68%-ный прирост IPC по сравнению с ядрами Crestmont (которые составляют малопотребляющий остров E-ядер в чипах Meteor Lake). Это корректное сравнение, так как кластер E-ядер Skymont не является частью кольца ядер P, а представляет собой остров (хотя и находится на той же плитке Compute). Кривые равной производительности показывают 300%-ное увеличение производительности относительно потребляемой мощности. Кривые равного энергопотребления тоже показывают почти трехкратный (в 2.9 раза) прирост производительности. На максимально возможном лимите мощности Lunar Lake новые ядра предлагают четырехкратное увеличение производительности относительно малопотребляющих ядер Crestmont.
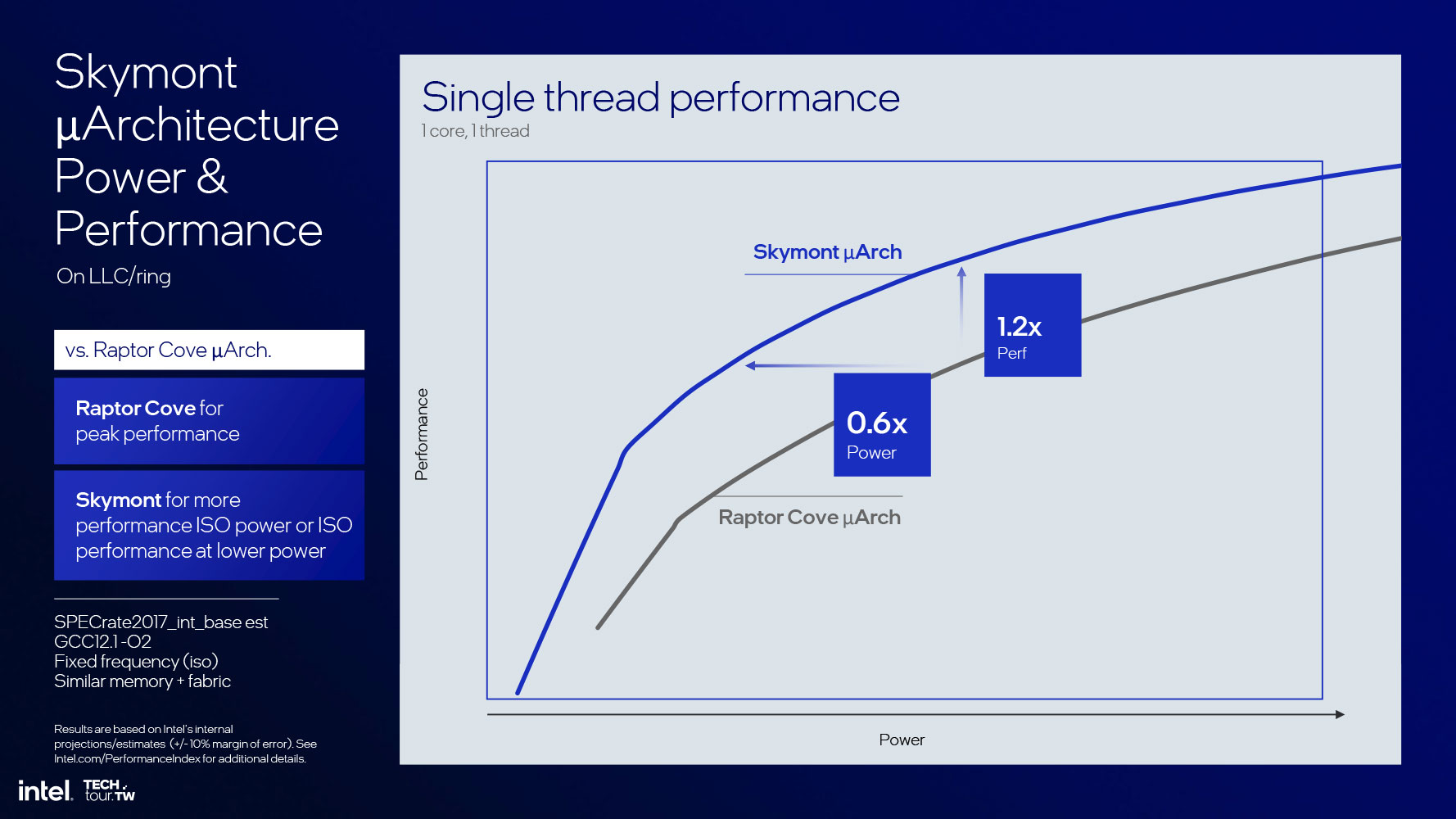
Этот феноменальный рост IPC объясняет, почему Intel не просто уверенно использует только четыре E-ядра, но также выделяет их в «островной» вычислительный комплекс; и здесь Intel получает подтверждение правильности своего решения не добавлять Hyper-Threading в P-ядра Lion Cove и за счет этого оптимизировать использование площади кристалла. Кривые производительности относительно потребляемой мощности ядер Skymont и Lion Cove имеют большую область пересечения, которая показывает, как общая конфигурация ядер 4P+4E в Lunar Lake способна обеспечить значительный прирост производительности относительно предыдущего поколения Meteor Lake.


Внутренние усовершенствования микроархитектуры Skymont начинаются с блоков извлечения команд из памяти и прогнозирования ветвлений, где теперь на возможные ветвления отводится 128 байт, что позволяет ускорить извлечение команд из памяти: параллельно извлекается до 96 байт команд. Фронт конвейера содержит новый 9-позиционный декодер команд (против 6-позиционного в Crestmont), поддержку нанокодов (аналогичные сегменты микрокода, сгруппированные вместе для параллельного выполнения) и расширенную очередь микроопераций – до 96 записей вместо 64-х в предыдущем поколении.


Движок внеочередного выполнения команд получил самые весомые модернизации. Распределяемая очередь расширена с шести до восьми позиций, отложенная очередь – с восьми до 16 позиций. Независимый доступ доменов к очереди позволяет снизить задержку. Окно внеочередных команд расширено с 256 до 416 записей, также увеличены физические размеры регистровых файлов, глубина станций резервирования и глубина буфера подсистемы Load/Store.


К исполнительному движку Integer подключено 26 портов отправки, ведущих к восьми целочисленным ALU с тремя портами адресного перехода и тремя загрузками в каждом цикле (вместо двух в предыдущем поколении).

Векторный движок содержит четыре 128-разрядных модуля FPU, удваивающих гигафлопсы. Задержки в вещественных блоках FMUL, FADD и FMA снижены. Для округления чисел с плавающей запятой теперь предусмотрено аппаратное ускорение. Дополнительные исполнительные блоки также должны улучшать производительность ИИ. Производительность блока загрузки и хранения адресов Load/Store по сравнению с предыдущим поколением выросла на 33-50%. Размер буфера TLB L2 увеличен с 3096 до 4192 записей.
Наконец, кластер E-ядер Skymont использует общий для четырех ядер 4-мегабайтный кэш L2. Intel удвоила пропускную способность кэша L2, как и объем трансферов между кэшами ядер L1.
В части IPC бенчмарк SPECrate2017 Integer показывает 38%-ное увеличение производительности; в операциях с плавающей запятой производительность выросла на 68% по сравнению с E-ядрами Crestmont, образующими аналогичный малопотребляющий остров. В Intel настолько уверены в ядрах Skymont в части IPC, что заявляют для них IPC на уровне P-ядер Raptor Cove, которые используются в процессорах Raptor Lake. Теперь представьте рой зергов из ядер Skymont, которые занимают только часть кристалла Raptor Cove и потребляют только часть его бюджета мощности, и вы поймете, в чем секрет столь успешного решения Intel вопроса о вычислительном движке.

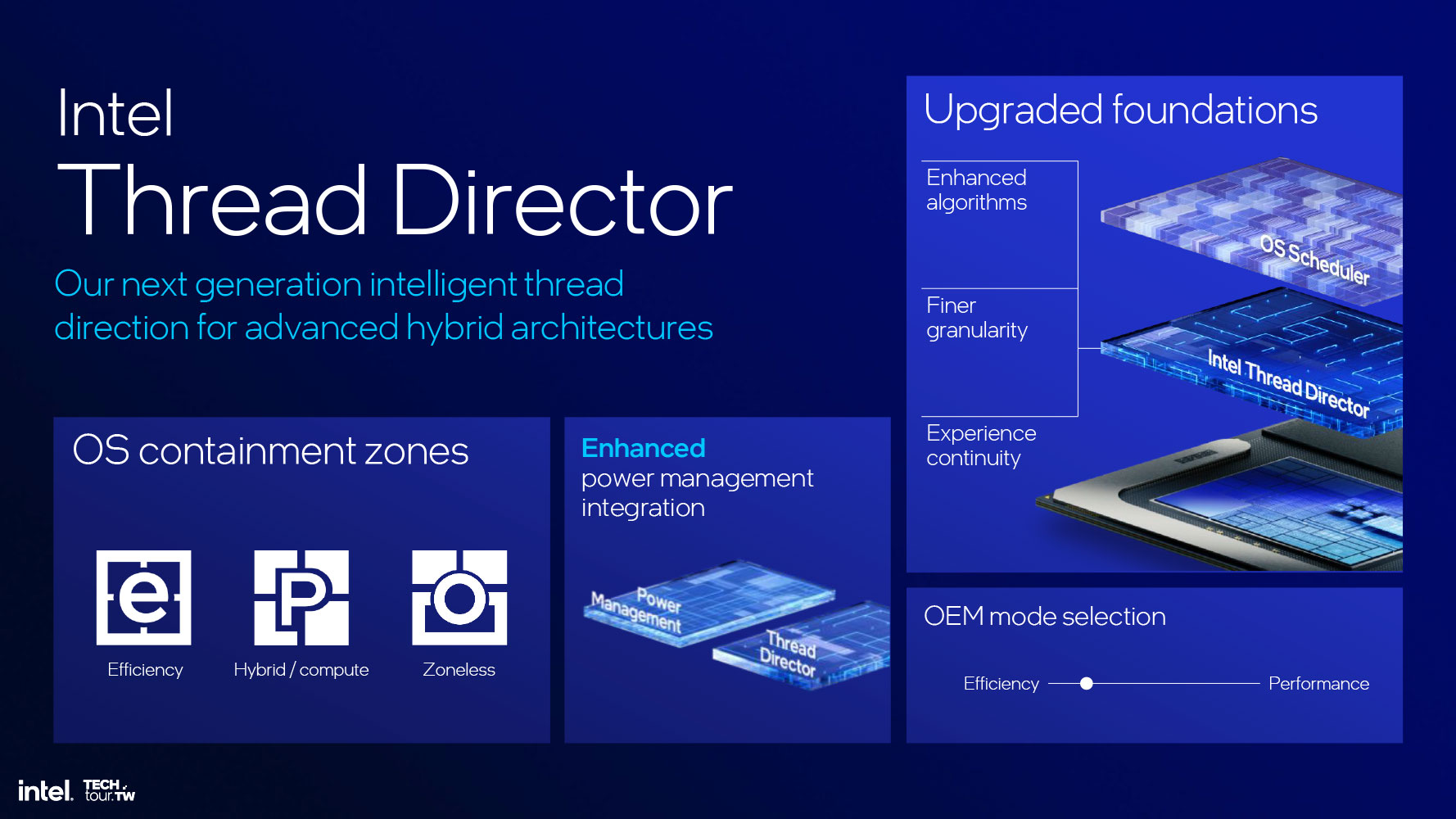
В новом поколении Intel усовершенствовала также блок Thread Director. Этот аппаратный компонент гарантирует правильное распределение потоков нагрузки по ядрам CPU соответствующих типов и при необходимости корректное перемещение этих потоков между типами ядер. Intel усовершенствовала этот алгоритм на аппаратном уровне по таким аспектам, как адекватность нагрузке, своевременность и точность дискретизации.


В этой версии Thread Director также вводится поддержка «зон контейнеризации» на уровне операционной системы: пользователь может присваивать приложениям теги, указывающие на обработку этих приложений ядрами P, кластером E или оставляющие их без зонирования. Динамический планировщик Lunar Lake по умолчанию запускает все нагрузки на ядрах E и затем по мере необходимости переводит их на ядра P.

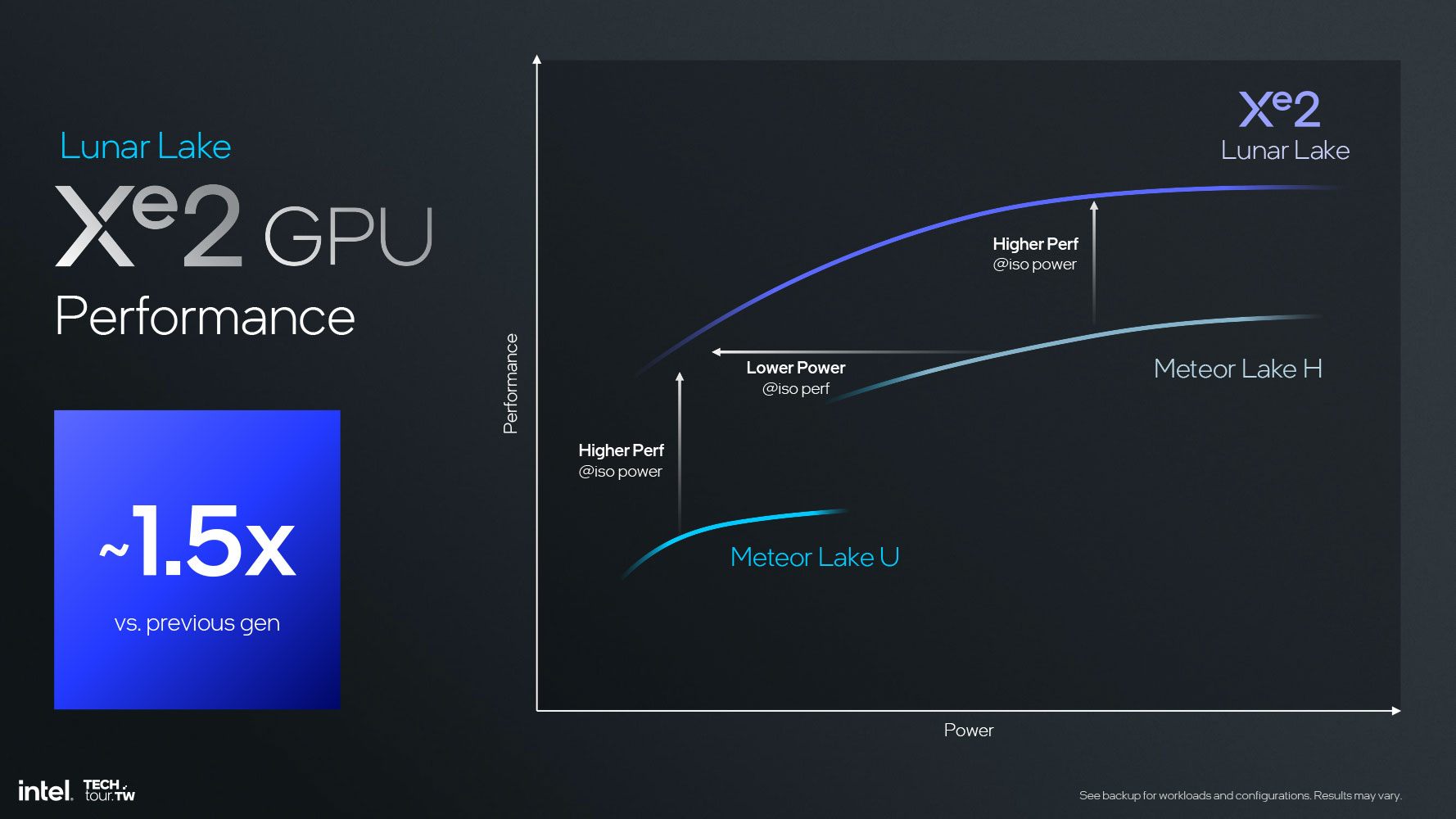
Встроенный графический процессор (iGPU) Intel для серии Lunar Lake – это первый графический компонент компании на базе новой архитектуры Xe2 Battlemage. Он предлагает полуторакратное увеличение игровой производительности по сравнению с iGPU Xe-LPG процессоров Meteor Lake. Новый iGPU оснащен ядрами Xe следующего поколения с улучшенными показателями IPC и обновленным векторным движком.


Ядро Xe – это базовый неделимый вычислительный компонент схемы iGPU. Каждый такой компонент содержит восемь 512-разрядных векторных движков, восемь 2048-разрядных матричных движков XMX, поддерживающих 64-разрядные элементарные операции, и увеличенный до 192 КБ кэш L1/ SLM.

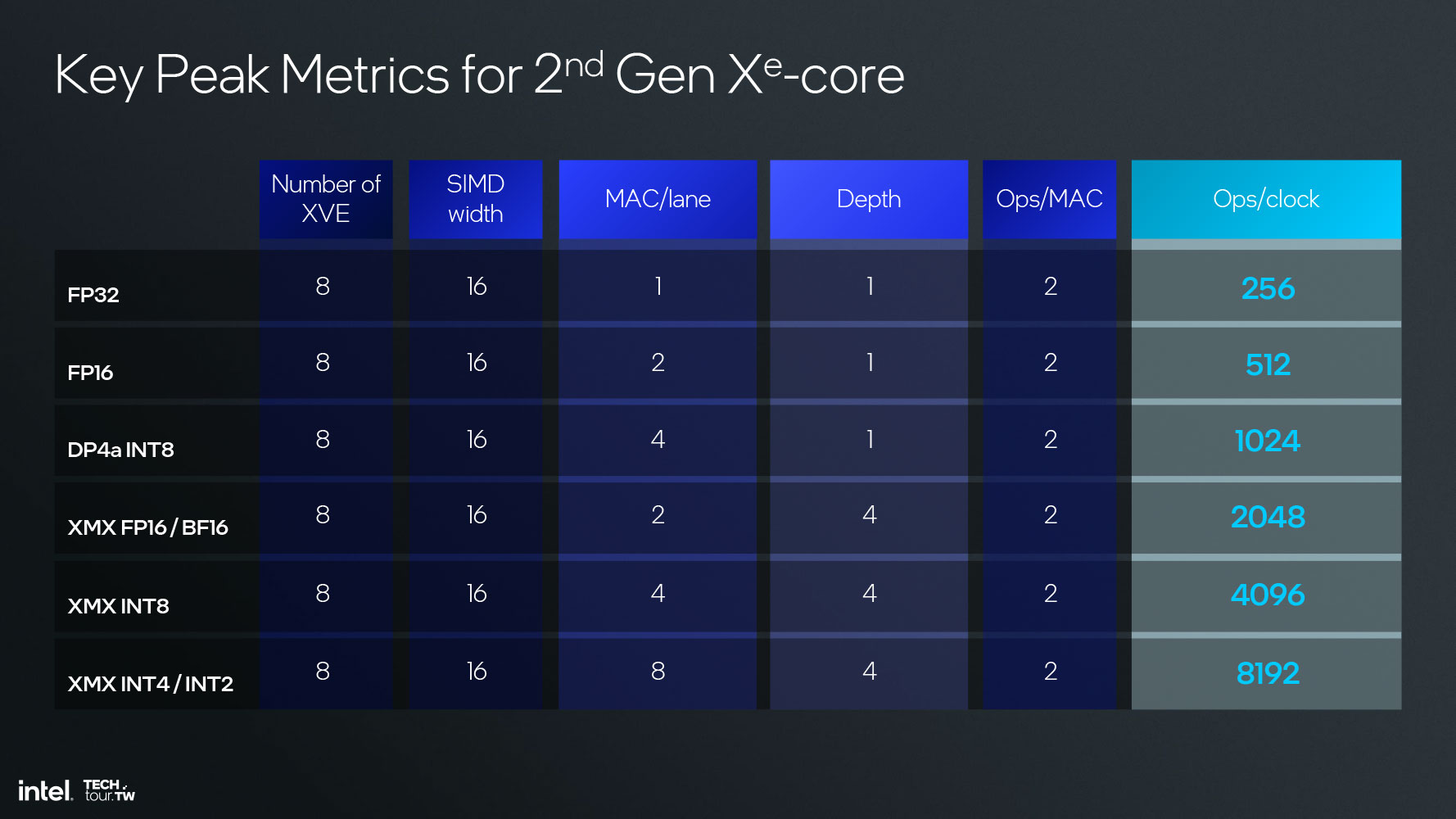
Самое значительное архитектурное нововведение в iGPU Xe2 чипов Lunar Lake – это матричные движки XMX, которых не было во встроенной графике Xe Alchemist. Располагая восемью ядрами Xe2, встроенный GPU использует 1024 унифицированных шейдера, а его блоки XMX добавляют до 67 TOPS к производительности ИИ (независимо от ИИ-топсов NPU). Новый iGPU также отвечает всем требованиям спецификаций DirectX 12 Ultimate и содержит восемь блоков рейтрейсинга следующего поколения.
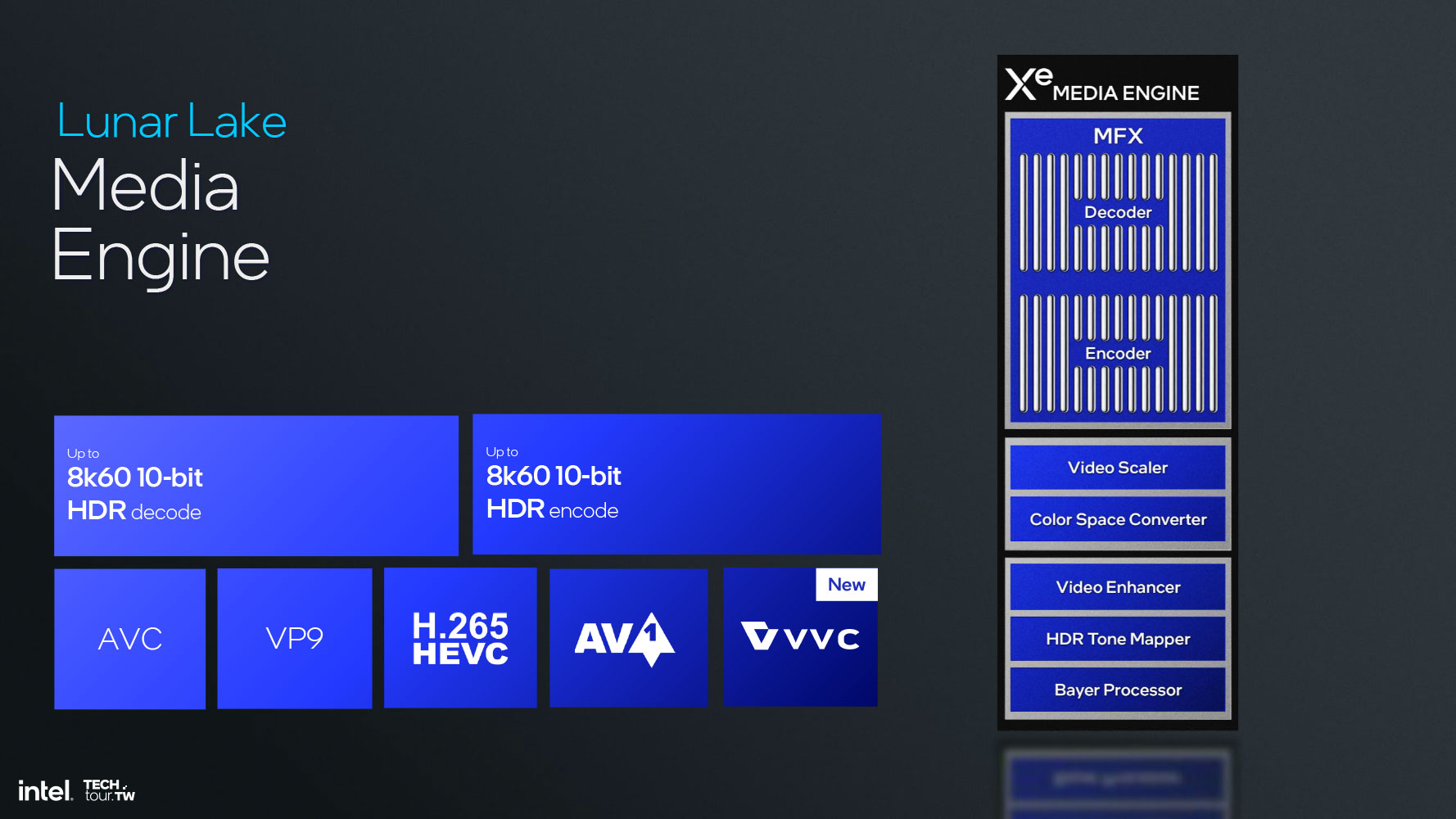

Медиадвижок содержит средства ускоренной аппаратной поддержки кодирования и декодирования AV1 и впервые предлагает аппаратную поддержку декодирования VVC. По сравнению с AV1 формат VVC (или H.266) сокращает размер медиафайлов всего на 10% при равном качестве, но, кроме того, поддерживает адаптивное разрешение и 360-градусную панорамную визуализацию.
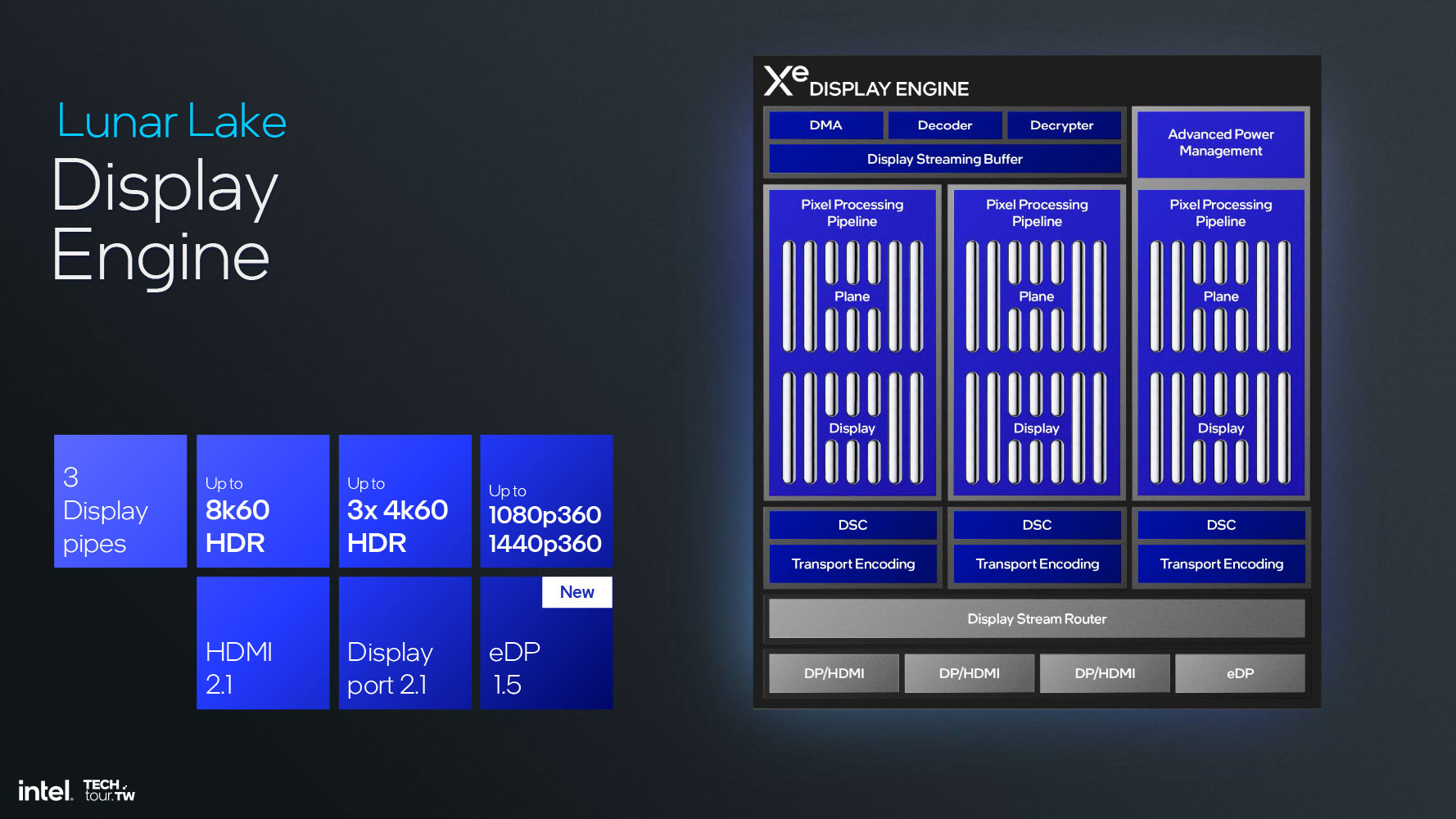

Дисплейный движок поддерживает новый стандарт eDisplayPort 1.5, предлагающий улучшенные функции Panel Self-Refresh, выборочного обновления экрана и адаптивной синхронизации с поддержкой Panel Replay. Также поддерживаются DisplayPort 2.1 и HDMI 2.1.


Это второе поколение процессоров Intel, оснащенных нейропроцессорным блоком (NPU), который отвечает за эффективное ускорение ИИ. Однако, Intel в Lunar Lake заявляет этот блок как NPU 4. Это объясняется тем, что они считают свои аппаратные блоки для ускорения ИИ, созданные до эры NPU, такие как GFNI и AVX512, или VNNI, первыми моделями NPU, хотя вы не сможете запустить на этих «прототипах» ни один из современных сценариев для NPU.

Здесь важно, что NPU 4 в Lunar Lake обеспечивает четырехкратное ускорение ИИ-инференсов по сравнению с NPU 3, который используется в Meteor Lake. Производительность инференсов скакнула с 12 TOPS в Meteor Lake до 48 TOPS в Lunar Lake. Это соответствует (и даже с запасом) требованию 40 TOPS, установленному Microsoft для запуска локальных сессий Copilot+, и позволяет сертифицировать ноутбуки с этими процессорами как AI PC Copilot+.
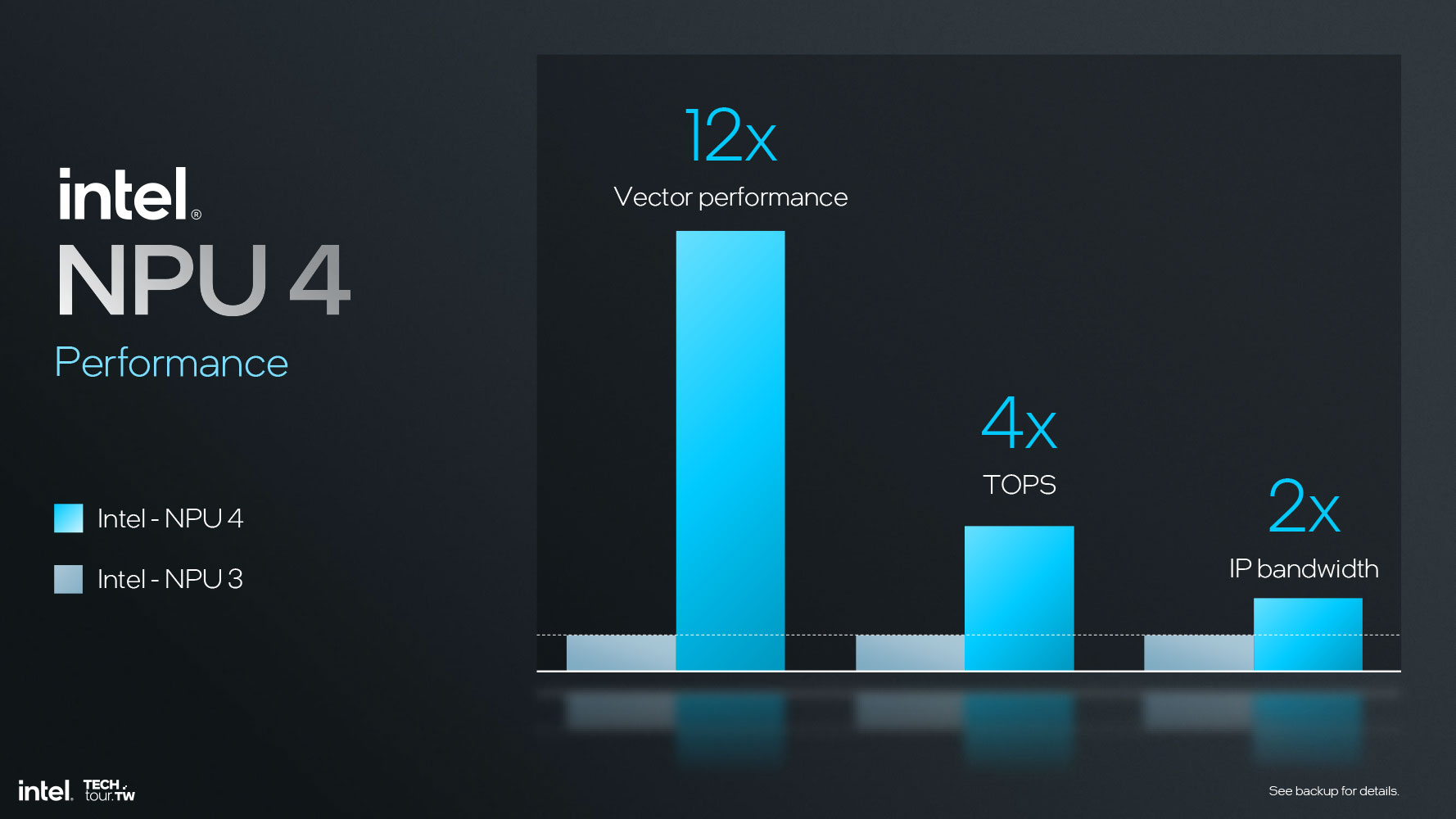
Такой скачок в производительности ИИ обусловлен не только архитектурными усовершенствованиями (которые направлены на снижение энергопотребления и тепловыделения NPU), но также увеличением количества нейродвижков NCE (Neural Compute Engine) с двух в NPU 3 (Meteor Lake) до шести в NPU 4 (Lunar Lake) с пропорциональными увеличениями в части емкости и пропускной способности «блокнота» RAM, DMA и кэша L2.
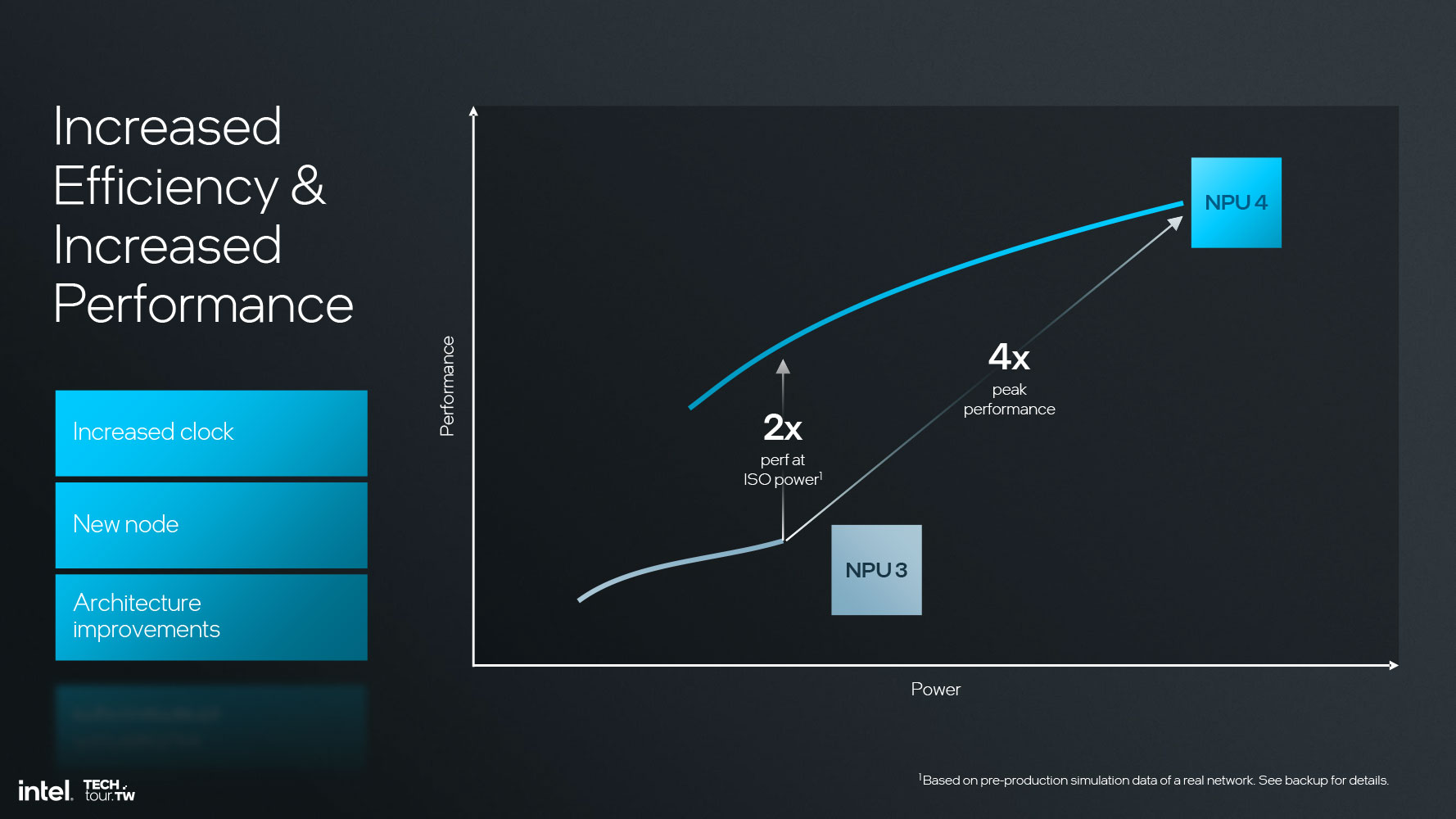
Кластер матричного умножения и свертки (MAC Array) в NPU 4 поддерживает типы данных INT8 и FP16: 2048 MAC/ цикл INT8 или 1024 MAC/ цикл FP16. Intel заявляет для NPU 4 двукратное увеличение производительности относительно потребляемой мощности по сравнению с NPU 3, которое достигается благодаря усовершенствованиям в части активационных функций и преобразования данных, модернизации сигнального процессора DSP SHAVE и удвоению пропускной способности движка DMA.
Итого, по сравнению с NPU 3 в NPU 4 «сырая» производительность векторных вычислений выросла в 12 раз, производительность инференсов (AI TOPS) – в 4 раза, пропускная способность фабрики NPU – в 2 раза.


Плитка Platform I/O базируется на техпроцессе TSMC 6 нм и содержит все интерфейсы SoC и коммуникации платформы. Интересно, что в этом процессоре контроллер памяти находится на плитке Compute, которая содержит ядра CPU, iGPU и NPU. Этот контроллер памяти поддерживает только LPDDR5X, поскольку он предназначен исключительно для управления встроенной памятью. Поскольку он имеет дело с четырьмя сегментами с высокими требованиями к пропускной способности подсистемы памяти, а именно – CPU, iGPU, NPU и Platform I/O, контроллер памяти подкреплен 8-мегабайтным кэшем.
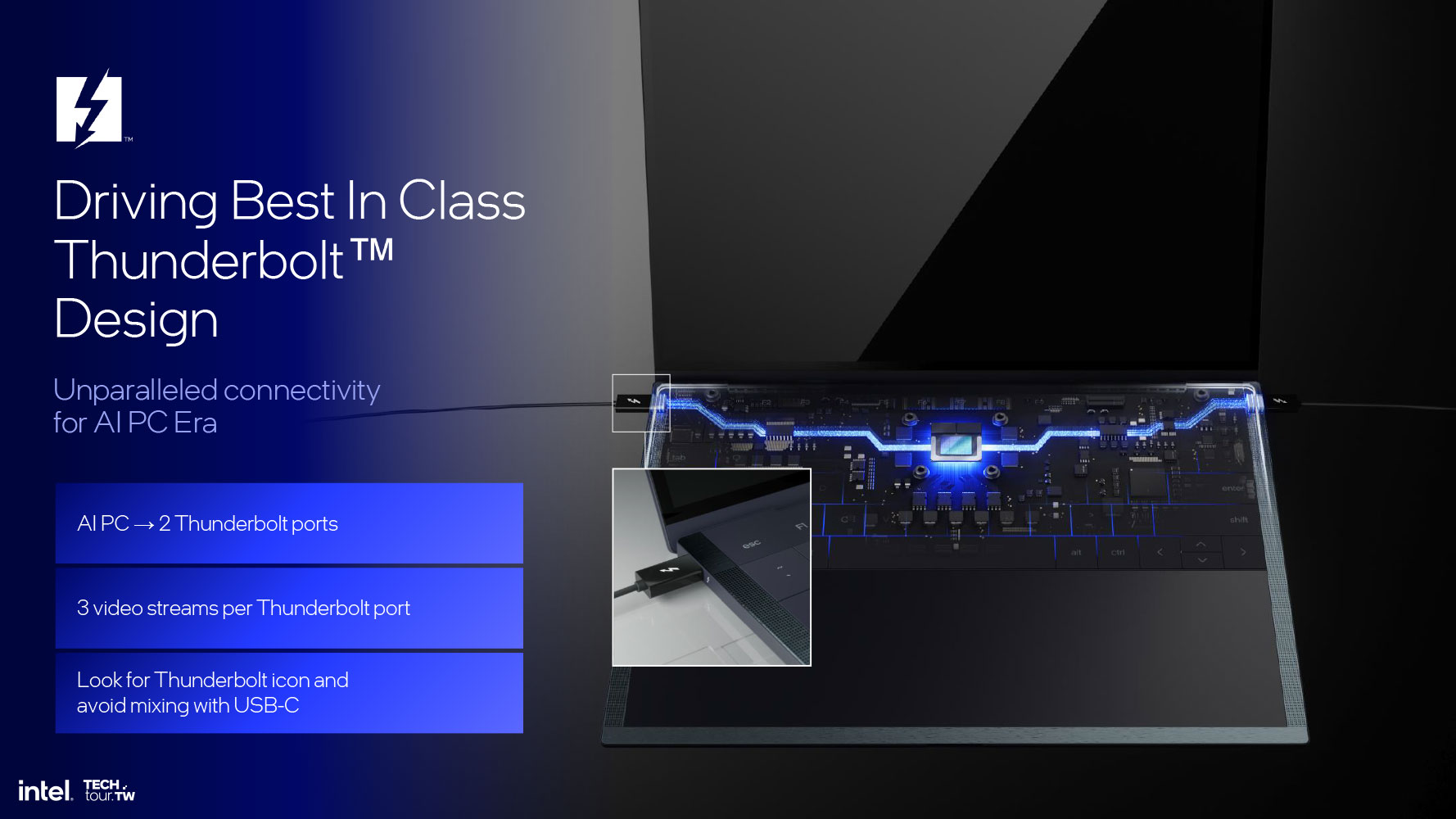
Плитка Platform I/O содержит ряд компонентов нового поколения, включая встроенный контроллер WLAN с Wi-Fi 7 и Bluetooth 5.4, поддерживающий беспроводные подключения 5.8 Гбит/с, и контроллер Thunderbolt 4, поддерживающий до трех портов 40 Гбит/с Thunderbolt 4.
На плитке Platform I/O также находится рут-комплекс PCI-Express. Процессор Lunar Lake предлагает только восемь линий PCIe, четыре из которых относятся к поколению Gen 5, а остальные четыре – к поколению Gen 4.
Такое «скромное» количество линий PCIe обусловлено классом устройств, для которых предназначены процессоры Core Ultra 200V, – тонкие и легкие ноутбуки, не предполагающие установку дискретной видеокарты. Этому здесь четыре линии Gen 5 подразумевают подключение современного накопителя NVMe SSD Gen 5, и еще четыре линии Gen 4 остаются для подключения к платформе каких-либо других устройств.
Помимо трех 40-гигабитных портов Thunderbolt 4, Lunar Lake предлагает опции USB 3.2 5 Гбит/с и 10 Гбит/с, и USB 2.0. И снова, сравнительно небольшое количество портов объясняется тем, что на тонких и легких ноутбуках больше и не нужно. При необходимости к ним можно подключить внешнюю графическую док-станцию через Thunderbolt.
Многие думают, что главные конкуренты процессоров Intel – это чипы AMD Ryzen, тогда как на самом деле это чипы серий Apple M и Qualcomm Snapdragon Elite. Две последние линейки идут в суперэффективные ультрабуки с быстродействием и временем автономной работы как у смартфонов, и в этом аспекте с ними просто невозможно соревноваться, используя «тяжелые» процессоры с большими ядрами. Поэтому в Intel обратились к идее гетерогенных (гибридных) многоядерных схем и при этом сделали особый акцент не столько на приращении производительности IPC порядка 10% у ядер P, сколько на максимизации производительности ядер E.
Нужно понимать, что ядра E разрабатывались под девизом "убрать лишнее" из стандартного ядра CPU и представляют собой продукт оптимизации архитектуры в сторону сокращения, тогда как ядра P разрабатывались под девизом "добавить нужное" в стандартное ядро и являются продуктом расширения архитектуры. И поэтому Intel располагает огромным потенциалом для повышения производительности и функциональных возможностей ядер E, и именно этим обусловлен прорыв Skymont.
Один только слайд, где Intel демонстрирует близкие показатели IPC ядер Skymont и Raptor Cove (последнее – ядро P), должен взбудоражить отрасль, и Apple, Qualcomm и AMD возьмут это на заметку. Skymont обеспечивает IPC на уровне Raptor Cove, используя только часть от числа транзисторов последнего и, соответственно, только часть его бюджета мощности. Сегодня Intel спокойно может заливать в свои процессоры кластеры Skymont, дополняя их несколькими P-ядрами Lion Cove, и, таким образом, создавать внушительные гибридные чипы, которые могут выступить против многоядерных процессоров AMD, располагающих только высокопроизводительными ядрами или их «ужатыми» версиями.
Lunar Lake – не единственная архитектура, сочетающая в себе ядра Lion Cove и Skymont; следом будет еще Arrow Lake. И, если в Lunar Lake ядра Skymont образуют автономный малопотребляющий остров, отдельный от кольца ядер P, то в Arrow Lake будет несколько кластеров Skymont, использующих кольцевую шину и кэш L3 совместно с P-ядрами Lion Cove. И можно себе представить, какую революцию способна произвести эта архитектура Intel в многопоточных бенчмарках.
Встроенная графика Xe-LPG в процессорах Meteor Lake – довольно впечатляющая, так как превосходит встроенную графику Radeon 780M RDNA 3 конкурирующих процессоров Ryzen 7040 Phoenix. И вот Intel заявляет полуторакратное увеличение производительности iGPU в новом поколении процессоров, использующих новую графическую архитектуру Xe2 Battlemage, которая не только предлагает улучшенную аппаратную поддержку рейтрейсинга, но также содержит полноразмерные матричные ускорители ИИ XMX, которые ранее можно было найти только в дискретных GPU Intel. Теперь технологии апскейлинга на базе ИИ, такие как XeSS, будут запускаться независимо от каналов SIMD-производительности GPU (если вы помните, iGPU Xe-LP и Xe-LPG использовали для XeSS канал DP4a). По случаю обновления графической архитектуры Intel также модернизировала дисплейный и медиадвижки, добавив аппаратную поддержку декодирования VVC и интерфейсов eDP 1.5, DP 2.1 и HDMI 2.1.
Нейропроцессор NPU 4 не просто учетверяет производительность инференсов ИИ по сравнению с NPU 3, отвечая требованиям Microsoft Copilot+, но обеспечивает этот результат без линейного роста энергопотребления. Это достигается не только благодаря более прогрессивному техпроцессу (3 нм вместо 5 нм), но и благодаря множественным архитектурным усовершенствованиям, а также улучшенной пропускной способности памяти.
Архитектура Lunar Lake будет выпускаться исключительно в виде MoP-чипов (со встроенной памятью). Она была разработана в расчете на специфический набор ускорителей, каждый из которых имеет свой уникальный профиль производительности и потребляемой мощности, по примеру чипов Apple M3 и Snapdragon Elite X с близкими характеристиками компактности, энергопотребления и времени автономной работы, но при этом превосходит их по производительности. Это стало возможным только благодаря применению встроенной памяти LPDDR5X, что обеспечило Intel гораздо лучший контроль над всеми аппаратными модулями чипа.
По этой причине мы вряд ли увидим процессоры Lunar Lake в традиционных корпусировках серий U и P. Если вы хотите посмотреть на комбинацию Lion Cove, Skymont, Xe2 Battlemage и NPU 4 в более привычной компоновке, нужно будет дождаться выхода семейства Arrow Lake, в котором будут процессоры не только для других мобильных форм-факторов, но также для настольных ПК.
Источник: www.techpowerup.com