Каталог
Доставка
Образцы документов
Новости
Поддержка
Вторник, 5 ноября 2024 15:38
Скопировано
Обзор процессора Intel Core Ultra 9 285K
Наконец-то он здесь! Долгожданный десктопный процессор Core Ultra 9 285K Arrow Lake-S в наших руках, и мы горим нетерпением рассказать вам о нем. Чип 285K – это флагманский процессор нового поколения и, по сути, свежий аналог Core i9-14900K. В нем активны все ядра, которые физически присутствуют в микросхеме – 8P+16E, и все встроенные технологии. Кроме того, он полностью разблокирован и готов к разгону.

Содержание
- Intel Core Ultra 9 285K и другие современные пользовательские процессоры
- Архитектура Arrow Lake
- Высокопроизводительное ядро Lion Cove (P)
- Энергетически эффективное ядро Skymont (E)
- Платформа Intel LGA1851
- Упаковка и внешний вид
- Тестовая конфигурация системы
- Бенчмарки
- Производительность встроенной графики
- Энергопотребление процессора в приложениях
- Сравнение энергопотребления процессоров
- Производительность NPU
- Производительность CUDIMM
- Разгон процессора
- Сравнение производительности процессоров
- Заключение
С архитектурой Arrow Lake многие решения Intel впервые приходят в настольный сегмент. Наиболее заметен среди них чиплетный дизайн микросхемы, который компания теперь применяет и в пользовательских десктопных процессорах. В мобильном сегменте эту концепцию представляет серия Core Ultra Meteor Lake, и уже несколько лет Intel делает на базе чиплетов серверные процессоры Xeon Scalable. По числу ядер и цене этот процессор попадает в прямые конкурирующие аналоги чипов AMD Ryzen 9 9950X Zen 5 и Ryzen 9 7950X3D Zen 4.
Процессор Core Ultra 9 285K предлагает максимальную конфигурацию ядер 8P+16E. В поколении Arrow Lake Intel обновила оба типа ядер. Здесь у нас восемь P-ядер Lion Cove с номинальной поколенческой прибавкой к IPC и 16 продвинутых E-ядер Skymont. Архитектура Skymont блистала в серии Lunar Lake, где Intel добавила почти 50% к IPC относительно малопотребляющих островных E-ядер Crestmont, которые использовались в предыдущем поколении Meteor Lake. В Arrow Lake ядра Skymont предлагают 32%-ное увеличение IPC по сравнению с E-ядрами Gracemont из поколения Raptor Lake. Помимо повышения IPC, эти ядра E также предлагают более высокие тактовые частоты, чем у Gracemont, что уже позволяет замахнуться на многопоточные продуктивные приложения. Технически 285K – это 24-ядерный/ 24-поточный процессор. P-ядра Lion Cove не поддерживают SMT. Поэтому любые улучшения в части многопоточной производительности относительно процессора предыдущего поколения i9-14900K следует относить на счет более быстрых ядер и новой технологии, которые перевешивают сокращение общего числа потоков.
Как мы уже упоминали, это первый десктопный чиплетный процессор Intel. Данная концепция основывается на тех соображениях, что вместо одного большого монолитного кристалла на базе новейшего техпроцесса (что дороже, так как полезный выход годных чипов с каждой вафли в этом случае меньше), Intel выгоднее «штамповать» на этом техпроцессе специализированные проприетарные блоки и уже из них делать чиплеты (это дешевле, так как полезный выход с каждой вафли получается больше благодаря меньшему размеру кристаллов). Чиплет (плитка) Compute содержит ядра CPU и базируется на техпроцессе TSMC N3B (3 нм) – более продвинутом, чем TSMC N4P (4 нм), на котором базируются CCD AMD Zen 5. Таким образом, Intel возвращает себе лидерство в части техпроцесса после пятилетнего чемпионства AMD. Встроенный графический процессор (iGPU) занимает отдельный чиплет, который базируется на все еще актуальном 5-нм техпроцессе TSMC N5, в то время как остальная часть процессора с различными контроллерами I/O и встроенным нейропроцессором (NPU) занимает чиплет на базе техпроцесса TSMC 6 нм – того же самого, на котором базируется кристалл cIOD процессоров Ryzen.
Это первый десктопный процессор Intel с NPU, хотя в нем используется и не новейший нейропроцессор Intel NPU 4, который вы найдете в мобильных чипах Core Ultra 200V Lunar Lake, а более старый NPU 3 из серии Core Ultra 100 Meteor Lake, мощность которого составляет всего 13 TOPS. Соответственно, его не хватит для нативного ускорения Microsoft Copilot+, но не расстраивайтесь – на 13 TOPS’ах можно сделать довольно много: Windows 11 может эффективно использовать этот NPU во многих своих встроенных приложениях и утилитах, то же самое относится и к Microsoft Teams. Intel оснастила чипы Arrow Lake-S довольно мощным iGPU на базе графической архитектуры Xe-LPG, а также обновленным медиадвижком, ускоряющим кодирование AV1 и HEVC. Некоторые изменения коснулись и интерфейсов I/O. Для начала, память DDR4 больше не поддерживается, так как контроллеры памяти полностью перестроены. Количество линий PCIe Gen 5, идущих от CPU, увеличено до 20, так что теперь вы можете подключать NVMe SSD Gen 5 не за счет линий графического слота PEG PCIe x16. Также есть встроенная поддержка Thunderbolt 4.
Каждое из восьми ядер P Lion Cove процессора 285K имеет базовую частоту 3.70 ГГц и максимальную boost-частоту 5.70 ГГц. Классический алгоритм Turbo Boost выводит ядра P на частоту 5.50 ГГц. Технология Turbo Boost Max 3.0 разгоняет пару ядер до 5.60 ГГц, и далее, обеспечивая работой ваш кулер, технология Thermal Velocity Boost позволяет довести частоту до 5.70 ГГц. 16 ядер E, поделенные на четыре кластера, предлагают базовую частоту 3.20 ГГц и впечатляющую boost-частоту 4.60 ГГц. Каждое ядро P имеет выделенный кэш L2 размером 3 МБ, а каждый кластер ядер E – 4-мегабайтный кэш L2 на четыре ядра. 36-мегабайтный кэш L3 является общим для всех ядер P и кластеров ядер E.
Intel Core Ultra 9 285K и другие современные пользовательские процессоры
| Процессор | Число ядер / потоков | Базовая частота, ГГц | Boost-частота, ГГц | Кэш L3, МБ | TDP, Вт | Архитектура | Техпроцесс | Сокет | |
| Intel Core i5 | |||||||||
| Core i5-12400F | 6/ 12 | 2.5 | 4.4 | 18 | 65 | Alder Lake | 10 нм | LGA 1700 | |
| Core i5-13400F | 6+4/ 16 | 2.5/ 1.8 | 4.6/ 3.3 | 20 | 65 | Raptor Lake | 10 нм | LGA 1700 | |
| Core i5-12600K | 6+4/ 16 | 3.7/ 2.8 | 4.9/ 3.6 | 20 | 125 | Alder Lake | 10 нм | LGA 1700 | |
| Core i5-13600K | 6+8/ 20 | 3.5/ 2.6 | 5.1/ 3.9 | 24 | 125 | Raptor Lake | 10 нм | LGA 1700 | |
| Core i5-14600K | 6+8/ 20 | 3.5/ 2.6 | 5.3/ 4.0 | 24 | 125 | Raptor Lake | 10 нм | LGA 1700 | |
| Intel Core Ultra 5 | |||||||||
| Core Ultra 5 245K | 6+8/ 14 | 4.2/ 3.6 | 5.2/ 4.6 | 24 | 159 | Arrow Lake | 3 нм | LGA 1851 | |
| AMD Ryzen 5 | |||||||||
| Ryzen 5 8500G | 6/ 12 | 3.5 | 5.0 | 16 | 65 | Phoenix 2 | 4 нм | AM5 | |
| Ryzen 5 8600X | 6/ 12 | 3.7 | 4.6 | 32 | 65 | Zen 3 | 7 нм | AM4 | |
| Ryzen 5 7600 | 6/ 12 | 3.8 | 5.1 | 32 | 65 | Zen 4 | 5 нм | AM5 | |
| Ryzen 5 7600X | 6/ 12 | 4.7 | 5.3 | 32 | 105 | Zen 4 | 5 нм | AM5 | |
| Ryzen 5 9600X | 6/ 12 | 3.9 | 5.4 | 32 | 65 | Zen 5 | 4 нм | AM5 | |
| Intel Core i7 | |||||||||
| Core i7-12700K | 8+4/ 20 | 3.6/ 2.7 | 5.0/ 3.8 | 25 | 125 | Alder Lake | 10 нм | LGA 1700 | |
| Core i7-13700K | 8+8/ 24 | 3.4/ 2.5 | 5.4/ 4.2 | 30 | 125 | Raptor Lake | 10 нм | LGA 1700 | |
| Core i7-14700K | 8+12/ 28 | 3.4/ 2.5 | 5.6/ 4.3 | 33 | 125 | Raptor Lake | 10 нм | LGA 1700 | |
| Intel Core Ultra 7 | |||||||||
| Core Ultra 7 265K | 8+12/ 20 | 3.9/ 3.3 | 5.5/ 4.6 | 30 | 250 | Arrow Lake | 3 нм | LGA 1851 | |
| AMD Ryzen 7 | |||||||||
| Ryzen 7 5700G | 8/ 16 | 3.8 | 4.6 | 16 | 65 | Zen 3 + Vega | 7 нм | AM4 | |
| Ryzen 7 5700X | 8/ 16 | 3.4 | 4.6 | 32 | 65 | Zen 3 | 7 нм | AM4 | |
| Ryzen 7 7700 | 8/ 16 | 3.8 | 5.3 | 32 | 65 | Zen 4 | 5 нм | AM5 | |
| Ryzen 7 7700X | 8/ 16 | 4.5 | 5.4 | 32 | 105 | Zen 4 | 5 нм | AM5 | |
| Ryzen 7 9700X | 8/ 16 | 3.8 | 5.5 | 32 | 65 | Zen 5 | 4 нм | AM5 | |
| Ryzen 7 5800X | 8/ 16 | 3.8 | 4.7 | 32 | 105 | Zen 3 | 7 нм | AM4 | |
| Ryzen 7 5800X3D | 8/ 16 | 3.4 | 4.5 | 96 | 105 | Zen 3 | 7 нм | AM4 | |
| Ryzen 7 7800X3D | 8/ 16 | 4.2 | 5.0 | 96 | 120 | Zen 4 | 5 нм | AM5 | |
| Intel Core i9 | |||||||||
| Core i9-12900K | 8+8/ 24 | 3.2/ 2.4 | 5.2/ 3.9 | 30 | 125 | Alder Lake | 10 нм | LGA 1700 | |
| Core i9-13900K | 8+16/ 32 | 3.0/ 2.2 | 5.8/ 4.3 | 36 | 125 | Raptor Lake | 10 нм | LGA 1700 | |
| Core i9-14900K | 8+16/ 32 | 3.2/ 2.4 | 6.0/ 4.4 | 36 | 125 | Raptor Lake | 10 нм | LGA 1700 | |
| Intel Core Ultra 9 | |||||||||
| Core Ultra 9 285K | 8+16/ 24 | 3.7/ 3.2 | 5.7/ 4.6 | 36 | 250 | Arrow Lake | 3 нм | LGA 1851 | |
| AMD Ryzen 9 | |||||||||
| Ryzen 9 5900X | 12/ 24 | 3.7 | 4.8 | 64 | 105 | Zen 3 | 7 нм | AM4 | |
| Ryzen 9 7900 | 12/ 24 | 3.7 | 5.4 | 64 | 65 | Zen 4 | 5 нм | AM5 | |
| Ryzen 9 7900X | 12/ 24 | 4.7 | 5.6 | 64 | 170 | Zen 4 | 5 нм | AM5 | |
| Ryzen 9 7900X3D | 12/ 24 | 4.4 | 5.6 | 128 | 120 | Zen 4 | 5 нм | AM5 | |
| Ryzen 9 9900X | 12/ 24 | 4.4 | 5.6 | 64 | 120 | Zen 5 | 4 нм | AM5 | |
| Ryzen 9 5950X | 16/ 32 | 3.4 | 4.9 | 64 | 105 | Zen 3 | 7 нм | AM4 | |
| Ryzen 9 7950X | 16/ 32 | 4.5 | 5.7 | 64 | 170 | Zen 4 | 5 нм | AM5 | |
| Ryzen 9 7950X3D | 16/ 32 | 4.2 | 5.7 | 128 | 120 | Zen 4 | 5 нм | AM5 | |
| Ryzen 9 9950X | 16/ 32 | 4.3 | 5.7 | 64 | 170 | Zen 5 | 4 нм | AM5 | |
Архитектура Arrow Lake


В микроархитектуре Intel Arrow Lake усовершенствованы все основные проприетарные блоки, из которых состоит процессор: ядра CPU, блок iGPU и платформа интерфейсов I/O, включающая в себя также NPU; но, с учетом такого опорного пункта Intel, как новейший техпроцесс TSMC 3 нм (на котором базируются, в частности, новейшие SoC Apple), общий вектор этих усилий направлен на повышение энергетической эффективности и оптимизацию температурного режима по сравнению с серией Raptor Lake, которая базировалась на 10 нм (как вам такой скачок?). Конечно, делать на базе 3 нм большой монолитный кристалл было бы очень дорого, и этим обусловлен второй ключевой пункт инженерной концепции Intel – дезагрегированная плиточная компоновка процессора с активным интерпозером. Ранее Intel применила этот подход в мобильной серии Meteor Lake и серверной серии Sapphire Rapids, и вот теперь настала очередь десктопных процессоров.


Ядра CPU располагаются на 3-нм кристалле-плитке под названием Compute. Она подключена к плитке SoC с контроллерами памяти и рут-комплексом PCIe, которая базируется на техпроцессе TSMC 6 нм (этот же техпроцесс использует и AMD для своих кристаллов I/O). Плитка SoC также содержит нейропроцессор Intel NPU 3. Блок iGPU расположен на отдельной плитке Graphics, которая базируется на достаточно продвинутом техпроцессе 5 нм. Все эти плитки сидят на плитке-подложке Foveros, которая выполняет роль интерпозера, обеспечивая густую сеть микроскопических электрических соединений между плитками и их соединение с нижней стекловолоконной подложкой чипа посредством сквозных каналов, пронизывающих кремниевый кристалл. По словам Intel, площадь чипа Arrow Lake-S (8P+16E) составляет 243 кв.мм, а общее число транзисторов – 17.8 миллиардов.
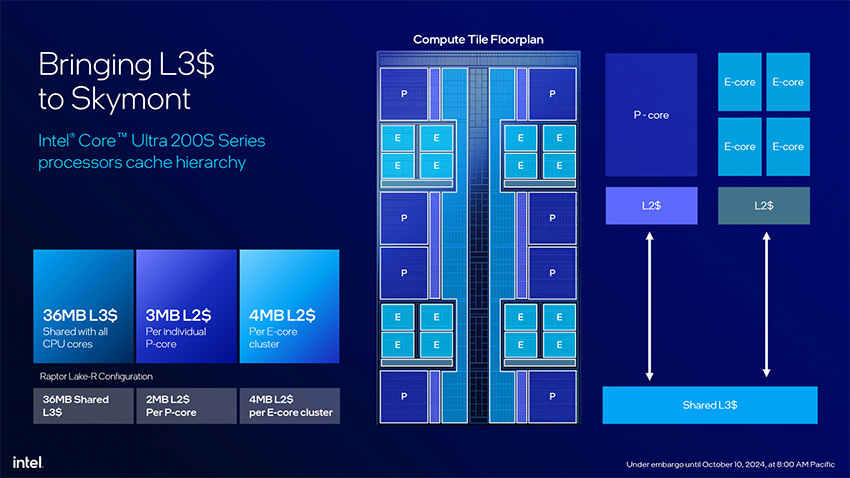

Плитка Compute – наиболее важная часть процессора, представляющая собой обособленный CPU-комплекс: восемь высокопроизводительных (P) ядер Lion Cove и 16 энергетически эффективных (E) ядер Skymont. Все 24 ядра подключены к кольцевой внутренней шине и 36-мегабайтному кэшу L3. Каждое из восьми ядер P имеет 3-мегабайтный кэш L2; ядра E сгруппированы в кластеры по четыре ядра, каждый такой кластер имеет 4-мегабайтный кэш L2 на все четыре ядра. В отличие от схем Alder Lake и Raptor Lake, здесь ядра P и кластеры E не разведены по разным углам CPU, а скомпонованы в чередующиеся ряды: ряд ядер P, потом ряд из двух кластеров E, потом два ряда ядер P, еще ряд кластеров E и, наконец, последний ряд ядер P. У этого подхода два преимущества. Во-первых, это снижает концентрацию тепла во время интенсивной нагрузки на ядра P, например, во время гейминга. Во-вторых, это снижает задержки при переносе потоков нагрузки с ядер P на ядра E и наоборот за счет сокращения участков кольцевой шины между ядрами двух типов.


Следующая по важности плитка – SoC. Она занимает центральную часть чипа и базируется на техпроцессе 6 нм. На этой плитке нет малопотребляющего "острова" из ядер E, в отличие от Meteor Lake. Единственный «тяжелый» логический компонент на этой плитке – это NPU. Также плитка содержит двухканальный контроллер и физический интерфейс памяти DDR5 и рут-комплекс PCI-Express.

Не считая шины чипсета DMI 4.0 x8, от процессора идут 20 линий PCIe Gen 5. 16 из них выделены под интерфейс PEG (для дискретной видеокарты), и еще четыре – под слот M.2 NVMe, подключенный к CPU. Фактически здесь два подключенных к CPU слота M.2. Помимо упомянутого слота Gen 5 x4, есть второй слот Gen 4 x4, также соединенный с процессором. Это соединение идет от плитки I/O, которая также содержит встроенный контроллер Thunderbolt 4 40 Гбит/с. Плитка SoC содержит, кроме того, три блока, относящиеся к iGPU: дисплейный движок (Display Engine), медиаускоритель (Media Acceleration Engine) и блок дисплейных интерфейсов (Display I/O).


В серии Arrow Lake Intel развертывает второе поколение своих контроллеров памяти DDR5, снимая поддержку памяти DDR4. Предыдущая концепция контроллеров памяти Alder Lake и Raptor Lake включала в себя два контроллера, каждый из которых управлял одним каналом и обоими его 40-разрядными подканалами; в режиме DDR4 это соответствовало одному контроллеру на канал памяти. В новой архитектуре Intel без поддержки DDR4 каждый из двух контроллеров памяти управляет соответствующими подканалами «своего» и другого канала. То есть первый контроллер управляет первыми подканалами, а второй контроллер – вторыми подканалами обоих каналов памяти. Этот подход Intel должен обеспечивать более эффективное использование параллелизма подканалов DDR5.
Процессоры Arrow Lake-S поддерживают до 192 ГБ двухканальной памяти с плотностью до 48 ГБ на модуль DIMM. Они предлагают нативную поддержку JEDEC DDR5-6400, и, по словам Intel, "золотой серединой" для разгона памяти является скорость DDR5-8000. Процессоры также поддерживают и более быстрые опции разогнанной памяти. Уже анонсирована память DDR5-9600, и в течение 2025 года мы должны увидеть скорости памяти за 10000 MT/с, благодаря внедрению модулей памяти CUDIMM или CSODIMM со встроенными тактовыми генераторами (CKD). Поддержка ECC обеспечивается архитектурой, хотя на сегодняшний день не анонсирована ни на чипсете Z890, ни на моделях процессоров.


Плитка SoC содержит блок NPU 3, который был перенесен из Meteor Lake. Он базируется на архитектуре NPU Intel 3-го поколения, в отличие от NPU 4-го поколения в серии Lunar Lake. В вычислениях с применением ИИ NPU 3 предлагает пиковую мощность 13 TOPS, что явно не дотягивает до системных требований для локального ускорения Microsoft Copilot+ – 40 TOPS. Нейропроцессор содержит два движка NCE (Neural Compute Engine) с двумя массивами накопительных умножителей MAC INT8/FP16, четырьмя DSP SHAVE и 4 МБ SRAM.


Третий ключевой компонент процессора Arrow Lake – плитка Graphics, которая базируется на графической архитектуре Xe-LPG, что интересно, на поколение более старой, чем Xe2, лежащая в основе iGPU Lunar Lake. Плитка Graphics базируется на 5-нм техпроцессе TSMC N5P. Graphics содержит только вычислительные и рендеринговые механизмы iGPU в виде одного слайса Xe Rendering Slice с четырьмя ядрами Xe, которые включают в себя 64 исполнительных блока (EU), или 512 унифицированных шейдеров. В ядрах Xe встроенного графического компонента Arrow Lake отсутствуют блоки XMX. Любое ускорение ИИ осуществляется за счет инструкций DP4a, а не XMX. Мобильные чипы "Arrow Lake-HX" для энтузиастов используют точно такую же плитку Graphics. С другой стороны, линейка "Arrow Lake-H" выпускается с большей плиткой Graphics, которая содержит восемь ядер Xe (128 EU, 1024 унифицированных шейдера), причем в этих ядрах Xe есть блоки XMX. Несмотря на наличие всего четырех ядер Xe, плитки Graphics в чипах "Arrow Lake-S" и "Arrow Lake-HX" содержат аппаратные блоки поддержки рейтрейсинга, по одному на каждое ядро, что позволяет этим процессорам осуществлять полную поддержку DirectX 12 Ultimate. Intel также снабдила этот iGPU довольно большим 4-мегабайтным кэшем L2, который улучшает пропускную способность каналов передачи данных между плитками Graphics и SoC.

Медиадвижок в "Arrow Lake-S" обеспечивает аппаратное ускорение видео с параметрами до 8K @ 60 Гц с 10-битнымt HDR, при этом поддерживаются форматы VP9, AVC, HEVC, AV1 и SSC. Аппаратное ускорение кодирования осуществляется на разрешениях до 8K с частотой кадров 120 Гц и 10-битным HDR, поддерживаемые форматы –VP9, AVC, HEVC и AV1. Дисплейный движок поддерживает до четырех подключенных дисплеев и до пяти дисплейных портов. Поддерживаются стандарты HDMI 2.1, DisplayPort 2.1 и eDP 1.4. Параметры выходного сигнала: один дисплей 8K @ 60 Гц HDR, или четыре дисплея 4K @ 60 Гц HDR, или один дисплей 1080p/ 1440p @ 360 Гц.
Высокопроизводительное ядро Lion Cove (P)


Новое P-ядро "Lion Cove" пришло на смену ядру предыдущего поколения "Raptor Cove", став основной вычислительной силой Arrow Lake. Это же P-ядро используется в Lunar Lake, и, как и там, P-ядра Arrow Lake сидят на кольцевой шине с общим кэшем L3. Однако в части кэшей есть небольшая разница: выделенный кэш L2 каждого ядра P в Arrow Lake увеличен до 3 МБ – против 2.5 МБ в Lunar Lake. Восемь ядер P вместе с кластерами ядер E используют общий 36-мегабайтный кэш L3, который тоже вырос по сравнению с 12-мегабайтным в Lunar Lake. Для "Lion Cove" в Arrow Lake Intel заявила новые прибавки к IPC: плюс 9% относительно IPC ядра "Raptor Cove" из серии Raptor Lake-S. Анонсируя архитектуру Lunar Lake, компания заявила 14%-ную прибавку к IPC, но это было заявлено относительно P-ядра "Redwood Cove" в 15-ваттных процессорах Meteor Lake, так как семейство Lunar Lake относится к полностью встраиваемым чипам, у которых нет прямых предшественников, кроме сопоставимых с ними по классу мощности представителей Meteor Lake.
Как и в Lunar Lake, в Arrow Lake ядра P "Lion Cove" не поддерживают многопоточность. Intel физически убрала компоненты ядра, отвечающие за SMT. Это было сделано с целью уменьшения размера ядра и в пользу той идеи, что повышение IPC и энергетической эффективности наряду с физическими потоками ядер E дает больше преимуществ, чем SMT. За счет освободившихся в результате упразднения SMT площади кристалла и запаса мощности Intel перестроила саму микроархитектуру. Были усовершенствованы все ключевые компоненты, в том числе фронт конвейера и блок предсказания ветвлений, который был увеличен в восемь раз. Была увеличена пропускная способность блоков выборки и декодирования. Повышена емкость кэша микроопераций, плюс Intel ввела концепцию "наноопераций", которые представляют собой группы параллельно выполняемых подзадач микроопераций. Целочисленный (Integer) и векторный (Vector) блоки движка внеочередного выполнения команд теперь имеют раздельный доступ к очереди микроопераций, с независимыми планировщиками. Очередь переименований/перемещений во внеочередном движке теперь расширена до восьми позиций (с шести в Redwood Cove). Очередь отставки команд расширена в полтора раза, с восьми до 12 позиций. Глубина окна команд увеличена с 512 до 576 позиций. Количество исполнительных портов увеличено с 12 до 18.
Количество ALU в движке Integer увеличено с пяти до шести, блоков адресного перехода – с двух до трех, блоков сдвига – с двух до трех, блоков умножения (MUL) – с одного до трех. Векторный исполнительный движок теперь содержит четыре SIMD ALU вместо трех, два 4-цикловых блока команд FMA и два блока деления. Подсистема загрузки/записи адресов (Load/Store) демонстрирует буфер DTLB, размер которого увеличен с 96 до 128 записей, и три генератора адресов STE вместо двух.
Intel также перестроила подсистему кэшей на уровне ядра, введя промежуточный кэш данных между 48-килобайтным кэшем L1 и кэшем 2-го уровня L2. Кэш L1D теперь определяется как D-кэш нулевого уровня L0, данные из которого перемещаются в 192-килобайтный D-кэш L1, а тот, в свою очередь, передает данные в кэш L2. В поколении Arrow Lake каждое ядро Lion Cove получает 3-мегабайтный (3072 КБ) выделенный кэш L2. Также Intel разработала новую ИИ-систему управления питанием ядер P, которая контролируется блоками SMU самих ядер. Тактовая частота ядер P теперь имеет шаг дискретизации 16.67 МГц.
Энергетически эффективное ядро Skymont (E)


Новые E-ядра "Skymont" стали самым замечательным пунктом в концепции Lunar Lake. Здесь Intel удалось повысить IPC относительно E-ядер "Crestmont" чипов Meteor Lake на 38% в целочисленных нагрузках и на исполинские 68% – в нагрузках с плавающей точкой. Но здесь есть одна хитрость. В Lunar Lake ядра E не сидят на кольцевой шине вместе с ядрами P (то есть не делят с ними кэш L3), а сгруппированы в отдельный малопотребляющий "островной" E-кластер, поэтому Intel может сравнивать их показатели IPC с аналогичными показателями E-ядер "Crestmont" из Meteor Lake, которые тоже образуют малопотребляющий остров, расположенный на плитке SoC. Отличие Arrow Lake – в том, что теперь все кластеры E-ядер "Skymont" входят в схему кольцевой шины плитки Compute и делят кэш L3 с ядрами P. Поэтому их показатели IPC сравниваются с показателями E-ядер "Gracemont" чипов Raptor Lake-S. С учетом всего этого, компания заявляет для ядер "Skymont" в Arrow Lake 32%-ное увеличение IPC относительно "Gracemont", что можно считать впечатляющей поколенческой прибавкой.
Это 32%-ное увеличение IPC E-ядер "Skymont" в Arrow Lake играет ключевую роль в обеспечении результирующей поколенческой прибавки к многопоточной производительности, несмотря на то, что ядра P больше не поддерживают Hyper-Threading. 16 ядер E в Arrow Lake сгруппированы в кластеры по четыре ядра, и каждый кластер использует 4-мегабайтный кэш L2, общий для его четырех ядер. Intel заявляет для этого кластерного кэша L2 удвоенную пропускную способность по сравнению с кластерами E-ядер "Gracemont" в Raptor Lake-S.
Отличительные особенности архитектуры Skymont начинаются с блоков выборки и предсказания ветвлений, где на возможные ветвления теперь отведено 128 байт, что ускоряет выборку команд. Параллельно могут извлекаться 96 байт команд. Фронт конвейера содержит новый 9-позиционный декодер команд (против 6-позиционного в Crestmont), поддержку нанокодов (аналогичные сегменты микрокода, сгруппированные вместе для параллельного выполнения) и расширенную очередь микроопераций – до 96 записей вместо 64-х в предыдущем поколении.
Движок внеочередного выполнения команд получил самые весомые модернизации. Распределяемая очередь расширена с шести до восьми позиций, очередь отставки команд – с восьми до 16 позиций. Независимый доступ к очереди позволяет снизить задержку. Окно внеочередных команд расширено с 256 до 416 записей, также увеличены физические размеры регистровых файлов, глубина станций резервирования и глубина буфера подсистемы Load/Store.
К исполнительному движку Integer подключено 26 портов отправки, ведущих к восьми целочисленным ALU с тремя портами адресного перехода и тремя загрузками в каждом цикле (вместо двух в предыдущем поколении).
Векторный движок содержит четыре 128-разрядных модуля FPU, удваивающих гигафлопсы. Задержки в вещественных блоках FMUL, FADD и FMA снижены. Для округления чисел с плавающей запятой теперь предусмотрено аппаратное ускорение. Дополнительные исполнительные блоки также должны улучшать производительность ИИ. Производительность блока загрузки/ сохранения адресов Load/Store по сравнению с предыдущим поколением выросла на 33%/ 50%. Размер буфера TLB L2 увеличен с 3096 до 4192 записей.
Модернизированный Thread Director


В серии Arrow Lake Intel представляет 3-е поколение Thread Director, аппаратного планировщика, который гарантирует правильное распределение нагрузок по соответствующим типам ядер CPU. Новая версия планировщика содержит более точный механизм обратной связи, который выдает информацию о доступных ресурсах ядер E. Intel также вводит новый механизм телеметрии производительности ядер P для более точного перевода нагрузки на ядра P. Кроме того, в новом Thread Director Intel применяет свою самую точную на сегодняшний день модель предсказания нагрузок. Модернизированные ядра "Skymont" имеют настолько высокую производительность IPC, что Thread Director в Arrow Lake-S априорно отправляет все неигровые нагрузки (продуктивные приложения) на ядра E и только по мере необходимости переводит потоки на ядра P. Thread Director играет важную роль в повышении общей энергетической эффективности процессора.
Платформа Intel LGA1851


Новый сокет LGA1851 сохраняет совместимость с кулерами для LGA1700. Корпусировки процессоров имеют одинаковые габариты и высоту (Z-Height), что облегчает установку совместимых кулеров, но в части самих процессоров вы не сможете установить чип LGA1700 в сокет LGA1851. Помимо всего прочего, этому препятствуют дополнительные контактные площадки для новых четырех линий PCIe Gen 5, идущих от процессора, благодаря которым подключаемый к CPU накопитель NVMe SSD Gen 5 не будет отъедать линии у слота PEG x16.


Для этого сокета выпущено две разновидности модуля ILM (independent loading module), и некоторые премиальные модели материнских плат идут в комплекте с новым ILM-модулем с пониженной нагрузкой (reduced load ILM, RL-ILM), который снижает давление на корпусировку чипа со стороны прижимного механизма, что позволяет устанавливать на процессор более тяжелые кулеры, например, испарители с жидким азотом. Маркировка RL-ILM четко видна на металлической скобе. Еще один отличительный признак – белая изолирующая прокладка под ILM в районе крепежных винтов.

Новый сокет LGA1851 Intel презентует вместе с серией процессоров Core Ultra 2 "Arrow Lake-S". Следовательно, для нового блестящего процессора вам потребуется новая материнская плата, и, поскольку все выпускаемые в этом году модели процессоров Intel являются разблокированными (K или KF), единственным вариантом чипсета пока остается топовый Z890. В следующем году Intel расширит модельную линейку и одновременно с этим начнут выходить материнские платы на более бюджетных чипсетах.
SoC процессора Arrow Lake-S предлагает двухканальный интерфейс памяти DDR5, описанный в разделе «Архитектура». Также платформа (CPU + чипсет) предлагает целых 48 линий PCIe. В части CPU Intel увеличила количество линий PCIe Gen 5 до двадцати – 16 линий для PEG (слот x16 для дискретных видеокарт) плюс подключенный к CPU 4-линейный слот M.2 NVMe, который теперь может задействовать скорости Gen 5, не занимая линии слота PEG х16. От процессора идет второй набор линий Gen 4 x4, который может использоваться для подключения еще одного слота M.2 или предустановленного на плате высокоскоростного устройства, например, дискретного контроллера Thunderbolt 5. Сам процессор имеет встроенный контроллер Thunderbolt 4 на два порта 40 Гбит/с.
Процессор подключается к чипсету Z890 через шину DMI 4.0 x8 (по пропускной способности сопоставима с PCI-Express 4.0 x8). От чипсета идут 24 линии PCI-Express Gen 4. Это существенный прогресс по сравнению с Z790, у которого было 16 линий Gen 4 и восемь линий Gen 3. Встроенный USB-комплекс состоит из 32 сериализаторов/десериализаторов USB 3.2 5 Гбит/с, которые могут быть сконфигурированы производителем материнской платы в пять портов 20 Гбит/с, 10 портов 10 Гбит/с и 10 портов 5 Гбит/с. Также имеется 14-портовый хаб USB 2.0. В модели Z890 Intel убрала аудиоинтерфейс HDA "Azalia", и это значит, что аудиокодеки материнских плат будут использовать более новые интерфейсы MIPI SoundWire и USB 3.2 (что уже делают, например, Realtek ALC4080 и ALC4082).

Чипсет предлагает MAC-адаптер 1 GbE и Wi-Fi 6. С такими ресурсами PCIe и USB 3.2 производители материнских плат могут потерять голову от возможностей сетевых подключений, оснащая свои платформы опциями Wi-Fi 7 и 2.5 GbE, или даже 5 GbE и 10 GbE. Производители могут выбрать комплексное сетевое решение Intel Killer, которое сочетает в себе существующий физический сетевой интерфейс Intel и продвинутый приоритизационный движок Killer с технологией DoubleShot Pro, что в совокупности позволяет снизить задержку во время гейминга. В поколении клиентских процессоров Arrow Lake Intel обновила архитектуру подсистемы защиты данных, включив в нее три отдельных аппаратных движка, а именно: специализированный движок Converged Security and Manageability Engine (по существу, Intel ME с дополнительными функциями безопасности), Silicon Security Engine, который стабилизирует новые ядра Lion Cove и Skymont на уровне микроархитектуры, и новый отдельный контроллер безопасности iGPU; новые аппаратные компоненты поддерживают концепцию защищенного ядра Microsoft Secured Core.
Разгон


Основная идея Arrow Lake – обеспечить традиционную поколенческую прибавку к производительности в типовых аспектах, но при этом сделать большой скачок в энергетической эффективности за счет нового дезагрегированного плиточного дизайна чипа и перевода ключевых логических компонентов процессора на новый техпроцесс 3 нм. С другой стороны, высокая энергетическая эффективность подразумевает некоторое пространство для разгона. В Arrow Lake впервые применяется архитектура с двумя доменами базовой частоты. Теперь у нас два независимых домена BCLK: один для плитки Compute, другой для плитки SoC. Это играет ключевую роль в обеспечении оверклокинга на базе BCLK без дестабилизации других тактовых доменов, таких как домен частоты PCIe, которые будут привязаны к домену BCLK на плитке SoC.
Кроме того, Intel ввела шаг дискретизации 16.67 МГц для тактовых частот ядер P и E, что обеспечивает намного более точную настройку разгона. Фабрика плитка-плитка имеет свой собственный тактовый домен, который можно разогнать или с помощью статической настройки частоты, или через соотношение с тактовыми частотами CPU. Байпас DLVR (digital linear voltage regulator, цифровой линейный регулятор напряжения) позволяет некоторым премиальным моделям материнских плат обойти внутреннюю систему управления напряжением процессора, используя умные дискретные контроллеры напряжения для продвинутого оверклокинга. Процессоры Arrow Lake поддерживают управление кривой V/f на уровне отдельных ядер P и кластеров E с помощью блоков SMU. Блок SMU может определять в сценарии оверклокинга высокую интенсивность охлаждения или ограничение напряжения байпаса, если чип охлаждается. Наконец, Arrow Lake предлагает нативную поддержку модулей памяти CUDIMM и CSODIMM. Это модули памяти DDR5 со встроенным тактовым генератором CKD (client ClocK Driver), который улучшает качество сигнала на более высоких частотах. Некоторые новые комплекты памяти с профилями XMP за 8000 MT/с предлагают именно модули CUDIMM. Обновленная система управления питанием, переход на более новый техпроцесс TSMC 3 нм (в тех блоках, где это важно) и другие оптимизации дали в результате, помимо снижения энергопотребления, также снижение средней температуры корпусировки чипа 285K примерно на 13°C по сравнению с i9-14900K. Для слабонагруженных сценариев Intel заявляет 58%-ное снижение энергопотребления по сравнению с i9-14900K.
Упаковка и внешний вид

Процессор Intel Core Ultra 9 285K поставляется в специальной розничной упаковке: коробка с футляром как для ювелирных изделий, который выглядывает из бокового окошка. На переднюю сторону коробки нанесены отражающие элементы, являющиеся отличительной особенностью розничной упаковки флагманского процессора этой серии.

Сам чип внешне очень похож на процессор LGA1700, но он действительно не подходит для более старых материнских плат. Одинаковые габаритные размеры процессоров обеспечивают совместимость кулеров, но расположение установочных пазов у них отличается. Intel выделила пространство для еще 151 контакта, убрав "остров" в середине матрицы контактных площадок.

Последовательность действий при установке процессора LGA1851 в сокет – точно такая же, как при установке процессора LGA1700.
Тестовая конфигурация системы
- Все приложения, игры и процессоры тестировались на аппаратных конфигурациях и с драйверами из таблиц ниже – никакие другие результаты в обзоре не приводятся.
- Все игры и приложения тестировались на всех конфигурациях в одной и той же версии.
- Во всех играх, если не указано иное, были установлены максимальные настройки качества изображения.
Теперь, когда технологии DDR5 достигли определенной степени зрелости, мы будем использовать более быструю память DDR5 с более строгими таймингами (в ближайших обзорах, когда перетестируем все наши 40 с лишним процессоров). На материнской плате ASUS Z890 Hero четыре фазы VRM процессора питаются от 24-пинового коннектора ATX, вместо 8-пиновых, из-за чего невозможно измерить отдельно энергопотребление CPU без специального оборудования (программным датчикам мощности CPU мы в принципе не доверяем). Вы или теряете некоторую часть мощности, поскольку проводите измерения только на двух 8-пиновых коннекторах CPU, или получаете результат, включающий в себя энергопотребление процессора, видеокарты и накопителей, если проводите измерения на двух 8-пиновых коннекторах вместе с 24-пиновым ATX. По этой причине в тестах с измерением энергопотребления процессора мы использовали плату MSI Z890 Carbon.
| Платформа Arrow Lake | |
| Процессор | Все процессоры серии Intel Core 200 (заводские настройки лимитов мощности Intel/ ASUS MCE отключено) |
| Материнская плата | ASUS Z890 Maximus Hero BIOS 0805 MSI Z890 Carbon (в тестах на энергопотребление) BIOS 1A2T |
| Память | 2x 16 GB DDR5-6000 36-36-36-76 2T / Gear 2 |
| Видеокарта | PNY GeForce RTX 4090 XLR8 |
| Накопитель | 2 TB M.2 NVMe SSD |
| Воздушный кулер | Noctua NH-D15 |
| Водяной кулер | Arctic Liquid Freezer III 420 mm AIO |
| Термопаста | Arctic MX-6 |
| Блок питания | Thermaltake Toughpower GF3 1200 W ATX 3.0 / 16-pin 12VHPWR |
| Операционная система | Windows 11 Professional 64-bit 23H2 VBS включено (в Windows 11 по умолчанию) |
| Драйверы | NVIDIA GeForce 555.85 WHQL |

| Платформа Zen 4/ Zen 5 | |
| Процессор | Все процессоры серий AMD Ryzen 9000, 8000 и 7000 |
| Материнская плата | ASUS X670E Crosshair Hero BIOS 2007 Ryzen 9000: BIOS 2201 |
| Память | 2x 16 GB DDR5-6000 36-36-36-76 Infinity Fabric @ 2000 MHz |
| Драйверы | Ryzen Chipset Drivers 6.05.28.016 Ryzen 9000: 6.06.28.910 Ryzen 9900X и 9950X: Game Mode включено, Game Bar установлено и включено |
| Платформа Raptor Lake/ Alder Lake | |
| Процессор | Все процессоры Intel 14-го, 13-го и 12-го поколений (заводские настройки лимитов мощности Intel/ ASUS MCE отключено) |
| Материнская плата | ASUS Z790 Maximus Dark Hero BIOS 1302 |
| Память | 2x 16 GB DDR5-6000 36-36-36-76 2T / Gear 2 |
| Остальные спецификации см. в таблице выше | |
| Платформа Zen 3/ Zen 2 | |
| Процессор | Все процессоры серий AMD Ryzen 5000 и Ryzen 3000 |
| Материнская плата | ASUS X570 Crosshair VII Dark Hero BIOS 4805 |
| Память | 2x 16 GB DDR4-3600 14-14-14-34 1T Infinity Fabric @ 1800 MHz 1:1 |
| Драйверы | Ryzen Chipset Drivers 6.05.28.016 |
| Остальные спецификации см. в таблице выше | |
| Платформа Rocket Lake | |
| Процессор | Все процессоры Intel 11-го поколения (заводские настройки лимитов мощности Intel/ ASUS MCE отключено) |
| Материнская плата | ASUS Z590 Maximus XIII Hero BIOS 1701 |
| Память | 2x 16 GB DDR4-3600 14-14-14-34 1T Gear 1 |
| Остальные спецификации см. в таблице выше | |
| Платформа Zen 1 | |
| Процессор | Все процессоры серии AMD Ryzen 2000 |
| Материнская плата | ASUS X570 Crosshair VII Dark Hero BIOS 4805 |
| Память | 2x 16 GB DDR4-3400 14-14-14-34 1T |
| Остальные спецификации см. в таблице выше | |
Бенчмарки
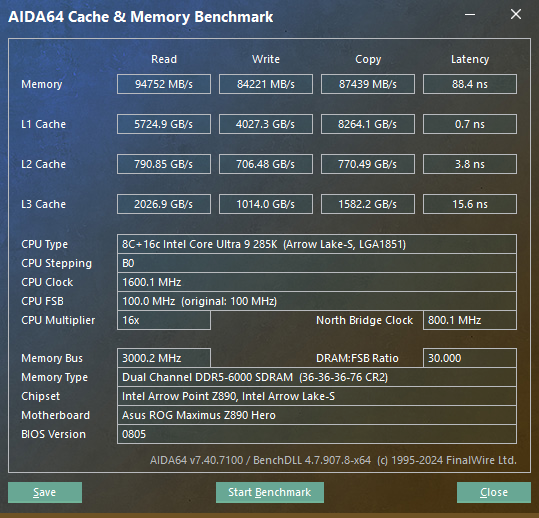
Производительность кэшей и подсистемы памяти: AIDA64
В первом тесте мы посмотрим на производительность подсистемы памяти и кэшей процессора всех уровней: L1, L2 и L3. AIDA64 предлагает отличный бенчмарк, дающий полную картину этих характеристик производительности.
Y-Cruncher
Y-Cruncher – это хорошо оптимизированное полностью многопоточное приложение для вычисления «пи» и других бесконечных констант с большим количеством знаков после запятой. Приложение использует современный программный код, оптимизированный под все основные архитектуры процессоров. Благодаря этому Y-Cruncher стал популярным инструментом среди компьютерных энтузиастов, которые используют его для тестирования и сравнения производительности разогнанных систем.
Y-Cruncher
Pi, 2.5 Billion Digits
Lower is Better
Ryzen 9 7950X
Ryzen 9 7950X3D
Ryzen 9 7900X
Ryzen 9 9950X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 9900X
Ryzen 9 7900
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-14900K
Core i9-13900K
Ryzen 7 9700X
Ryzen 7 7700X
Core Ultra 5 245K/Power Limits Removed
Core i7-14700K
Ryzen 7 7700
Ryzen 7 7800X3D
Core i7-13700K
Core i9-12900K
Core Ultra 5 245K/Stock
Ryzen 5 9600X
Core i5-14600K
Ryzen 9 5950X
Ryzen 5 7600X
Core i5-13600K
Ryzen 7 5800X3D
Core i5-13400F
Шахматное моделирование
Создание достойного компьютерного соперника для игры в шахматы на протяжении десятилетий остается для программистов одной из самых увлекательных задач. В этом тесте мы измеряем скорость расчета оптимальных ходов в шахматном сценарии с помощью популярного шахматного движка Stockfish. Каждый процессор использует здесь свой быстрейший набор поддерживаемых инструкций, в числе которых: AVX512-VNNI, AVX256-VNNI, AVX512, BMI2 и AVX2.
Chess
Stockfish
Higher is Better
Ryzen 9 9950X
Ryzen 9 7950X
Ryzen 9 7950X3D
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 9900X
Core i9-14900K
Core i9-13900K
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 7900X
Core Ultra 7 265K/Stock
Core i7-14700K
Core i7-13700K
Ryzen 9 7900
Core i9-12900K
Ryzen 9 5950X
Ryzen 7 9700X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-14600K
Ryzen 7 7700X
Core i5-13600K
Ryzen 7 7800X3D
Ryzen 7 7700
Ryzen 5 9600X
Ryzen 5 7600X
Ryzen 7 5800X3D
Core i5-13400F
Работа в веб-браузере: JetStream 2
Бенчмарк JetStream 2 включает в себя несколько тестовых сценариев JavaScript и WebAssembly с различными продвинутыми нагрузками и показывает, насколько быстро браузер выполняет конкретные задачи. Результат учитывает не только хорошую общую (среднюю) производительность, но также скорость открывания страниц и стабильно высокую скорость работы.
Web Browsing
JetStream 2
Higher is Better
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 9 7950X3D
Ryzen 7 7700X
Core i9-14900K
Ryzen 5 7600X
Core i9-13900K
Ryzen 9 7900
Ryzen 7 7700
Core i7-14700K
Core i7-13700K
Ryzen 7 7800X3D
Core i5-14600K
Core i9-12900K
Core i5-13600K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 5950X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 7 5800X3D
Core i5-13400F
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Работа в веб-браузере: Speedometer 2
Speedometer 2 оценивает скорость работы веб-приложения для списка дел ("to-do list"), которое задействует большое количество популярных библиотек, как то: React, Ember.js, AngularJS, vue.js, jQuery и др. – эти библиотеки используют все ведущие мировые сайты.
Web Browsing
Speedometer 2.0
Higher is Better
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Core i9-14900K
Core i7-14700K
Ryzen 9 7950X3D
Core i9-13900K
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 5 7600X
Ryzen 7 7700
Core i7-13700K
Core i5-14600K
Ryzen 9 7900
Core i5-13600K
Core i9-12900K
Ryzen 7 7800X3D
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i5-13400F
Ryzen 9 5950X
Ryzen 7 5800X3D
Производительность ИИ-инференса: GPT-2
Искусственный интеллект и машинное обучение позволяют нам создавать приложения с почти сказочными возможностями. GPT-2 – это мощная языковая модель от компании OpenAI, разработавшей бота ChatGPT, который умеет генерировать текст, по качеству близкий к сочинениям человека. Этот сценарий имеет ключевое значение, поскольку он показывает эффективность и возможности использования моделей ИИ для решения сложных языковых задач, что крайне важно для многих практических областей. Здесь мы измеряем время, за которое бот сочиняет 100 сказок, начинающихся с "Однажды, давным-давно".
Machine Learning/AI
GPT2/Inference
Lower is Better
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-14900K
Core i9-13900K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i7-14700K
Core i7-13700K
Core i5-14600K
Core i5-13600K
Ryzen 9 9950X
Core i9-12900K
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 9 7950X
Ryzen 9 7950X3D
Ryzen 9 7900X
Ryzen 5 9600X
Core i5-13400F
Ryzen 9 7900
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 7 7800X3D
Ryzen 5 7600X
Ryzen 9 5950X
Ryzen 7 5800X3D
Производительность ИИ-инференса: Stable Diffusion
Stable Diffusion представляет вторую популярную область применения ИИ. Эта продвинутая модель для генерации изображений создает детализированные картинки высокого качества по текстовым описаниям. Возможности этой модели находят применение в таких отраслях, как художественное оформление, дизайн, реклама и медиа, где помогают разработчикам контента в создании реалистичной визуализации словесных образов. Здесь мы измеряем время, затрачиваемое на генерацию одной картинки по запросу "фотография астронавта, едущего на лошади по Марсу".
Machine Learning/AI
Stable Diffusion/Inference
Lower is Better
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 9950X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 9 7950X
Ryzen 9 7950X3D
Ryzen 9 9900X
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 9 7900X
Core i7-13700K
Ryzen 9 5950X
Ryzen 9 7900
Core i9-12900K
Ryzen 7 9700X
Core i5-14600K
Core i5-13600K
Ryzen 7 7700X
Ryzen 7 7800X3D
Ryzen 7 7700
Ryzen 5 9600X
Ryzen 7 5800X3D
Core i5-13400F
Ryzen 5 7600X
Производительность ИИ-инференса: масштабирование изображений
Topaz Photo AI – это первейший инструмент для продвинутой обработки изображений с помощью ИИ. Он повышает разрешение и качество изображения за счет интеллектуального восстановления детализации и снижения шумов. Это продвинутое приложение позволяет улучшить четкость и резкость ассетов (графических заготовок), что делает его полезным для всех, кому нужно получить картинку в высоком разрешении. В нашем тесте измеряется время масштабирования изображения с разрешения 1.5 мегапикселя до 22 мегапикселей.
Machine Learning/AI
Photo Enhancement/Inference
Lower is Better
Ryzen 9 9950X
Ryzen 9 7950X
Ryzen 9 7950X3D
Ryzen 9 9900X
Ryzen 9 7900X
Ryzen 7 9700X
Ryzen 9 7900
Ryzen 5 9600X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 7 7800X3D
Ryzen 5 7600X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 5950X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 7 5800X3D
Core i9-14900K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i9-13900K
Core i7-14700K
Core i7-13700K
Core i9-12900K
Core i5-14600K
Core i5-13600K
Core i5-13400F
Обучение ИИ: обработка естественного языка
Обработка естественного языка (Natural Language Processing, NLP) включает в себя обучение моделей ИИ пониманию и генерированию человеческого языка. Благодаря применению методов и алгоритмов машинного обучения моделей ИИ анализу и интерпретации текстовых данных NLP позволяет поручать ИИ такие задачи, как перевод, анализ тональности и генерация текста. В этом тесте мы измеряем время изучения языковой моделью BERT подборки кинорецензий.
Machine Learning/AI
Language Processing/Training
Lower is Better
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-14900K
Core i9-13900K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i7-14700K
Ryzen 9 9950X
Core i7-13700K
Core i5-14600K
Core i9-12900K
Core i5-13600K
Ryzen 9 7950X
Ryzen 9 9900X
Ryzen 9 7950X3D
Ryzen 9 7900X
Ryzen 9 7900
Core i5-13400F
Ryzen 7 9700X
Ryzen 9 5950X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 7 7800X3D
Ryzen 5 9600X
Ryzen 5 7600X
Ryzen 7 5800X3D
Обучение ИИ: классификация изображений
Классификация изображений – крайне важный сценарий для ИИ, так как распознавание определенных объектов в кадре имеет значение во многих практических областях, включая беспилотный транспорт, распознавание лиц, анализ медицинских снимков и компьютерную инвентаризацию. Процесс обучения задействует алгоритмы анализа изображений и выделения характерных признаков объектов. В ходе обучения модели изучают образцы объектов и признаков на размеченных датасетах. В нашем тесте измеряется время, за которое модель на нескольких тысячах примеров изображений обучается классифицировать фото предметов гардероба по категориям "футболки", "сумки" и "пуловеры".
Machine Learning/AI
Classify Image/Training
Lower is Better
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 9 9950X
Core i7-13700K
Core i9-12900K
Ryzen 9 7950X
Ryzen 9 9900X
Core i5-14600K
Core i5-13600K
Ryzen 9 7950X3D
Ryzen 9 7900X
Ryzen 9 7900
Ryzen 7 9700X
Ryzen 9 5950X
Ryzen 7 7700X
Core i5-13400F
Ryzen 7 7700
Ryzen 7 7800X3D
Ryzen 5 9600X
Ryzen 5 7600X
Ryzen 7 5800X3D
Эмулятор Sony PS3
RPCS3 – популярный эмулятор консоли PlayStation 3 для ПК, который позволяет играть во многие игры для Sony PS3 на десктопе. Этот эмулятор предъявляет довольно высокие требования к «железу», причем некоторые эмуляционные потоки должны постоянно взаимодействовать друг с другом, что делает RPCS3 серьезной нагрузкой для многих архитектур CPU. RPCS3 также использует преимущества более быстрых кэшей и более быстрой памяти, если таковые имеются. Поддержка AVX-512 включена, при ее наличии, в том числе на платформах Zen 4 и Zen 5.
PS3 Emulation
RPCS 3/Red Dead Redemption
Higher is Better
Ryzen 9 7950X
Ryzen 9 7900X
Core i9-14900K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 7 9700X
Ryzen 9 7950X3D
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 9 7900
Core i7-14700K
Ryzen 5 9600X
Core i9-13900K
Core Ultra 5 245K/Power Limits Removed
Ryzen 7 7800X3D
Core Ultra 5 245K/Stock
Ryzen 7 7700X
Core i7-13700K
Ryzen 7 7700
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i5-14600K
Core i9-12900K
Core i5-13600K
Ryzen 5 7600X
Ryzen 9 5950X
Core i5-13400F
Ryzen 7 5800X3D
Эмулятор Nintendo Switch
Ryujinx – это совместимый со многими платформами полнофункциональный эмулятор консоли Nintendo Switch. Он существенно нагружает CPU и, кроме того, включает в себя ряд сложностей в части использования модуля управления памятью (MMU) процессора для управления эмулируемой средой. Несмотря на многопоточность этого приложения, более высокая производительность одного ядра здесь имеет большее значение, чем возможности масштабирования нагрузки на большее число ядер.
Switch Emulation
Ryujinx/Super Mario Kart 8
Higher is Better
Ryzen 9 7950X
Ryzen 7 7800X3D
Ryzen 7 9700X
Ryzen 9 9950X
Ryzen 9 7900X
Ryzen 9 7950X3D
Ryzen 9 9900X
Ryzen 5 9600X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 9 7900
Ryzen 5 7600X
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i5-14600K
Core i7-13700K
Core Ultra 9 285K/Power Limits Removed
Core i5-13600K
Core Ultra 9 285K/Stock
Ryzen 7 5800X3D
Core i9-12900K
Ryzen 9 5950X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Рендеринг: Cinebench
Cinebench – один из наиболее широко используемых бенчмарков для современных процессоров, популярность которого обусловлена тем, что он создан на основе рендера программного приложения Maxon Cinema 4D. И AMD, и Intel часто демонстрируют результаты этого теста на различных официальных мероприятиях, так что он уже практически стал стандартом в этой отрасли. С помощью Cinebench R2024 мы тестируем как однопоточную, так и многопоточную производительность.
Rendering
Cinebench 2024 Multi
Multi-Threaded-Higher is Better
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 9950X
Core i9-14900K
Core i9-13900K
Ryzen 9 7950X
Ryzen 9 7950X3D
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i7-14700K
Ryzen 9 9900X
Core i7-13700K
Ryzen 9 7900X
Core i9-12900K
Ryzen 9 5950X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 9 7900
Core i5-14600K
Core i5-13600K
Ryzen 7 9700X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 7 7800X3D
Ryzen 5 9600X
Ryzen 5 7600X
Ryzen 7 5800X3D
Core i5-13400F
Rendering
Cinebench 2024 Single
Single-Threaded - Higher is Better
Core Ultra 9 285K/Stock
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 9950X
Core Ultra 7 265K/Stock
Core Ultra 7 265K/Power Limits Removed
Core i9-14900K
Ryzen 9 9900X
Ryzen 7 9700X
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i9-13900K
Ryzen 5 9600X
Core i7-14700K
Core i7-13700K
Ryzen 9 7950X
Ryzen 9 7950X3D
Core i5-14600K
Ryzen 9 7900X
Core i9-12900K
Ryzen 7 7700X
Ryzen 9 7900
Ryzen 5 7600X
Core i5-13600K
Ryzen 7 7700
Ryzen 7 7800X3D
Core i5-13400F
Ryzen 9 5950X
Ryzen 7 5800X3D
Blender – одна из немногочисленных бесплатных программ для рендеринга профессионального уровня, которая к тому же имеет открытый исходный код. Уже один только этот факт цементирует сообщество поклонников этой программы и делает ее популярным бенчмарком, которым легко пользоваться. В качестве тестовой сцены для этого обзора мы выбрали "BMW 27" в версии Blender 4.0.2.
Rendering
Blender
Lower is Better
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 9950X
Ryzen 9 7950X
Ryzen 9 7950X3D
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-14900K
Core i9-13900K
Ryzen 9 9900X
Core i7-14700K
Ryzen 9 7900X
Core i7-13700K
Core Ultra 5 245K/Power Limits Removed
Core i9-12900K
Core Ultra 5 245K/Stock
Ryzen 9 5950X
Ryzen 9 7900
Core i5-14600K
Core i5-13600K
Ryzen 7 9700X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 7 7800X3D
Ryzen 5 9600X
Ryzen 7 5800X3D
Core i5-13400F
Ryzen 5 7600X
Рендеринг: Corona
Corona Renderer – это современный, дающий фотографическую реалистичность изображения рендер, который доступен в Autodesk 3ds Max и Cinema 4D. Он обеспечивает физически правдоподобные и предсказуемые визуальные эффекты благодаря применению алгоритмов расчета глобального освещения и текстур высокого качества. Corona не поддерживает рендеринг силами GPU, поэтому для пользователей этой программы производительность CPU имеет крайне важное значение. Вместо безнадежно устаревшего бенчмарка Corona Benchmark, который не поддерживает новые архитектуры, мы использовали намного более новую версию 11.
Rendering
Corona Renderer
Lower is Better
Ryzen 9 9950X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 7950X
Core i9-14900K
Ryzen 9 7950X3D
Core i9-13900K
Ryzen 9 9900X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i7-14700K
Ryzen 9 7900X
Core i7-13700K
Ryzen 9 5950X
Core i9-12900K
Ryzen 9 7900
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-14600K
Core i5-13600K
Ryzen 7 9700X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 7 7800X3D
Ryzen 5 9600X
Ryzen 5 7600X
Ryzen 7 5800X3D
Core i5-13400F
Рендеринг: KeyShot
Автономная программа для рендеринга KeyShot быстро и эффективно обрабатывает потоки данных, благодаря чему вы получаете реалистичные сцены с высоким качеством изображения при максимально коротком времени отрисовки кадра. Рейтрейсинг в реальном времени, многосредное фотонное проецирование (photon mapping), адаптивный сэмплинг текстур и поддержка динамического освещения обеспечивают картинку высокого качества, которая мгновенно обновляется даже в интерактивном режиме работы над сценой. Версия KeyShot 2023.3 оптимизирована как под CPU-, так и под GPU-рендеринг, но мы использовали только CPU-рендер, так как возможности GPU-рендера все еще ограничены.
Rendering
Keyshot 2024
Lower is Better
Ryzen 9 7950X
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 9950X
Core Ultra 9 285K/Stock
Core i9-14900K
Core i9-13900K
Ryzen 9 7950X3D
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 7900X
Core i7-14700K
Ryzen 9 9900X
Ryzen 9 7900
Core i7-13700K
Ryzen 9 5950X
Core i9-12900K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-14600K
Ryzen 7 9700X
Ryzen 7 7700X
Ryzen 7 7700
Core i5-13600K
Ryzen 7 7800X3D
Ryzen 5 9600X
Ryzen 7 5800X3D
Ryzen 5 7600X
Core i5-13400F
Рендеринг: V-Ray
V-Ray – популярная во всем мире программа для трехмерного рендеринга, в которой применяется глобальное освещение, полная трассировка лучей (path tracing), фотонное проецирование и карты освещенности, благодаря чему на выходе получается суперреалистичная объемная картинка. Приложение используется в игровой и телевизионной компьютерной графике. V-Ray совместим со всеми основными 3D-приложениями и отлично интегрируется в любой графический пайплайн. Здесь мы использовали встроенный бенчмарк V-Ray 6 в режиме "только CPU"; результат теста показывает количество "v-сэмплов", которое V-Ray может обработать на конкретном «железе» (чем больше – тем лучше, то есть выше качество картинки).
Rendering
V-Ray
Lower is Better
Ryzen 9 9950X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 7950X
Ryzen 9 7950X3D
Core i9-14900K
Ryzen 9 9900X
Core i9-13900K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i7-14700K
Ryzen 9 7900X
Core i7-13700K
Ryzen 9 7900
Ryzen 9 5950X
Core i9-12900K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 9700X
Core i5-14600K
Core i5-13600K
Ryzen 7 7700X
Ryzen 7 7800X3D
Ryzen 7 7700
Ryzen 5 9600X
Ryzen 5 7600X
Core i5-13400F
Ryzen 7 5800X3D
Разработка игр: Unreal Engine 5
Unreal Engine 5 – один из ведущих мультиплатформенных игровых движков. Помимо общей продвинутости, он также предлагает множество опций, позволяющих получить результат быстрее, чем при использовании аналогичных конкурирующих продуктов: время – деньги. В последнюю 5-ю версию добавили несколько новых функций, которые делают этот движок полезным не только для разработки игр, но и для кинопроизводства, архитектуры и беспилотного транспорта. Обычно релизу игры предшествует длительная работа под названием "смоделировать, состряпать и разлить по формочкам", что включает в себя оптимизацию различных ассетов, их компиляцию и упаковку в версии для конкретных платформ с последующей комплектацией в оптимизированные пакеты для дистрибуции. Для обзора мы выбрали сравнительно простую тестовую сцену – обычно этот процесс занимает несколько часов.
Game Development
Unreal Engine 5
Build, Cook & Release - Lower is Better
Ryzen 9 7950X3D
Ryzen 9 7950X
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 9950X
Core Ultra 9 285K/Stock
Core i9-14900K
Ryzen 9 9900X
Core i9-13900K
Core Ultra 7 265K/Power Limits Removed
Core i7-14700K
Ryzen 9 7900X
Core Ultra 7 265K/Stock
Ryzen 9 7900
Core i7-13700K
Ryzen 7 7800X3D
Core i5-14600K
Core i9-12900K
Core Ultra 5 245K/Power Limits Removed
Ryzen 7 9700X
Core i5-13600K
Core Ultra 5 245K/Stock
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 9 5950X
Ryzen 5 9600X
Ryzen 7 5800X3D
Ryzen 5 7600X
Core i5-13400F
Разработка программных приложений: управление исходным кодом в Git
Важнейшим атрибутом среды разработки программных приложений является система контроля версий (version control system, VCS), которая позволяет разработчикам отслеживать все изменения, регистрировать обновления, возвращаться к предыдущим версиям, сравнивать версии и вообще работать над коллективным проектом более эффективно. Распределенная система контроля версий Git, кроме того, позволяет каждому участнику иметь последнюю актуальную копию полной истории проекта, что облегчает работу в офлайне и совместную работу в целом. Хотя Git обычно работает быстро, некоторые задачи, такие как оптимизация репозитория и управление данными, могут представлять собой интенсивную вычислительную нагрузку. Например, оптимизация репозитория часто включает в себя очистку старых данных, сжатие хранилища файлов и проверку целостности репозитория. В нашем тесте измеряется время выполнения набора таких операций.
Software Development
Git Version Control System
Lower is Better
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 7950X
Core i9-14900K
Ryzen 9 7900X
Ryzen 9 7950X3D
Ryzen 7 7700X
Core i9-13900K
Ryzen 9 7900
Core Ultra 9 285K/Power Limits Removed
Ryzen 7 7700
Core Ultra 9 285K/Stock
Ryzen 5 7600X
Core i7-14700K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 7 7800X3D
Core i7-13700K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-14600K
Core i9-12900K
Core i5-13600K
Ryzen 9 5950X
Ryzen 7 5800X3D
Core i5-13400F
Разработка программных приложений: Visual Studio C++
Microsoft Visual C++ – вероятно, самый популярный язык программирования для создания профессиональных Windows-приложений. Он входит в пакет для разработчиков ПО Microsoft Visual Studio, который имеет солидную историю и получил широкое распространение как золотой стандарт интегрированной среды разработки (IDE). Компиляция программы – это достаточно долгий процесс, превращающий исходный программный код в исполняемый, и программисты обычно терпеть не могут ждать, пока этот процесс завершится. Мы пропустили через компилятор и линковщик C++ (версия Visual Studio 2022) приложение среднего размера, а также выполнили компиляцию ресурсов. Сборка приложения производилась в режиме "release" со всеми включенными оптимизациями и активной опцией мультипроцессорной компиляции.
Software Development
Microsoft Visual Studio, C++
Lower is Better
Ryzen 9 9950X
Ryzen 9 7950X
Ryzen 9 9900X
Ryzen 9 7950X3D
Core i9-14900K
Ryzen 9 7900X
Core i9-13900K
Core i7-14700K
Ryzen 7 9700X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 7900
Ryzen 7 7700X
Core i7-13700K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 7 7700
Ryzen 7 7800X3D
Ryzen 5 9600X
Core i5-14600K
Ryzen 5 7600X
Core i9-12900K
Core i5-13600K
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Ryzen 9 5950X
Ryzen 7 5800X3D
Core i5-13400F
Проверка файлов на наличие вирусов
Для надежной работы вашего компьютера необходима защита от вирусов и вредоносных программ. Антивирусное ПО выявляет нежелательные программы путем сравнения файлов с большой базой данных, охватывающей тысячи сигнатур и правил. В этом тесте мы измеряем время сканирования на наличие вирусов всех файлов 30-гигабайтной игры.
Antivirus
Avast
Lower is Better
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 7950X3D
Ryzen 7 9700X
Ryzen 9 7900
Ryzen 5 9600X
Ryzen 7 7800X3D
Core i9-14900K
Core i7-14700K
Core i9-13900K
Core i7-13700K
Core i5-14600K
Core i5-13600K
Core Ultra 9 285K/Power Limits Removed
Core i9-12900K
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 5950X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Ryzen 7 5800X3D
Разработка печатных плат: Altium Designer
Как минимум одна плата внутри вашего любимого электронного устройства разработана с помощью программы Altium Designer. Это самое популярное приложение для автоматизированного проектирования сложных печатных плат, выполняющее автоматическую трассировку и гарантирующее целостность сигнала и соответствие дорожек заданным правилам трассировки. В нашем тесте измеряется время, которое Altium PCB Designer затрачивает на загрузку проекта и выполнение в нем ряда операций, включая автотрассировку, проверку соответствия трассировки заданным правилам и выпуск полного комплекта документации для производства платы.
PCB Design
Altium Designer
Lower is Better
Core i9-14900K
Core i9-13900K
Ryzen 9 9950X
Core i7-14700K
Ryzen 9 9900X
Ryzen 7 9700X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 9 285K/Power Limits Removed
Core i7-13700K
Core Ultra 9 285K/Stock
Ryzen 5 9600X
Core i5-14600K
Ryzen 9 7950X
Ryzen 9 7900X
Core i9-12900K
Core i5-13600K
Ryzen 9 7950X3D
Ryzen 7 7700X
Ryzen 5 7600X
Core Ultra 5 245K/Power Limits Removed
Ryzen 9 7900
Core Ultra 5 245K/Stock
Ryzen 7 7700
Ryzen 7 7800X3D
Core i5-13400F
Ryzen 9 5950X
Ryzen 7 5800X3D
Оптическое распознавание текста: Google Tesseract
Оптическое распознавание текста (Optical Character Recognition, OCR) – это способ перевода текста из формата картинки (скана или фотографии) в актуальный текстовый формат, например, для последующего редактирования или архивирования. Хотя большинство программ для OCR являются однопоточными приложениями, движок Google Tesseract может работать сразу с несколькими страницами отсканированного документа, распределяя нагрузку между несколькими ядрами процессора. Эта программа, которую можно рассматривать в качестве одной из самых точных открытых программ для OCR, автоматически запускает проверку правописания в первичных результатах распознавания, что дополнительно усложняет вычислительную нагрузку.
Text Recognition
Google Tesseract OCR
Lower is Better
Ryzen 9 9950X
Ryzen 9 7950X
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 7900X
Ryzen 9 7950X3D
Core Ultra 9 285K/Stock
Ryzen 9 9900X
Ryzen 9 7900
Core i9-14900K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 5950X
Core i9-13900K
Core i7-14700K
Core i7-13700K
Core i9-12900K
Core i5-14600K
Ryzen 7 7700X
Ryzen 7 7700
Core i5-13600K
Ryzen 7 9700X
Ryzen 7 7800X3D
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 5 7600X
Ryzen 7 5800X3D
Ryzen 5 9600X
Core i5-13400F
Сжатие файлов: WinRar
Данные сжимаются почти всегда, когда они пересылаются через проводное соединение, поскольку это уменьшает передаваемый объем и время загрузки. Архиватор WinRAR использует более продвинутый алгоритм по сравнению с классическим ZIP, почему мы и выбрали его для этого теста. Кроме того, он масштабируется на несколько ядер процессора.
File Compression
WinRAR
Lower is Better
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 9 9950X
Ryzen 9 7950X
Core i7-13700K
Ryzen 9 7950X3D
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 9900X
Ryzen 9 7900X
Ryzen 7 9700X
Core i5-14600K
Ryzen 9 7900
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-12900K
Ryzen 7 7700X
Core i5-13600K
Ryzen 7 7800X3D
Ryzen 7 7700
Ryzen 9 5950X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 5 9600X
Ryzen 7 5800X3D
Core i5-13400F
Ryzen 5 7600X
Сжатие файлов: 7-Zip
Еще один популярный архиватор – 7-Zip, который включает в себя бенчмарк, измеряющий скорость выполнения целочисленных инструкций (в MIPS) при использовании алгоритма ZIP. Этот сценарий эффективно задействует несколько потоков, когда они доступны.
File Compression
7-Zip, Compress
Higher is Better
Ryzen 9 9950X
Ryzen 9 7950X3D
Ryzen 9 7950X
Core i9-14900K
Core i9-13900K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i7-14700K
Ryzen 9 9900X
Ryzen 9 7900X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i7-13700K
Ryzen 9 7900
Ryzen 9 5950X
Core i9-12900K
Core i5-14600K
Core i5-13600K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 9700X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 7 7800X3D
Ryzen 5 9600X
Ryzen 7 5800X3D
Ryzen 5 7600X
Core i5-13400F
File Compression
7-Zip, Decompress
Higher is Better
Ryzen 9 7950X
Ryzen 9 9950X
Ryzen 9 7950X3D
Core i9-14900K
Core i9-13900K
Ryzen 9 5950X
Ryzen 9 9900X
Ryzen 9 7900X
Core i7-14700K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 7900
Core i7-13700K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-12900K
Ryzen 7 7700X
Core i5-14600K
Ryzen 7 9700X
Ryzen 7 7700
Core i5-13600K
Ryzen 7 7800X3D
Ryzen 7 5800X3D
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 5 9600X
Ryzen 5 7600X
Core i5-13400F
Шифрование данных: AES
Шифрование – основа безопасных коммуникаций в интернете. Стандарт шифрования AES – один из самых популярных современных алгоритмов, что обусловлено его простотой и устойчивостью к кибератакам. В отличие от других алгоритмов шифрования, AES симметричен, то есть для шифрования и дешифровки используется один и тот же ключ. Возможность быстрого шифрования и дешифровки данных имеет важное значение, поэтому современные процессоры имеют специальный набор инструкций под названием "AES-NI" для ускорения этих операций.
File Compression
7-Zip, Compress
Higher is Better
Ryzen 9 7950X
Ryzen 9 7950X3D
Ryzen 9 9950X
Core i9-14900K
Core i9-13900K
Ryzen 9 7900X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i7-14700K
Ryzen 9 7900
Ryzen 9 9900X
Ryzen 9 5950X
Core i7-13700K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-12900K
Ryzen 7 7700X
Core i5-14600K
Ryzen 7 7700
Core i5-13600K
Ryzen 7 7800X3D
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 9700X
Ryzen 5 7600X
Core i5-13400F
Ryzen 7 5800X3D
Ryzen 5 9600X
Шифрование данных: SHA-3
Технически SHA – это не шифрование, а хеширование. Криптографическая хеш-функция представляет собой математический алгоритм, который создает уникальное выходное значение (хеш) для определенного набора данных на входе. Эта функция работает только в одном направлении, обратить ее практически невозможно. Еще одно требование к хорошему алгоритму хеширования – он не должен создавать коллизий, то есть должен исключать возможность совпадения хешей для разных входных наборов данных: обычно для этого к входному набору каждый раз добавляется случайное уникальное сообщение, обеспечивающее уникальность хеша. Алгоритм SHA-3 удовлетворяет всем этим требованиям и часто используется для идентификации передаваемых данных, которые могут быть также предварительно зашифрованы с помощью AES.
File Compression
7-Zip, Compress
Higher is Better
Ryzen 9 7950X
Ryzen 9 7950X3D
Ryzen 9 9950X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-14900K
Core i9-13900K
Ryzen 9 7900X
Ryzen 9 9900X
Ryzen 9 7900
Core i7-14700K
Core i7-13700K
Ryzen 9 5950X
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i9-12900K
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 7 9700X
Ryzen 7 7800X3D
Core i5-14600K
Core i5-13600K
Ryzen 5 7600X
Ryzen 5 9600X
Ryzen 7 5800X3D
Core i5-13400F
Игровое тестирование: 720p
После нескольких последних обзоров CPU по просьбам читателей мы включили в игровое тестирование разрешение 720p (1280x720 пикселей). Все игровые тесты для процессоров проводятся на разрешении 720p с настройками Ultra и с видеокартой RTX 4090. Это низкое разрешение показывает теоретическую производительность процессора, поскольку игры на нем исключительно процессорозависимы. Конечно, никто не будет покупать компьютер с RTX 4090, чтобы играть на 720p, но эти результаты имеют академическое значение, так как процессор, который не способен обеспечить 144 fps на разрешении 720p, тем более никогда не дойдет до этой отметки на более высоких разрешениях. Так что эти цифры могут представлять интерес для сборщиков игровых ПК, рассчитанных на высокочастотные мониторы. Наши игровые тесты на разрешении 720p можно рассматривать как аналог синтетических бенчмарков (потому что на 720p уже давно никто не играет), хотя сами тестовые сцены взяты из реальных современных игр класса 3А.
Relative Performance
Games 1280x720
RTX 4090, Ultra - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Ryzen 9 7950X3D
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 9 9950X
Ryzen 7 9700X
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 9900X
Core Ultra 9 285K/Stock
Ryzen 5 9600X
Ryzen 9 7950X
Core i5-14600K
Ryzen 7 7700X
Ryzen 9 7900X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 7 7700
Ryzen 5 7600X
Core i5-13600K
Core Ultra 5 245K/Power Limits Removed
Core i9-12900K
Ryzen 9 7900
Core Ultra 5 245K/Stock
Ryzen 7 5800X3D
Ryzen 5 7600
Core i7-12700K
Core i7-12600K
Ryzen 9 5950X
Ryzen 9 5900X
Core i7-11900K
Core i5-13400F
Core i7-11700KF
Ryzen 7 5800X
Core i5-12400F
Ryzen 5 5600X
Ryzen 7 5700X
Core i5-11600K
Ryzen 5 8500G
Core i3-14100
Ryzen 7 5700G
Core i3-12100F
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Average FPS
1280x720
Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core i9-14900K
Core i9-13900K
Ryzen 9 9950X
Core i7-14700K
Ryzen 7 9700X
Core i7-13700K
Ryzen 9 9900X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 5 9600X
Ryzen 7 7700X
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 7 7700
Core i5-14600K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 5 7600X
Ryzen 7 5800X3D
Ryzen 9 7900
Ryzen 5 7600
Core i5-13600K
Core Ultra 5 245K/Power Limits Removed
Core i9-12900K
Core Ultra 5 245K/Stock
Core i7-12700K
Ryzen 9 5950X
Ryzen 9 5900X
Core i5-12600K
Ryzen 7 5800X
Core i9-11900K
Ryzen 7 5700X
Ryzen 5 5600X
Core i7-11700KF
Core i5-13400F
Core i5-12400F
Core i5-11600K
Ryzen 5 8500G
Core i3-14100
Ryzen 7 5700G
Core i3-12100F
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Alan Wake 2
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Ryzen 7 9700X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 5 9600X
Ryzen 9 9900X
Core i7-14700K
Core i7-13700K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 9950X
Ryzen 7 7700X
Core i5-14600K
Ryzen 9 7900X
Ryzen 7 7700
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 9 7950X3D
Ryzen 9 7950X
Ryzen 5 7600X
Ryzen 9 7900
Core i5-13600K
Core i9-12900K
Ryzen 7 5800X3D
Ryzen 9 5950X
Core i5-13400F
Baldur’s Gate3
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 7 5800X3D
Core i5-14600K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 7950X
Ryzen 9 7900X
Core i5-13600K
Ryzen 9 9900X
Core i9-12900K
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 9950X
Core Ultra 7 265K/Stock
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 7900
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 5950X
Core i5-13400F
Counter-Strike 2
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 7 7700X
Ryzen 7 7700
Core i9-14900K
Core i9-13900K
Ryzen 5 7600X
Ryzen 7 5800X3D
Ryzen 9 7950X
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 7900X
Core i7-14700K
Core Ultra 9 285K/Stock
Ryzen 5 9600X
Core i7-13700K
Ryzen 9 7900
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i5-14600K
Ryzen 9 5950X
Core i5-13600K
Core i9-12900K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Cyberpunk 2077
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Ryzen 9 9950X
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 9 7950X
Core i9-14900K
Ryzen 9 9900X
Core i9-13900K
Ryzen 5 7600X
Ryzen 9 7900X
Core i7-14700K
Core i7-13700K
Core i5-14600K
Ryzen 9 7900
Ryzen 7 5800X3D
Core i5-13600K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i9-12900K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 9 5950X
Core i5-13400F
Elden Ring
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Ryzen 9 7950X3D
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 7 5800X3D
Ryzen 5 9600X
Ryzen 9 9900X
Ryzen 7 7700X
Ryzen 9 9950X
Ryzen 7 9700X
Ryzen 7 7700
Core i5-14600K
Ryzen 9 7900
Ryzen 5 7600X
Core i5-13600K
Core i9-12900K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 9 5950X
Core i5-13400F
Hogwarts Legacy
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 7 9700X
Core i7-13700K
Ryzen 9 7950X3D
Ryzen 9 9900X
Ryzen 9 9950X
Ryzen 5 9600X
Core i5-14600K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 7900X
Ryzen 7 7700X
Core i5-13600K
Ryzen 9 7950X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 5 7600X
Core i9-12900K
Ryzen 7 5800X3D
Ryzen 7 7700
Ryzen 9 7900
Ryzen 9 5950X
Core i5-13400F
Remnant II
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Ryzen 7 9700X
Core i7-14700K
Core i7-13700K
Ryzen 9 9950X
Ryzen 9 9900X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 5 9600X
Core i5-14600K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 7950X3D
Ryzen 9 7900X
Core i5-13600K
Core Ultra 5 245K/Power Limits Removed
Ryzen 7 7700X
Core Ultra 5 245K/Stock
Ryzen 9 7950X
Core i9-12900K
Ryzen 5 7600X
Ryzen 7 7700
Ryzen 9 7900
Ryzen 7 5800X3D
Core i5-13400F
Ryzen 9 5950X
Spider-Man Remastered
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Core i9-14900K
Core i9-13900K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 7 7800X3D
Core i7-14700K
Core i7-13700K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-14600K
Ryzen 9 9950X
Ryzen 9 7950X
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 7950X3D
Ryzen 5 7600X
Core i9-12900K
Ryzen 7 7700X
Ryzen 9 9900X
Ryzen 7 7700
Ryzen 9 7900X
Core i5-13600K
Ryzen 9 7900
Ryzen 7 5800X3D
Ryzen 9 5950X
Core i5-13400F
Starfield
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core i9-14900K
Core i9-13900K
Ryzen 5 9600X
Core i7-14700K
Core i7-13700K
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 9 7900X
Core i5-14600K
Ryzen 9 7950X
Core i9-12900K
Ryzen 7 7700X
Core Ultra 9 285K/Power Limits Removed
Core i5-13600K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
Ryzen 7 7700
Ryzen 9 7900
Ryzen 5 7600X
Ryzen 7 5800X3D
Core i5-13400F
Ryzen 9 5950X
The Last of Us
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Core i9-14900K
Core i9-13900K
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core Ultra 9 285K/Power Limits Removed
Core i7-14700K
Core Ultra 9 285K/Stock
Core i7-13700K
Ryzen 9 9950X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 7950X
Ryzen 7 9700X
Core Ultra 5 245K/Power Limits Removed
Ryzen 7 7700X
Core Ultra 5 245K/Stock
Ryzen 9 7900X
Ryzen 9 9900X
Core i5-14600K
Ryzen 9 9900X
Ryzen 5 9600X
Core i9-12900K
Ryzen 9 7900
Core i5-13600K
Ryzen 5 7600X
Ryzen 9 5950X
Ryzen 7 5800X3D
Core i5-13400F
720p с рейтрейсингом
Alan Wake 2 + RT
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 9900X
Core i7-13700K
Core i5-14600K
Ryzen 9 9950X
Ryzen 7 7700X
Ryzen 9 7900X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 7 7700
Core i5-13600K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 7950X3D
Core i9-12900K
Ryzen 9 7950X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 9 7900
Ryzen 5 7600X
Ryzen 7 5800X3D
Ryzen 9 5950X
Core i5-13400F
Cyberpunk 2077 + RT
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 7 7800X3D
Ryzen 7 9700X
Ryzen 9 9950X
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 7 5800X3D
Ryzen 9 7950X
Ryzen 9 9900X
Core i5-14600K
Ryzen 5 9600X
Ryzen 7 7700X
Ryzen 7 7700
Core i5-13600K
Ryzen 9 7900X
Core i9-12900K
Ryzen 9 7900
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 5 7600X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 9 5950X
Core i5-13400F
Elden Ring + RT
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 9 7950X
Ryzen 7 7700X
Core i9-14900K
Core i7-14700K
Core i9-13900K
Ryzen 7 7700
Ryzen 7 5800X3D
Core i7-13700K
Ryzen 9 7900X
Ryzen 5 7600X
Ryzen 9 7900
Core i9-12900K
Core i5-14600K
Core i5-13600K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 5950X
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Spider-Man Remastered + RT
1280x720
TPU Custom Scene, Average FPS - Higher is Better
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i9-14900K
Core Ultra 7 265K/Power Limits Removed
Core i9-13900K
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 7800X3D
Core i7-14700K
Core i7-13700K
Core i5-14600K
Ryzen 9 9950X
Ryzen 9 7950X3D
Ryzen 9 9900X
Ryzen 9 7950X
Core i9-12900K
Ryzen 5 9600X
Ryzen 7 9700X
Core i5-13600K
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 9 7900
Ryzen 5 7600X
Ryzen 7 5800X3D
Ryzen 9 5950X
Core i5-13400F
Игровое тестирование: 1080p
Relative Performance
Games 1920x1080
RTX 4090, Ultra - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Ryzen 9 7950X3D
Core i7-14700K
Core i7-13700K
Ryzen 9 9950X
Ryzen 7 9700X
Ryzen 5 9600X
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 9900X
Core Ultra 9 285K/Stock
Ryzen 9 7950X
Core i5-14600K
Ryzen 7 7700X
Ryzen 9 7900X
Ryzen 7 7700
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 5 7600X
Core i5-13600K
Ryzen 9 7900
Core i9-12900K
Ryzen 7 5800X3D
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 5 7600
Core i7-12700K
Ryzen 9 5950X
Core i5-12600K
Ryzen 9 5900X
Core i5-13400F
Core i9-11900K
Ryzen 7 5800X
Core i5-12400F
Core i7-11700KF
Ryzen 7 5700X
Ryzen 5 5600X
Core i5-11600K
Core i3-14100
Ryzen 5 8500G
Core i3-12100F
Ryzen 7 5700G
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Average FPS
1920x1080
Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Ryzen 9 7950X3D
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 9 9950X
Ryzen 7 9700X
Ryzen 9 9900X
Ryzen 5 9600X
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 7950X
Core Ultra 9 285K/Stock
Ryzen 7 7700X
Ryzen 9 7900X
Ryzen 7 7700
Ryzen 5 7600X
Core i5-14600K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 7 5800X3D
Ryzen 9 7900
Ryzen 5 7600
Core i5-13600K
Core i9-12900K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i7-12700K
Ryzen 9 5950X
Ryzen 9 5900X
Core i5-12600K
Ryzen 7 5800X
Ryzen 7 5700X
Ryzen 5 5600X
Core i9-11900K
Core i5-13400F
Core i7-11700KF
Core i5-12400F
Core i5-11600K
Ryzen 5 8500G
Core i3-14100
Ryzen 7 5700G
Core i3-12100F
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Alan Wake 2
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Core i9-14900K
Core i7-14700K
Ryzen 7 7700X
Ryzen 9 9950X
Core i9-13900K
Ryzen 9 7900X
Core i7-13700K
Ryzen 7 7700
Ryzen 9 7950X
Ryzen 5 7600X
Core i9-12900K
Core i5-14600K
Ryzen 9 7950X3D
Ryzen 9 7900
Core i5-13600K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 5800X3D
Ryzen 9 5950X
Core i5-13400F
Baldur’s Gate 3
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 7 5800X3D
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i5-14600K
Ryzen 9 9950X
Ryzen 9 7950X
Core i5-13600K
Ryzen 9 9900X
Core i9-12900K
Ryzen 9 7900X
Core Ultra 7 265K/Power Limits Removed
Ryzen 7 9700X
Core Ultra 7 265K/Stock
Ryzen 9 7900
Ryzen 5 9600X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 7700
Ryzen 7 7700X
Ryzen 5 7600X
Ryzen 9 5950X
Core i5-13400F
Counter-Strike 2
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 7 7800X3D
Core i9-14900K
Ryzen 9 9950X
Ryzen 9 9900X
Core i9-13900K
Ryzen 7 5800X3D
Core i7-14700K
Ryzen 9 7950X
Ryzen 7 7700X
Ryzen 5 7600X
Ryzen 7 7700
Core i7-13700K
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 7900X
Ryzen 9 7900
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i5-13600K
Core i5-14600K
Ryzen 9 5950X
Core i9-12900K
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i5-13400F
Cyberpunk 2077
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 9950X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 9 9900X
Core i9-14900K
Core i9-13900K
Ryzen 5 7600X
Ryzen 9 7950X
Core i7-14700K
Core i7-13700K
Ryzen 9 7900X
Core i5-14600K
Ryzen 9 7900
Ryzen 7 5800X3D
Core i5-13600K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core i9-12900K
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
Ryzen 9 5950X
Core i5-13400F
Elden Ring
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Ryzen 9 7950X3D
Core i7-14700K
Core i7-13700K
Ryzen 9 7900X
Ryzen 9 7950X
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 7 5800X3D
Ryzen 7 7700X
Core i5-14600K
Ryzen 7 7700
Core i5-13600K
Ryzen 5 7600X
Ryzen 9 7900
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i9-12900K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 5950X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Hogwarts Legacy
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 9 7900X
Ryzen 9 9900X
Ryzen 7 9700X
Core i7-13700K
Ryzen 5 9600X
Core i9-12900K
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 7950X3D
Ryzen 9 7950X
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core i5-14600K
Core Ultra 7 265K/Stock
Ryzen 9 9950X
Core Ultra 5 245K/Power Limits Removed
Ryzen 7 7700X
Core Ultra 5 245K/Stock
Core i5-13600K
Ryzen 7 7700
Ryzen 9 7900
Ryzen 5 7600X
Ryzen 7 5800X3D
Core i5-13400F
Ryzen 9 5950X
Remnant II
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 9900X
Core i7-13700K
Ryzen 9 9950X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core i5-14600K
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 9 7900X
Core i5-13600K
Ryzen 9 7950X3D
Ryzen 7 7700X
Core i9-12900K
Ryzen 5 7600X
Ryzen 9 7950X
Ryzen 7 7700
Ryzen 9 7900
Ryzen 7 5800X3D
Core i5-13400F
Ryzen 9 5950X
Spider-Man Remastered
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Core i9-14900K
Core i9-13900K
Core Ultra 9 285K/Power Limits Removed
Core i7-14700K
Core i7-13700K
Core Ultra 9 285K/Stock
Ryzen 7 7800X3D
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-14600K
Ryzen 7 9700X
Core i9-12900K
Ryzen 9 7950X
Ryzen 9 9950X
Core i5-13600K
Ryzen 5 9600X
Ryzen 9 7950X3D
Ryzen 9 9900X
Ryzen 7 7700X
Ryzen 5 7600X
Ryzen 9 7900X
Ryzen 7 7700
Ryzen 9 7900
Ryzen 7 5800X3D
Ryzen 9 5950X
Core i5-13400F
Starfield
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 9 7950X3D
Ryzen 7 7700
Ryzen 9 7950X
Ryzen 5 7600X
Ryzen 9 9950X
Ryzen 9 7900
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i7-13700K
Core i9-12900K
Core i5-14600K
Ryzen 7 9700X
Ryzen 5 9600X
Core i5-13600K
Ryzen 9 9900X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
Core i5-13400F
Ryzen 7 5800X3D
Ryzen 9 5950X
The Last of Us
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core i9-14900K
Ryzen 9 9950X
Core i9-13900K
Ryzen 7 9700X
Core i7-14700K
Ryzen 9 7950X
Core Ultra 9 285K/Power Limits Removed
Ryzen 7 7700X
Ryzen 9 7900X
Core Ultra 9 285K/Stock
Ryzen 9 9900X
Core Ultra 7 265K/Power Limits Removed
Core i7-13700K
Ryzen 7 7700
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Ryzen 5 9600X
Core Ultra 5 245K/Stock
Core i5-14600K
Ryzen 9 7900
Core i9-12900K
Core i5-13600K
Ryzen 5 7600X
Ryzen 9 5950X
Ryzen 7 5800X3D
Core i5-13400F
1080p с рейтрейсингом
Alan Wake 2 + RT
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 9950X
Ryzen 9 7950X3D
Ryzen 7 7800X3D
Core i9-14900K
Ryzen 9 7900X
Core i7-14700K
Ryzen 7 7700X
Core i9-13900K
Ryzen 9 7950X
Ryzen 9 7900
Ryzen 5 7600X
Core i9-12900K
Ryzen 7 7700
Core i7-13700K
Core i5-14600K
Core i5-13600K
Ryzen 9 5950X
Ryzen 7 5800X3D
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Cyberpunk 2077 + RT
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Ryzen 7 9700X
Ryzen 9 9950X
Core i7-14700K
Core i7-13700K
Ryzen 9 7950X
Ryzen 7 5800X3D
Ryzen 9 9900X
Ryzen 5 9600X
Core i5-14600K
Ryzen 7 7700X
Ryzen 7 7700
Core i5-13600K
Ryzen 9 7900X
Core i9-12900K
Ryzen 9 7900
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 5 7600X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 9 5950X
Core i5-13400F
Elden Ring + RT
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 9700X
Ryzen 9 9950X
Ryzen 5 9600X
Ryzen 9 7950X3D
Ryzen 9 9900X
Ryzen 9 7950X
Ryzen 7 7800X3D
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 9 7900
Ryzen 7 5800X3D
Ryzen 5 7600X
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core Ultra 9 285K/Power Limits Removed
Core i7-13700K
Core i5-14600K
Core i9-12900K
Core Ultra 9 285K/Stock
Core i5-13600K
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 5950X
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Spider-Man Remastered + RT
1920x1080
TPU Custom Scene, Average FPS - Higher is Better
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i9-14900K
Core i9-13900K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 7800X3D
Core i7-14700K
Core i7-13700K
Core i5-14600K
Ryzen 5 9600X
Ryzen 9 7950X3D
Ryzen 9 9950X
Ryzen 9 7950X
Ryzen 9 9900X
Ryzen 7 9700X
Core i5-13600K
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 7 7700
Core i9-12900K
Ryzen 5 7600X
Ryzen 9 7900
Ryzen 7 5800X3D
Core i5-13400F
Ryzen 9 5950X
Игровое тестирование: 1440p
Relative Performance
Games 2560x1440
RTX 4090, Ultra - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 9 7950X3D
Core i7-13700K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 7950X
Ryzen 5 9600X
Core i5-14600K
Ryzen 9 9950X
Ryzen 9 9900X
Core Ultra 7 265K/Stock
Ryzen 7 9700X
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 7 5800X3D
Core Ultra 5 245K/Power Limits Removed
Core i5-13600K
Core i9-12900K
Core Ultra 5 245K/Stock
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 7900
Core i7-12700K
Ryzen 5 7600X
Ryzen 9 5950X
Core i5-12600K
Ryzen 9 5900X
Core i5-13400F
Core i9-11900K
Ryzen 7 5800X
Core i5-12400F
Ryzen 7 5700X
Ryzen 5 5600X
Core i7-11700KF
Core i5-11600K
Core i3-14100
Ryzen 5 8500G
Core i3-12100F
Ryzen 7 5700G
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Average FPS
2560x1440
Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 9 7950X3D
Core i7-13700K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 7950X
Core Ultra 7 265K/Stock
Core i5-14600K
Ryzen 5 9600X
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 7 5800X3D
Core i5-13600K
Core Ultra 5 245K/Power Limits Removed
Core i9-12900K
Core Ultra 5 245K/Stock
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 7900
Ryzen 5 7600
Core i7-12700K
Ryzen 9 5950X
Ryzen 9 5900X
Core i5-12600K
Ryzen 7 5800X
Ryzen 7 5700X
Ryzen 5 5600X
Core i5-13400F
Core i9-11900K
Core i7-11700KF
Core i5-12400F
Core i5-11600K
Ryzen 5 8500G
Core i3-14100
Ryzen 7 5700G
Core i3-12100F
Ryzen 9 3900X
Ryzen 7 3700X
Ryzen 5 3600
Core i5-11400F
Ryzen 3 3300X
Ryzen 7 2700X
Alan Wake 2
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 9900X
Ryzen 9 7950X3D
Ryzen 9 9950X
Ryzen 7 9700X
Ryzen 7 7800X3D
Ryzen 5 9600X
Core i9-14900K
Ryzen 9 7900X
Core i9-13900K
Core i9-12900K
Ryzen 9 7950X
Ryzen 7 7700X
Core i7-14700K
Ryzen 9 7900
Ryzen 7 7700
Core i7-13700K
Ryzen 5 7600X
Ryzen 7 5800X3D
Ryzen 9 5950X
Core i5-14600K
Core i5-13600K
Core i5-13400F
Core Ultra 9 285K/Power Limits Removed
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
Baldur’s Gate 3
2560x1440
Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core i9-14900K
Core i9-13900K
Ryzen 7 5800X3D
Core i7-14700K
Core i7-13700K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i5-14600K
Ryzen 9 7950X
Ryzen 9 7900X
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 9900X
Core Ultra 7 265K/Stock
Ryzen 9 9950X
Ryzen 7 9700X
Core i5-13600K
Ryzen 5 9600X
Core i9-12900K
Ryzen 9 7900
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 5950X
Core i5-13400F
Counter-Strike 2
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 7 7800X3D
Core i9-14900K
Ryzen 9 7950X
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 9 9900X
Ryzen 7 5800X3D
Core i5-14600K
Ryzen 7 7700X
Ryzen 9 9950X
Ryzen 9 7900X
Ryzen 9 7900
Ryzen 7 9700X
Core Ultra 9 285K/Power Limits Removed
Core i5-13600K
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 5 9600X
Ryzen 5 7600X
Ryzen 7 7700
Core i9-12900K
Ryzen 9 5950X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Cyberpunk 2077
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7700X
Ryzen 9 7950X3D
Ryzen 9 7900X
Core i9-14900K
Core i9-13900K
Ryzen 7 7700
Core i7-14700K
Core Ultra 9 285K/Power Limits Removed
Core i7-13700K
Ryzen 7 7800X3D
Core Ultra 9 285K/Stock
Core i5-13600K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core i5-14600K
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
Ryzen 9 9950X
Ryzen 9 7950X
Ryzen 9 9900X
Ryzen 5 7600X
Core i9-12900K
Ryzen 7 5800X3D
Ryzen 9 7900
Ryzen 5 9600X
Ryzen 7 9700X
Ryzen 9 5950X
Core i5-13400F
Elden Ring
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 9 7950X3D
Core i7-13700K
Ryzen 5 9600X
Ryzen 7 9700X
Ryzen 9 7900X
Ryzen 9 7950X
Core i5-14600K
Ryzen 7 5800X3D
Ryzen 7 7700X
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 7900
Core i5-13600K
Core Ultra 9 285K/Power Limits Removed
Core i9-12900K
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 5950X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Hogwarts Legacy
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Core i9-14900K
Core i9-13900K
Ryzen 9 7900X
Ryzen 9 7950X3D
Ryzen 9 7950X
Ryzen 7 7800X3D
Ryzen 9 7900
Ryzen 7 9700X
Ryzen 7 7700X
Core Ultra 9 285K/Power Limits Removed
Core i7-14700K
Ryzen 5 9600X
Core Ultra 9 285K/Stock
Ryzen 9 9900X
Core Ultra 5 245K/Power Limits Removed
Ryzen 9 9950X
Core Ultra 5 245K/Stock
Core Ultra 7 265K/Power Limits Removed
Core i7-13700K
Core Ultra 7 265K/Stock
Core i9-12900K
Ryzen 5 7600X
Ryzen 7 7700
Ryzen 7 5800X3D
Core i5-14600K
Core i5-13600K
Core i5-13400F
Ryzen 9 5950X
Remnant II
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 9900X
Ryzen 5 9600X
Ryzen 9 9950X
Ryzen 7 7800X3D
Ryzen 7 9700X
Ryzen 7 7700X
Ryzen 9 7950X3D
Core i9-14900K
Core i7-14700K
Core i9-13900K
Ryzen 9 7900
Core i7-13700K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Ryzen 9 7950X
Ryzen 5 7600X
Core Ultra 5 245K/Stock
Ryzen 9 7900X
Ryzen 7 7700
Core i5-14600K
Ryzen 7 5800X3D
Core i9-12900K
Core i5-13600K
Core i5-13400F
Ryzen 9 5950X
Spider-Man Remastered
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i7-13700K
Core i5-14600K
Core i5-13600K
Ryzen 5 9600X
Core i9-12900K
Ryzen 9 7950X
Ryzen 7 9700X
Ryzen 9 7950X3D
Ryzen 7 7700X
Ryzen 5 7600X
Ryzen 9 9950X
Ryzen 9 7900X
Ryzen 7 7700
Ryzen 9 9900X
Ryzen 7 5800X3D
Ryzen 9 7900
Ryzen 9 5950X
Core i5-13400F
Starfield
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 5950X
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 7 5800X3D
Core i9-14900K
Core i9-13900K
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 7950X
Ryzen 9 7900
Ryzen 5 7600X
Ryzen 7 7700
Core i7-14700K
Core i7-13700K
Core i9-12900K
Core i5-14600K
Core i5-13600K
Core i5-13400F
Core Ultra 9 285K/Power Limits Removed
Core Ultra 7 265K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
The Last of Us
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 7 7700X
Ryzen 9 7900X
Ryzen 9 7950X3D
Ryzen 7 5800X3D
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 9 7950X
Ryzen 7 9700X
Ryzen 7 7700
Core i9-14900K
Ryzen 5 9600X
Ryzen 5 7600X
Ryzen 9 5950X
Core i7-14700K
Core i9-13900K
Core i7-13700K
Core i5-14600K
Core i9-12900K
Core Ultra 9 285K/Power Limits Removed
Core i5-13600K
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 7900
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i5-13400F
Core Ultra 9 285K/Stock
Core Ultra 5 245K/Stock
1440p с рейтрейсингом
Alan Wake 2 + RT
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 7 7800X3D
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 7 9950X
Ryzen 5 9600X
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 9 7900
Ryzen 9 7950X
Core i9-14900K
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 5950X
Core i7-14700K
Core i9-13900K
Core i7-13700K
Core i9-12900K
Ryzen 7 5800X3D
Core i5-14600K
Core i5-13600K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Stock
Core Ultra 9 285K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Cyberpunk 2077 + RT
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Core i9-14900K
Ryzen 7 7800X3D
Ryzen 9 9900X
Ryzen 5 9600X
Core i9-13900K
Ryzen 9 9950X
Core i7-14700K
Core i7-13700K
Ryzen 7 9700X
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 9 7900
Ryzen 7 7700X
Core i5-14600K
Core i9-12900K
Ryzen 7 7700
Core i5-13600K
Ryzen 7 5800X3D
Ryzen 5 7600X
Ryzen 9 5950X
Core i5-13400F
Core Ultra 9 285K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
Elden Ring + RT
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 9700X
Ryzen 7 9950X
Ryzen 9 7950X3D
Ryzen 5 9600X
Ryzen 9 9900X
Ryzen 9 7950X
Ryzen 7 7700X
Ryzen 7 7800X3D
Ryzen 7 5800X3D
Ryzen 9 7900X
Ryzen 9 7900
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 5950X
Core i9-14900K
Core Ultra 9 285K/Power Limits Removed
Core i7-14700K
Core i9-13900K
Core Ultra 9 285K/Stock
Core i7-13700K
Core i9-12900K
Core Ultra 7 265K/Power Limits Removed
Core i5-14600K
Core i5-13600K
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i5-13400F
Spider-Man Remastered + RT
2560x1440
TPU Custom Scene, Average FPS - Higher is Better
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i9-14900K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i9-13900K
Core Ultra 5 245K/Stock
Ryzen 7 7800X3D
Core i7-14700K
Core i7-13700K
Core i5-14600K
Ryzen 9 7950X3D
Ryzen 5 9600X
Ryzen 9 7950X
Ryzen 9 9950X
Ryzen 9 9900X
Core i9-12900K
Core i5-13600K
Ryzen 9 7900X
Ryzen 7 9700X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 7900
Ryzen 7 5800X3D
Core i5-13400F
Ryzen 9 5950X
Игровое тестирование: 4K
Relative Performance
Games 3840x2160
RTX 4090, Ultra - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 9 9950X
Ryzen 9 7950X
Ryzen 9 9900X
Ryzen 5 9600X
Ryzen 9 7900X
Ryzen 7 5800X3D
Core Ultra 9 285K/Power Limits Removed
Ryzen 7 7700X
Core i5-14600K
Core Ultra 9 285K/Stock
Ryzen 7 9700X
Core Ultra 7 265K/Power Limits Removed
Core i9-12900K
Ryzen 9 7900
Ryzen 7 7700
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i5-13600K
Core Ultra 5 245K/Stock
Ryzen 5 7600X
Core i7-12700K
Ryzen 5 7600
Ryzen 9 5950X
Ryzen 9 5900X
Core i5-12600K
Core i5-13400F
Ryzen 7 5800X
Ryzen 5 5600X
Ryzen 7 5700X
Core i5-12400F
Core i9-11900K
Core i3-14100
Core i7-11700KF
Core i5-11600K
Ryzen 9 3900X
Core i3-12100F
Ryzen 7 5700G
Ryzen 7 3700X
Ryzen 5 8500G
Ryzen 5 3600
Ryzen 3 3300X
Core i5-11400F
Ryzen 7 2700X
Average FPS
3840x2160
Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i7-13700K
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 7950X
Ryzen 9 9950X
Core Ultra 9 285K/Stock
Ryzen 9 9900X
Ryzen 9 7900X
Ryzen 7 5800X3D
Core Ultra 7 265K/Power Limits Removed
Core i5-14600K
Ryzen 5 9600X
Ryzen 7 7700X
Core Ultra 7 265K/Stock
Core i9-12900K
Ryzen 7 9700X
Core Ultra 5 245K/Power Limits Removed
Core i5-13600K
Ryzen 9 7900
Core Ultra 5 245K/Stock
Ryzen 7 7700
Core i7-12700K
Ryzen 5 7600X
Ryzen 5 7600
Ryzen 9 5950X
Core i5-12600K
Ryzen 9 5900X
Core i5-13400F
Ryzen 7 5800X
Ryzen 5 5600X
Core i5-12400F
Ryzen 7 5700X
Core i9-11900K
Core i3-14100
Core i7-11700KF
Core i5-11600K
Ryzen 9 3900X
Core i3-12100F
Ryzen 7 5700G
Ryzen 5 8500G
Ryzen 7 3700X
Ryzen 5 3600
Core i5-11400F
Ryzen 3 3300X
Ryzen 7 2700X
Alan Wake 2
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 9 7900X
Ryzen 7 7800X3D
Ryzen 7 7700X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 9 9950X
Ryzen 5 9600X
Ryzen 9 7950X
Ryzen 9 7900
Ryzen 7 7700
Core i9-14900K
Ryzen 9 5950X
Ryzen 7 5800X3D
Core i9-13900K
Core i7-14700K
Core i5-14600K
Core i7-13700K
Core i9-12900K
Core i5-13600K
Ryzen 5 7600X
Core i5-13400F
Core Ultra 7 265K/Power Limits Removed
Core Ultra 9 285K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 9 285K/Stock
Core Ultra 5 245K/Stock
Baldur’s Gate 3
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 7 5800X3D
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i5-14600K
Ryzen 9 7900X
Ryzen 9 9900X
Ryzen 9 7950X
Ryzen 9 9950X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 7 9700X
Core i5-13600K
Ryzen 5 9600X
Ryzen 9 7900
Core i9-12900K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 5950X
Core i5-13400F
Counter-Strike 2
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 9 7950X
Ryzen 7 7700X
Core i9-14900K
Ryzen 7 7800X3D
Ryzen 7 5800X3D
Core Ultra 9 285K/Power Limits Removed
Core Ultra 7 265K/Power Limits Removed
Core i7-14700K
Core i9-13900K
Ryzen 9 5950X
Core i7-13700K
Core Ultra 9 285K/Stock
Core i9-12900K
Ryzen 9 7900X
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i5-14600K
Core Ultra 5 245K/Stock
Core i5-13600K
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 9 7900
Ryzen 7 7700
Ryzen 7 9700X
Core i5-13400F
Ryzen 5 9600X
Ryzen 5 7600X
Cyberpunk 2077
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 7 7700X
Core i9-14900K
Core i9-13900K
Ryzen 9 7950X3D
Core Ultra 9 285K/Power Limits Removed
Core i7-14700K
Ryzen 9 7900X
Ryzen 7 5800X3D
Core Ultra 9 285K/Stock
Ryzen 9 7900
Ryzen 9 5950X
Core i7-13700K
Ryzen 5 9600X
Ryzen 7 7700
Ryzen 5 7600X
Core i9-12900K
Ryzen 9 9900X
Ryzen 9 9950X
Ryzen 9 7950X
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i5-14600K
Core Ultra 7 265K/Power Limits Removed
Core i5-13600K
Core Ultra 7 265K/Stock
Core i5-13400F
Ryzen 7 9700X
Elden Ring
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Ryzen 9 7950X
Ryzen 7 7700X
Ryzen 7 5800X3D
Ryzen 7 7700
Ryzen 9 9900X
Ryzen 9 7900X
Ryzen 5 7600X
Ryzen 9 9950X
Ryzen 5 9600X
Ryzen 9 7900
Ryzen 7 9700X
Ryzen 9 5950X
Core i9-14900K
Core i9-13900K
Core i7-13700K
Core i7-14700K
Core i9-12900K
Core i5-14600K
Core i5-13600K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 9 285K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 5 245K/Stock
Core i5-13400F
Hogwarts Legacy
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Core i9-14900K
Core i7-14700K
Core i9-13900K
Ryzen 9 9950X
Core Ultra 9 285K/Power Limits Removed
Core i5-14600K
Ryzen 9 9900X
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 7 7800X3D
Core Ultra 9 285K/Stock
Ryzen 9 7900
Ryzen 7 7700X
Core i7-13700K
Core i5-13600K
Ryzen 7 9700X
Ryzen 5 7600X
Ryzen 7 5800X3D
Core Ultra 7 265K/Power Limits Removed
Core i9-12900K
Ryzen 5 9600X
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Ryzen 7 7700
Core Ultra 5 245K/Stock
Ryzen 9 5950X
Core i5-13400F
Remnant II
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 7700X
Ryzen 7 5800X3D
Ryzen 9 7950X
Ryzen 9 7900
Ryzen 9 5950X
Ryzen 9 7950X3D
Ryzen 7 7700
Core i9-14900K
Ryzen 5 9600X
Ryzen 9 7900X
Core i7-14700K
Core i9-13900K
Ryzen 7 9700X
Core Ultra 9 285K/Power Limits Removed
Core i5-14600K
Core i7-13700K
Core i5-13600K
Core i9-12900K
Ryzen 5 7600X
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i5-13400F
Spider-Man Remastered
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 7950X3D
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core i9-14900K
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-13900K
Core i7-14700K
Core i7-13700K
Core i5-14600K
Core i9-12900K
Ryzen 9 9950X
Ryzen 5 9600X
Ryzen 7 7700X
Core i5-13600K
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 7900
Ryzen 7 5800X3D
Ryzen 9 5950X
Core i5-13400F
Remnant II
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 7700X
Ryzen 7 5800X3D
Ryzen 9 7950X
Ryzen 9 7900
Ryzen 9 5950X
Ryzen 9 7950X3D
Ryzen 7 7700
Core i9-14900K
Ryzen 5 9600X
Ryzen 9 7900X
Core i7-14700K
Core i9-13900K
Ryzen 7 9700X
Core Ultra 9 285K/Power Limits Removed
Core i5-14600K
Core i7-13700K
Core i5-13600K
Core i9-12900K
Ryzen 5 7600X
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i5-13400F
Spider-Man Remastered
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 7950X3D
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core i9-14900K
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-13900K
Core i7-14700K
Core i7-13700K
Core i5-14600K
Core i9-12900K
Ryzen 9 9950X
Ryzen 5 9600X
Ryzen 7 7700X
Core i5-13600K
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 7900
Ryzen 7 5800X3D
Ryzen 9 5950X
Core i5-13400F
Starfield
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Ryzen 9 7900X
Core i9-14900K
Core i9-13900K
Ryzen 9 7900
Ryzen 7 7700X
Core i7-14700K
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Core i7-13700K
Ryzen 9 7950X
Ryzen 7 7700
Ryzen 7 5800X3D
Core i5-14600K
Core i9-12900K
Ryzen 9 5950X
Ryzen 5 7600X
Core i5-13600K
Core i5-13400F
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
The Last of Us
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 7 7800X3D
Ryzen 9 9950X
Ryzen 7 9700X
Ryzen 5 7600X
Ryzen 5 9600X
Ryzen 7 7700X
Ryzen 7 5800X3D
Ryzen 9 9900X
Ryzen 9 7950X
Core i9-14900K
Ryzen 9 7900X
Ryzen 7 7700
Ryzen 9 5950X
Core i9-13900K
Core i7-14700K
Core i7-13700K
Core i5-14600K
Core i9-12900K
Ryzen 9 7900
Core i5-13600K
Core i5-13400F
Core Ultra 5 245K/Power Limits Removed
Core Ultra 7 265K/Power Limits Removed
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
4K с рейтрейсингом
Alan Wake 2 + RT
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 7 7800X3D
Ryzen 7 7700X
Ryzen 9 7950X3D
Ryzen 9 7900X
Ryzen 7 7700
Ryzen 9 5950X
Ryzen 9 7950X
Ryzen 9 7900
Ryzen 7 5800X3D
Core i9-14900K
Ryzen 5 7600X
Core i7-14700K
Core i9-13900K
Core i7-13700K
Core i5-13600K
Core Ultra 5 245K/Power Limits Removed
Core i5-14600K
Core i9-12900K
Core Ultra 7 265K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Stock
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i5-13400F
Cyberpunk 2077 + RT
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 9 7950X
Ryzen 7 7800X3D
Ryzen 7 7700X
Ryzen 9 9900X
Ryzen 5 9600X
Ryzen 9 7900X
Ryzen 9 7900
Ryzen 5 7600X
Ryzen 7 5800X3D
Ryzen 9 9950X
Ryzen 7 9700X
Ryzen 7 7700
Ryzen 9 5950X
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i5-14600K
Core i7-13700K
Core i5-13600K
Core i9-12900K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i5-13400F
Elden Ring + RT
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 9 7950X3D
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 7 9700X
Ryzen 5 9600X
Ryzen 9 7950X
Ryzen 7 7800X3D
Ryzen 7 5800X3D
Ryzen 9 7900
Ryzen 7 7700X
Ryzen 9 5950X
Ryzen 9 7900X
Ryzen 7 7700
Ryzen 5 7600X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i9-14900K
Core i7-14700K
Core i9-13900K
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core i7-13700K
Core i9-12900K
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
Core i5-14600K
Core i5-13600K
Core i5-13400F
Spider-Man Remastered + RT
3840x2160
TPU Custom Scene, Average FPS - Higher is Better
Ryzen 7 7800X3D
Core Ultra 9 285K/Power Limits Removed
Core Ultra 7 265K/Power Limits Removed
Core Ultra 5 245K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Stock
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 9 7950X
Ryzen 9 9900X
Ryzen 5 9600X
Ryzen 9 7950X3D
Core i5-14600K
Core i9-12900K
Ryzen 9 9950X
Ryzen 9 7900X
Core i5-13600K
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 7 5800X3D
Ryzen 7 9700X
Ryzen 9 7900
Core i5-13400F
Ryzen 9 5950X
Минимальная частота кадров
Хотя средняя частота кадров является основным информативным показателем, который позволяет оценить игровой опыт в целом, минимальная частота кадров говорит нам о том, что мы получим в условиях наименьшего благоприятствования, например, в сценах динамичных битв и других высоконагруженных эпизодах. Все результаты, приводимые в этом разделе, соответствуют 99-му перцентилю (1% Low). По определению эти результаты базируются на меньшей выборке данных для каждого бенчмарка, поэтому они менее «надежные» или «точные», чем средние показатели FPS. То есть в конкретном геймплее вы c большей вероятностью можете получить отклонения от этих цифр (в ту или в другую сторону).
Minimum FPS
1920x1080/All Games Average
1% Low FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Ryzen 9 7950X3D
Core i7-13700K
Core i7-14700K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 7950X
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 7900X
Core Ultra 7 265K/Stock
Ryzen 9 9950X
Ryzen 7 7700X
Ryzen 7 7700
Ryzen 7 9700Х
Ryzen 9 9900X
Core i5-14600K
Ryzen 5 9600X
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 5 7600X
Ryzen 9 7900
Core i9-12900K
Core i5-13600K
Ryzen 5 7600
Ryzen 7 5800X3D
Core i7-12700K
Ryzen 9 5950X
Core i5-12600K
Ryzen 9 5900X
Core i9-11900K
Core i5-13400F
Core i7-11700KF
Ryzen 7 5800X
Core i5-12400F
Ryzen 5 5600X
Ryzen 7 5700X
Core i5-11600K
Core i3-14100
Ryzen 5 8500G
Ryzen 7 5700G
Core i3-12100F
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Minimum FPS
3840x2160/All Games Average
1% Low FPS - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Ryzen 9 7950X3D
Core i7-14700K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i7-13700K
Ryzen 9 7950X
Ryzen 9 7900X
Ryzen 7 7700X
Ryzen 7 7700
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 9950X
Core i5-14600K
Core i9-12900K
Ryzen 5 7600
Ryzen 7 5800X3D
Ryzen 9 7900
Ryzen 5 7600X
Core i5-13600K
Ryzen 5 9600X
Ryzen 9 9900X
Core i7-12700K
Ryzen 7 9700X
Ryzen 9 5950X
Ryzen 9 5900X
Core i5-12600K
Ryzen 7 5800X
Core i5-13400F
Core i9-11900K
Ryzen 5 5600X
Core i7-11700KF
Ryzen 7 5700X
Core i3-14100
Core i5-12400F
Core i5-11600K
Ryzen 9 3900X
Ryzen 7 3700X
Ryzen 5 8500G
Ryzen 7 5700G
Core i3-12100F
Ryzen 5 3600
Core i5-11400F
Ryzen 3 3300X
Ryzen 7 2700X
Производительность встроенной графики
В поколении процессоров Core Ultra "Arrow Lake-S" Intel значительно модернизировала встроенную графику. Компоненты iGPU распределены между плитками Graphics и SoC. Плитка Graphics, которая базируется на техпроцессе EUV 5 нм, содержит пайплайн графического рендеринга и вычислительные компоненты, располагающиеся в ядрах Xe, в то время как плитка SoC содержит медиа- и дисплейный движки и дисплейные интерфейсы I/O. iGPU чипов Arrow Lake-S базируется на графической архитектуре Xe-LPG, которую Intel впервые представила в серии Meteor Lake. Это следующий шаг вперед после Xe-LP, на которой базируется iGPU в Raptor Lake, и здесь вводится полная поддержка функционала DirectX 12 Ultimate, включая рейтрейсинг в реальном времени.
Ядра Xe в Xe-LPG содержат блоки рейтрейсинга и аппаратное обеспечение сетчатых шейдеров и обратной связи с сэмплером – еще двух ключевых технологий DirectX 12 Ultimate; однако от архитектуры Xe-HPG, на которой базируются дискретные игровые видеокарты Arc серии A, Xe-LPG отличает отсутствие ускорителей матричных вычислений XMX. Но этот графический процессор все-таки поддерживает ускорение ИИ за счет инструкций DP4a, так что апскейлер XeSS будет работать, задействуя те же ресурсы, которые он задействует на видеокартах других брендов.
Плитка Graphics в Arrow Lake-S содержит четыре ядра Xe, в которых имеется 64 исполнительных блока (EU) или 512 унифицированных шейдеров. Грядущие процессоры Arrow Lake-H для массовых ноутбуков будут содержать плитку Graphics большего размера на базе архитектуры Xe-HPG, что подразумевает наличие блоков XMX. Также там будет восемь ядер Xe, то есть 1024 унифицированных шейдера.
В этом разделе приведены результаты тестирования игр с минимальными настройками детализации (поэтому их нельзя сравнивать с результатами игрового тестирования с дискретной видеокартой RTX 4090, где были установлены максимальные настройки).
Разрешение 720p
Relative Performance
1280x720
Higher is Better
RX 6400
GTX 1060
GTX 1630
Ryzen 5 8500G/iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 7 5700G/ iGPU
Ryzen 5 7600/ iGPU
Ryzen 9 9950X/ iGPU
Core i9-14900K/ iGPU
Average FPS
1280x720/ Lowest Settings
Higher is Better
GTX 1060
RX 6400
GTX 1630
Ryzen 5 8500G/iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 7 5700G/ iGPU
Ryzen 5 7600/ iGPU
Ryzen 9 9950X/ iGPU
Core i9-14900K/ iGPU
Разрешение 1080p Full HD
Relative Performance
1920x1080
Higher is Better
RX 6400
GTX 1060
GTX 1630
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 5 8500G/iGPU
Ryzen 7 5700G/ iGPU
Ryzen 9 9950X/ iGPU
Core i9-14900K/ iGPU
Ryzen 5 7600/ iGPU
Average FPS
1280x720/ Lowest Settings
Higher is Better
GTX 1060
RX 6400
GTX 1630
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 5 8500G/iGPU
Ryzen 7 5700G/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
Результаты в отдельных играх
Alan Wake 2
1280x720/Lowest Settings
Average FPS - Higher is Better
RX 6400
Ryzen 5 8500G/iGPU
GTX 1630
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
GTX 1060
Core Ultra 5 245K/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
Ryzen 7 5700G/ iGPU
Alan Wake 2
1920x1080/ Lowest Settings
Higher is Better
RX 6400
GTX 1630
Ryzen 5 8500G/iGPU
GTX 1060
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 9 9950X/ iGPU
Core i9-14900K/ iGPU
Ryzen 5 7600/ iGPU
Ryzen 7 5700G/ iGPU
Baldur’s Gate 3
1280x720/Lowest Settings
Average FPS - Higher is Better
GTX 1060
RX 6400
GTX 1630
Ryzen 5 8500G/iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 7 5700G/ iGPU
Core i9-14900K/ iGPU
Ryzen 5 7600/ iGPU
Ryzen 9 9950X/ iGPU
Baldur’s Gate 3
1920x1080/ Lowest Settings
Higher is Better
GTX 1060
RX 6400
GTX 1630
Ryzen 5 8500G/iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 7 5700G/ iGPU
Core i9-14900K/ iGPU
Ryzen 5 7600/ iGPU
Ryzen 9 9950X/ iGPU
Cyberpunk 2077
1280x720/Lowest Settings
Average FPS - Higher is Better
GTX 1060
RX 6400
GTX 1630
Ryzen 5 8500G/iGPU
Core Ultra 9 285K/iGPU
Ryzen 7 5700G/ iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
Cyberpunk 2077
1920x1080/ Lowest Settings
Higher is Better
GTX 1060
RX 6400
GTX 1630
Ryzen 5 8500G/iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 7 5700G/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
Counter-Strike 2
1280x720/Lowest Settings
Average FPS - Higher is Better
GTX 1060
RX 6400
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
GTX 1630
Ryzen 7 5700G/ iGPU
Ryzen 5 8500G/iGPU
Ryzen 5 7600/ iGPU
Ryzen 9 9950X/ iGPU
Core i9-14900K/ iGPU
Counter-Strike 2
1920x1080/ Lowest Settings
Average FPS-Higher is Better
GTX 1060
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
RX 6400
Core Ultra 5 245K/ iGPU
GTX 1630
Ryzen 5 8500G/iGPU
Ryzen 7 5700G/ iGPU
Ryzen 5 7600/ iGPU
Ryzen 9 9950X/ iGPU
Core i9-14900K/ iGPU
Elden Ring
1280x720/Lowest Settings
Average FPS - Higher is Better
GTX 1060
Ryzen 5 8500G/iGPU
RX 6400
GTX 1630
Ryzen 7 5700G/ iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 5 7600/ iGPU
Ryzen 9 9950X/ iGPU
Core i9-14900K/ iGPU
Elden Ring
1920x1080/ Lowest Settings
Average FPS-Higher is Better
GTX 1060
RX 6400
GTX 1630
Ryzen 5 8500G/iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 7 5700G/ iGPU
Core i9-14900K/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Hogwarts Legacy
1280x720/Lowest Settings
Average FPS - Higher is Better
RX 6400
GTX 1060
GTX 1630
Ryzen 7 5700G/ iGPU
Ryzen 5 8500G/iGPU
Ryzen 5 7600/ iGPU
Ryzen 9 9950X/ iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Core i9-14900K/ iGPU
Hogwarts Legacy
1920x1080/ Lowest Settings
Average FPS-Higher is Better
GTX 1060
RX 6400
GTX 1630
Ryzen 7 5700G/ iGPU
Ryzen 5 8500G/iGPU
Ryzen 5 7600/ iGPU
Ryzen 9 9950X/ iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Core i9-14900K/ iGPU
Remnant II
1280x720/Lowest Settings
Average FPS - Higher is Better
RX 6400
GTX 1060
GTX 1630
Ryzen 5 8500G/iGPU
Ryzen 7 5700G/ iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
Remnant II
1920x1080/ Lowest Settings
Average FPS-Higher is Better
RX 6400
GTX 1060
GTX 1630
Ryzen 5 8500G/iGPU
Core Ultra 9 285K/iGPU
Ryzen 7 5700G/ iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
Spider-Man Remastered
1280x720/Lowest Settings
Average FPS - Higher is Better
GTX 1060
RX 6400
GTX 1630
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 5 8500G/iGPU
Ryzen 7 5700G/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
Ryzen 9 9950X/ iGPU
Spider-Man Remastered
1920x1080/ Lowest Settings
Average FPS-Higher is Better
GTX 1060
RX 6400
GTX 1630
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 5 8500G/iGPU
Ryzen 7 5700G/ iGPU
Core i9-14900K/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Starfield
1280x720/Lowest Settings
Average FPS - Higher is Better
RX 6400
GTX 1060
GTX 1630
Ryzen 7 5700G/ iGPU
Ryzen 5 8500G/iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
Starfield
1920x1080/ Lowest Settings
Average FPS-Higher is Better
RX 6400
GTX 1060
GTX 1630
Ryzen 5 8500G/iGPU
Ryzen 7 5700G/ iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
The Last of Us
1280x720/Lowest Settings
Average FPS - Higher is Better
GTX 1060
RX 6400
GTX 1630
Ryzen 7 5700G/ iGPU
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 5 8500G/iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Core i9-14900K/ iGPU
The Last of Us
1920x1080/ Lowest Settings
Average FPS-Higher is Better
RX 6400
GTX 1060
GTX 1630
Core Ultra 9 285K/iGPU
Core Ultra 7 265K/ iGPU
Core Ultra 5 245K/ iGPU
Ryzen 7 5700G/ iGPU
Ryzen 5 8500G/iGPU
Core i9-14900K/ iGPU
Ryzen 9 9950X/ iGPU
Ryzen 5 7600/ iGPU
Энергопотребление процессора в приложениях
Все энергетические измерения в этом разделе производились путем физического измерения напряжения, тока и мощности на 8-пиновом коннекторе (коннекторах) питания процессора EPS, то есть результаты показывают энергопотребление только CPU, а не всей системы. Мы не использовали здесь встроенные программные датчики процессора, поскольку они могут давать неточные результаты, к тому же у разных производителей эти датчики отличаются. Все измерения производились с частотой 30 замеров в секунду и обрабатывались на отдельной машине, так что процесс измерений никак не влиял на тестируемую систему. Наш новый измерительный конвейер позволяет снимать показания синхронно с выполнением тестовых сценариев, так что мы легко смогли построить приведенную ниже диаграмму.
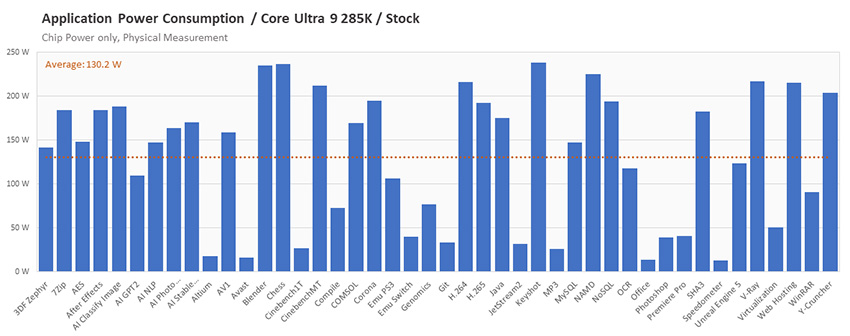
Power Consumption
Single-Threaded
MP3 Encode, CPU-Only - Lower is Better
Ryzen 7 7800X3D
Core i5-13400F
Core Ultra 5 245K/Stock
Ryzen 7 7700
Core Ultra 7 265K/Stock
Ryzen 7 9700Х
Core i5-14600K
Ryzen 7 5800X3D
Ryzen 5 9600X
Ryzen 7 7700X
Core i5-13600K
Ryzen 5 7600X
Core i7-13700K
Core Ultra 9 285K/Stock
Ryzen 9 7900X
Core i9-12900K
Core i9-13900K
Core i7-14700K
Ryzen 9 9950X
Core i9-14900K
Ryzen 9 9900X
Ryzen 9 7950X3D
Ryzen 9 5950X
Ryzen 9 7900
Ryzen 9 7950X
Power Consumption
Multi -Threaded
Blender, CPU-Only - Lower is Better
Core i5-13400F
Ryzen 7 7800X3D
Ryzen 9 7900
Ryzen 7 7700
Ryzen 5 9600X
Ryzen 7 9700Х
Ryzen 7 5800X3D
Ryzen 5 7600X
Ryzen 9 5950X
Core Ultra 5 245K/Stock
Ryzen 7 7700X
Core i5-13600K
Core i5-14600K
Ryzen 9 7950X3D
Core Ultra 7 265K/Stock
Ryzen 9 9900X
Ryzen 9 7900X
Core i7-13700K
Ryzen 9 9950X
Core i7-14700K
Core Ultra 9 285K/Stock
Core i9-12900K
Ryzen 9 7950X
Core i9-13900K
Core i9-14900K
Power Consumption
Applications (47 Tests Average)
CPU-Only - Lower is Better
Core i5-13400F
Ryzen 7 7800X3D
Ryzen 7 7700
Ryzen 9 7900
Ryzen 5 9600X
Ryzen 7 9700Х
Ryzen 7 5800X3D
Ryzen 5 7600X
Core Ultra 5 245K/Stock
Ryzen 7 7700X
Ryzen 9 7950X3D
Core i5-14600K
Core i5-13600K
Ryzen 9 5950X
Core Ultra 7 265K/Stock
Ryzen 9 9900X
Ryzen 9 7900X
Core i7-13700K
Core i9-12900K
Core Ultra 9 285K/Stock
Ryzen 9 9950X
Core i7-14700K
Ryzen 9 7950X
Core i9-13900K
Core i9-14900K
Энергопотребление процессора в играх
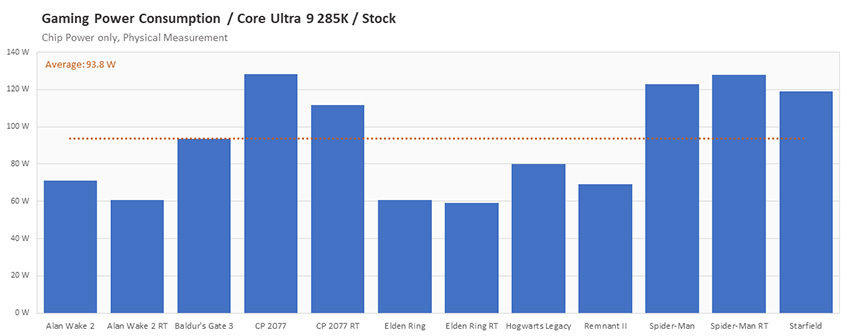
Power Consumption
Gaming (13 Test Average)
CPU-Only - Lower is Better
Ryzen 7 7800X3D
Core i5-13400F
Ryzen 7 5800X3D
Ryzen 7 7700
Core Ultra 5 245K/Stock
Ryzen 5 9600X
Ryzen 5 7600X
Ryzen 9 7950X3D
Ryzen 7 7700X
Ryzen 7 9700Х
Ryzen 9 7900
Core i5-14600K
Core Ultra 7 265K/Stock
Core i5-13600K
Core Ultra 9 285K/Stock
Core i9-12900K
Ryzen 9 9900X
Core i7-13700K
Ryzen 9 9950X
Ryzen 9 7900X
Ryzen 9 5950X
Ryzen 9 7950X
Core i7-14700K
Core i9-13900K
Core i9-14900K
Энергопотребление системы в простое
Энергопотребление в простое также важно с точки зрения оценки энергетической эффективности ПК. Оно показывает, какую мощность потребляет включенный компьютер без активной нагрузки, что для многих компьютеров является довольно частым состоянием. В отличие от предыдущих измерений, которые относились только к CPU, эти данные получены в результате электрических измерений на том конце провода, который подключается к стенной розетке (сеть переменного тока 220 В). Тестовые системные конфигурации ПК были описаны в соответствующем разделе (содержат один SSD и одну дискретную видеокарту).
Power Consumption
Idle
Whole System - Lower is Better
Core Ultra 5 245K/Stock
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Core i9-12900K
Core i5-13400F
Core i5-13600K
Core i7-13700K
Core i9-13900K
Core i5-14600K
Core i9-14900K
Core Ultra 5 245K/Power Limits Removed
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core i7-14700K
Ryzen 7 5800X3D
Ryzen 9 5950X
Ryzen 5 9600X
Ryzen 7 9700X
Ryzen 9 9950X
Ryzen 7 7700
Ryzen 9 9900X
Ryzen 5 7600X
Ryzen 7 7700X
Ryzen 7 7800X3D
Ryzen 9 7900
Ryzen 9 7950X
Ryzen 9 7950X3D
Ryzen 9 7900X
Энергетическая эффективность процессора
Просто значения потребляемой мощности не дают нам полную картину «энергетической ценности» процессора. Важно не только какую мощность потребляет процессор, но и насколько быстро он при этом выполняет задачу – оба эти показателя учитывает понятие "энергетическая эффективность". Так как более быстрый процессор завершает поставленную задачу быстрее, общее количество использованной энергии у него может оказаться меньше, чем у менее мощного процессора с меньшим номиналом TDP, который будет работать над этой же задачей дольше. Здесь для расчета энергетической эффективности мы разделили производительность в определенном сценарии (в данном случае это Cinebench, однопоточный и многопоточный тесты) на потребляемую в этом же сценарии мощность, получив в результате количество баллов на ватт потребляемой мощности. Для аналогичной оценки энергетической эффективности в гейминге (с GeForce RTX 4090) мы разделили среднеигровую частоту кадров на среднеигровую потребляемую мощность, получив, соответственно, количество кадров в секунду на ватт. Все эти результаты рассчитаны на основе измерений энергопотребления только CPU, а не всей системы.
Single-Threaded Efficiency
Points per Watt, CineBench 1T
Higher is Better
Core i5-13400F
Ryzen 7 7800X3D
Core Ultra 5 245K/Stock
Ryzen 7 7700
Ryzen 7 9700Х
Ryzen 5 9600X
Core i5-14600K
Core Ultra 7 265K/Stock
Ryzen 5 7600X
Core i5-13600K
Core i7-13700K
Ryzen 7 7700X
Core Ultra 9 285K/Stock
Ryzen 7 5800X3D
Core i9-12900K
Ryzen 9 7900X
Core i7-14700K
Core i9-13900K
Core i9-14900K
Ryzen 9 9950X
Ryzen 9 9900X
Ryzen 9 7950X3D
Ryzen 9 7900X
Ryzen 9 7950X
Ryzen 9 5950X
Multi-Threaded Efficiency
Points per Watt, CineBench nT
Higher is Better
Ryzen 9 7900
Ryzen 9 7950X3D
Ryzen 7 7800X3D
Ryzen 7 9700Х
Ryzen 7 7700
Core i5-13400F
Ryzen 9 5950X
Ryzen 5 9600X
Core Ultra 5 245K/Stock
Ryzen 9 9900X
Core Ultra 7 265K/Stock
Ryzen 9 9950X
Core Ultra 9 285K/Stock
Ryzen 7 5800X3D
Core i5-14600K
Core i5-13600K
Ryzen 9 7900X
Ryzen 9 7950X
Ryzen 7 7700X
Core i7-14700K
Core i9-14900K
Ryzen 5 7600X
Core i7-13700K
Core i9-13900K
Core i9-12900K
Gaming Efficiency
Frames per Watt, 14 Games, 1080p
Higher is Better
Ryzen 7 7800X3D
Core i5-13400F
Ryzen 7 5800X3D
Ryzen 7 7700
Core Ultra 5 245K/Stock
Ryzen 5 9600X
Ryzen 9 7950X3D
Ryzen 5 7600X
Ryzen 7 7700X
Ryzen 7 9700Х
Core Ultra 7 265K/Stock
Core i5-14600K
Ryzen 9 7900
Core i5-13600K
Core Ultra 9 285K/Stock
Core i7-13700K
Ryzen 9 9900X
Core i9-12900K
Ryzen 9 9950X
Ryzen 9 7900X
Core i7-14700K
Ryzen 9 7950X
Ryzen 9 5950X
Core i9-13900K
Core i9-14900K
Сравнение энергопотребления процессоров
Intel Core Ultra 9 285K vs. Core i9-14900K
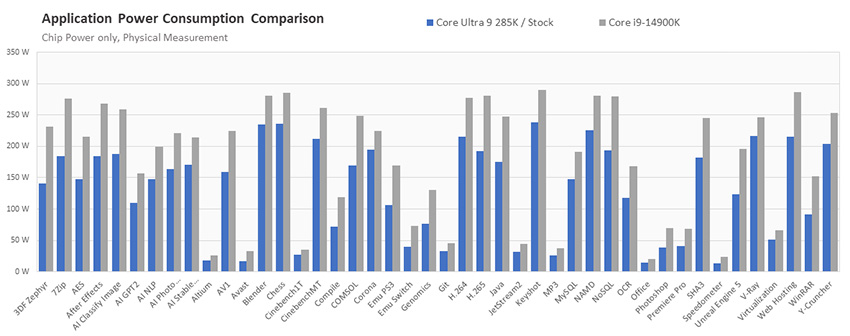
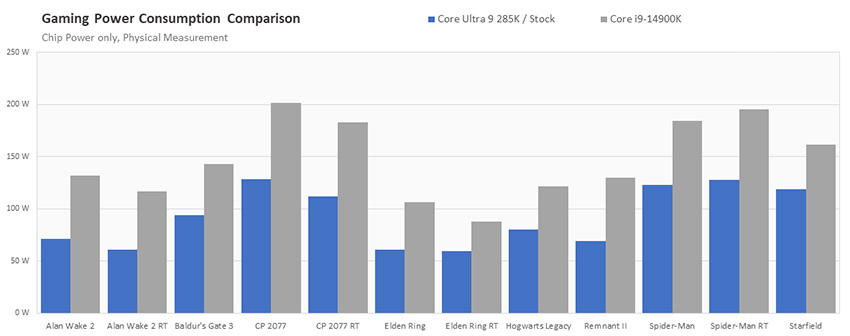
Intel Core Ultra 9 285K vs. Ryzen 9 9950X
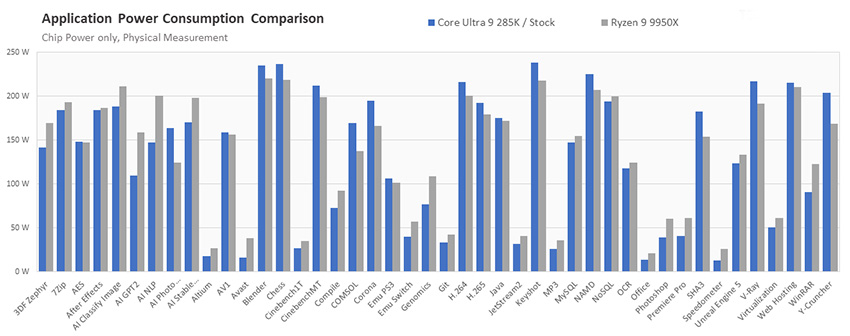
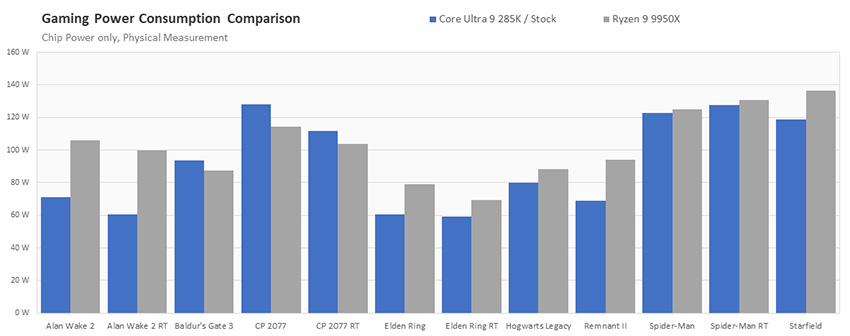
Intel Core Ultra 9 285K vs. Ryzen 9 9900X
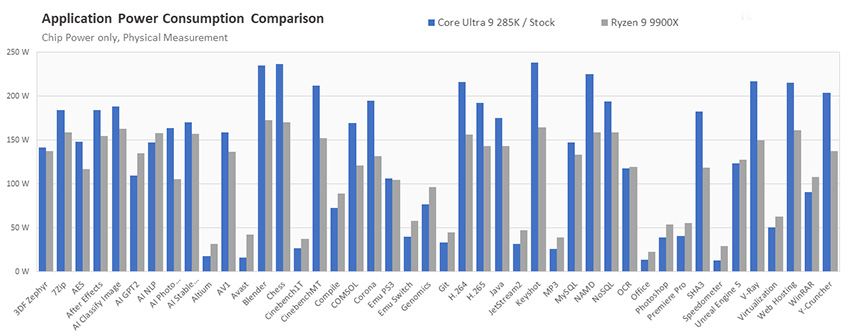
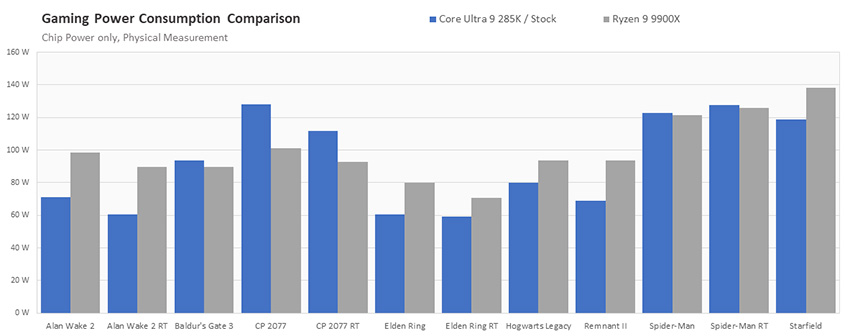
Intel Core Ultra 9 285K vs. Ryzen 9 7950X3D
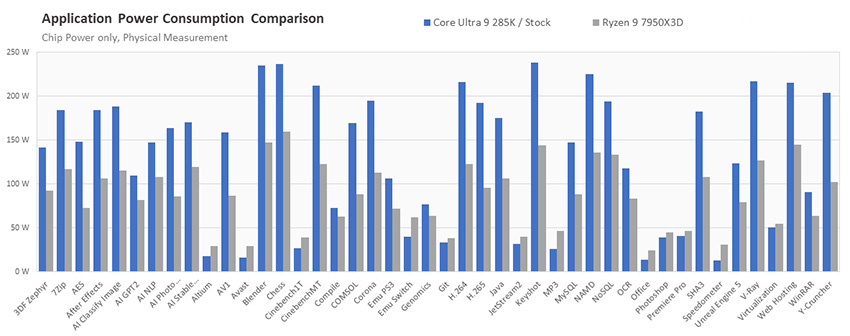
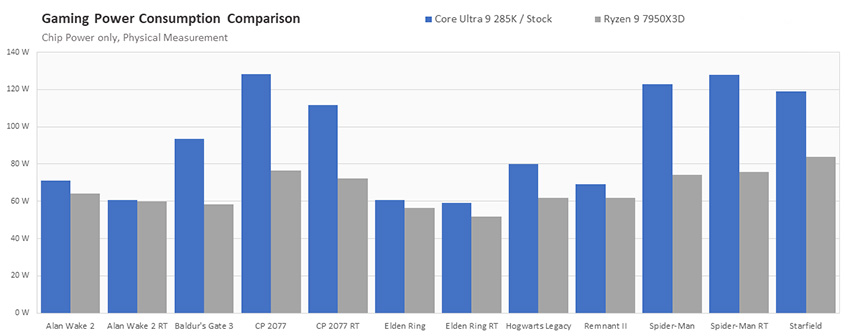
Intel Core Ultra 9 285K vs. Ryzen 9 7800X3D
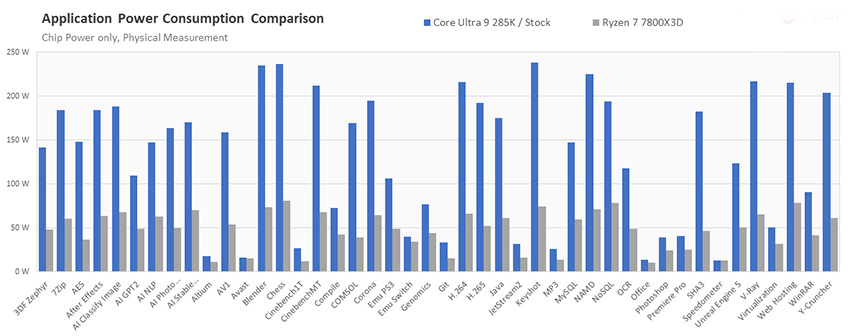
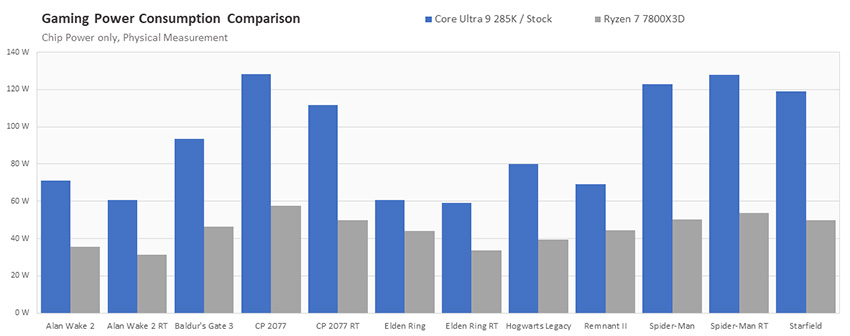
Производительность NPU

Как уже упоминалось, Intel Core Ultra 200 Arrow Lake – первое семейство настольных процессоров Intel с блоком NPU, который предназначен для более эффективного ИИ-процессинга и обеспечивает значительное ускорение сценариев машинного обучения без лишних энергетических затрат. Вклад NPU в энергетическую эффективность заключается в снятии специфических ИИ-нагрузок с CPU и GPU и выполнении их на более приспособленных для этого аппаратных компонентах. Основная задача здесь – повышение не столько скорости вычислений, сколько энергетической эффективности. Нейропроцессор NPU 3 в Arrow Lake имеет номинальную мощность 13 TOPS, что не много, но достаточно для локального запуска многих приложений с ИИ. В настоящее время пользовательский опыт применения ИИ базируется в основном на облачных ресурсах, что чревато увеличением задержки и снижением уровня конфиденциальности. Производители компьютерного «железа» надеются, что в будущем ИИ-приложений, доступных для запуска на локальных ПК, будет больше, и поэтому вводят в архитектуру клиентских процессоров специализированные блоки для аппаратного ускорения ИИ.
В качестве бенчмарков мы взяли быстрые тесты Geekbench AI, в которых сравнили производительность iGPU, CPU и NPU пары новых процессоров.
GeekBench AI
Single Precision
Higher is Better
Ultra 9 285K/ NPU
Ultra 9 285K/ iGPU
Ultra 9 285K/ CPU
Ultra 5 245K/ NPU
Ultra 5 245K/ iGPU
Ultra 5 245K/ CPU
GeekBench AI
Half Precision
Higher is Better
Ultra 9 285K/ NPU
Ultra 9 285K/ iGPU
Ultra 9 285K/ CPU
Ultra 5 245K/ NPU
Ultra 5 245K/ iGPU
Ultra 5 245K/ CPU
GeekBench AI
Quantized Score
Higher is Better
Ultra 9 285K/ NPU
Ultra 9 285K/ iGPU
Ultra 9 285K/ CPU
Ultra 5 245K/ NPU
Ultra 5 245K/ iGPU
Ultra 5 245K/ CPU
Результаты подтверждают, что NPU может использоваться как эффективный сопроцессор, потребляющий только небольшую часть мощности и занимающий малую часть всей площади чипа.
Производительность CUDIMM

Обратите внимание на обведенный красным чип в середине модуля памяти. В поколении Arrow Lake Intel вводит поддержку модулей памяти DDR5 CUDIMM, что расшифровывается как "Clocked Unbuffered Dual Inline Memory Module" – тактированный небуферизованный двусторонний модуль памяти. Эти DIMM-модули представляют улучшенный стандарт памяти DDR5 со встроенным тактовым генератором (Clock Driver, CKD) в виде чипа, который приделан непосредственно к модулю памяти. Теперь, вместо управления каждым чипом памяти по отдельности через достаточно длинное соединение, процессор может просто посылать сигнал на CKD, который управляет чипами памяти на коротких соединениях, что способствует большей целостности сигнала, особенно на высоких тактовых частотах.

Компания G.SKILL предоставила нам образец своего новейшего комплекта памяти F5-8800C4255H24GX2-TZ5CK из двух 24-гигабайтных модулей DDR5-8800 CUDIMM – очень впечатляющий. Мы будем использовать его в тестах для отдельного обзора масштабирования памяти на платформе Arrow Lake. А сейчас мы предлагаем вашему вниманию несколько экспресс-результатов.
Чтобы получить представление о влиянии более быстрой памяти на производительность, мы запустили несколько бенчмарков на конфигурации с процессором Ultra 9 285K и памятью G.SKILL DDR5-8200 CUDIMM. Обратите внимание, что эта конфигурация отлична от основной тестовой, поэтому эти результаты нельзя сопоставлять напрямую с результатами из других разделов, даже если это результаты одних и тех же тестов.
Machine Learning/AI
GPT2/Inference
Lower is Better
DDR5-8200 38-52-52-104
DDR5-7600 36-48-48-84
DDR5-6800 32-39-39-79
DDR5-6000 28-36-36-76
DDR5-6000 36-36-36-76
DDR5-5600 40-40-40-77
DDR5-4800 40-40-40-77
Rendering
Cinebench 2024 Multi
Multi-Threaded - Higher is Better
DDR5-8200 38-52-52-104
DDR5-7600 36-48-48-84
DDR5-6800 32-39-39-79
DDR5-6000 28-36-36-76
DDR5-6000 36-36-36-76
DDR5-5600 40-40-40-77
DDR5-4800 40-40-40-77
File Compression
WinRAR
Lower is Better
DDR5-8200 38-52-52-104
DDR5-7600 36-48-48-84
DDR5-6800 32-39-39-79
DDR5-6000 28-36-36-76
DDR5-6000 36-36-36-76
DDR5-5600 40-40-40-77
DDR5-4800 40-40-40-77
Y-Cruncher
Cinebench 2024 Multi
Pi,2.5 Billion Digits - Lower is Better
DDR5-8200 38-52-52-104
DDR5-7600 36-48-48-84
DDR5-6800 32-39-39-79
DDR5-6000 28-36-36-76
DDR5-6000 36-36-36-76
DDR5-5600 40-40-40-77
DDR5-4800 40-40-40-77
Температура под нагрузкой
Мы измеряли температуру процессора с кулером Noctua NH-D15. В качестве нагрузочного приложения мы взяли Blender, требовательное приложение для рендеринга, которое загружает все доступные ядра процессора и в то же время представляет собой реальный рабочий сценарий, а не синтетический стресс-тест, такой как Prime95. В качестве игровой нагрузки мы взяли Cyberpunk 2077, поскольку современный движок этой игры является многопоточным и по возможности старается распределить как можно больше задач по нескольким ядрам CPU. Хотя даже многопоточная игра не загружает все ядра CPU так интенсивно, как, например, рендеринг, так что здесь мы имеем некоторое пространство для энергосбережения.
Обратите внимание, что, если не указано иное, все процессоры тестировались с заводскими настройками лимитов мощности; именно поэтому некоторые процессоры Intel нагрелись на удивление слабо. Согласно документации Intel, эти процессоры могут превышать свои TDP в течение нескольких секунд (PL2), но в режиме длительной нагрузки соблюдается лимит мощности PL1, что значительно снижает температуру процессора. В обоих тестах измерялась установившаяся температура после не менее чем 10-минутной работы чипа под нагрузкой. Результаты нормированы относительно температуры 25°C, поэтому у некоторых процессоров значения рабочей температуры оказались выше точки троттлинга, так как температура в комнате была ниже 25°C.
Для недавних моделей процессоров Intel мы повысили температурный лимит в BIOS со 100/105°C до 115°C, чтобы иметь более надежный запас по термическому троттлингу.
Процессоры AMD Zen 4 и Zen 5 имеют «целевой лимит» 95°C: это значит, что процессор – в целях максимизации производительности – будет ускоряться насколько возможно, пока его температура не достигнет этой отметки. И, в отличие от Intel, на платформе AMD AM5 повысить этот 95-градусный лимит невозможно.
В тестах на нагрев все процессоры тестировались с воздушным охлаждением, для получения физически более наглядных результатов. В тестах на производительность использовалось жидкостное охлаждение (Arctic Cooling Liquid Freezer III), чтобы гарантированно удерживать температуру чипов ниже всех лимитов во избежание термического троттлинга.
CPU Temperature
Load
Blender, NH-D15 - Lower is Better
Core i5-13400F
Ryzen 9 7900
Ryzen 7 9700Х
Ryzen 9 5950X
Core Ultra 5 245K/Stock
Ryzen 7 7700
Ryzen 5 9600X
Core Ultra 5 245K/Power Limits Removed
Ryzen 9 9900X
Core i5-14600K
Core i5-13600K
Core Ultra 7 265K/Stock
Ryzen 7 5800X3D
Ryzen 9 9950X
Ryzen 7 7800X3D
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 7950X3D
Core i7-14700K
Core i7-13700K
Core i9-14900K
Core Ultra 9 285K/Stock
Ryzen 7 7700X
Ryzen 5 7600X
Core i9-12900K
Ryzen 9 7900X
Ryzen 9 7950X
Core Ultra 9 285K/Power Limits Removed
Core i9-13900K
CPU Temperature
Gaming
Cyberpunk 2077, NM-D15 - Lower is Better
Core i5-13400F
Core Ultra 5 245K/Stock
Ryzen 9 7900
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Ryzen 9 7950X3D
Core Ultra 7 265K/Power Limits Removed
Core i5-14600K
Core Ultra 9 285K/Stock
Core Ultra 9 285K/Power Limits Removed
Core i9-12900K
Ryzen 9 7950X
Ryzen 7 7700
Ryzen 7 9700X
Core i5-13600K
Ryzen 9 5950X
Ryzen 7 7700X
Ryzen 9 9900X
Ryzen 5 9600X
Core i7-14700K
Ryzen 9 7900X
Ryzen 7 5800X3D
Core i7-13700K
Ryzen 9 9950X
Ryzen 5 7600X
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Тактовые частоты
Иллюстрации ниже показывают, насколько стабильно процессор работает на своих тактовых частотах и как изменяется тактовая частота при изменении числа активных потоков. Специально для этого теста было написано приложение, имитирующее реальную нагрузку (это не стандартный нагрузочный тест типа Prime95). У современных процессоров фактические частоты зависят от типа нагрузки, поэтому здесь представлены три графика, показывающие тактовые частоты при выполнении классических математических операций с плавающей точкой (фиолетовый), кода SSE SIMD (зеленый) и современных векторных инструкций AVX (красный). В каждом из этих трех случаев решается одна и та же задача по одному и тому же алгоритму, просто при помощи разных наборов инструкций CPU.
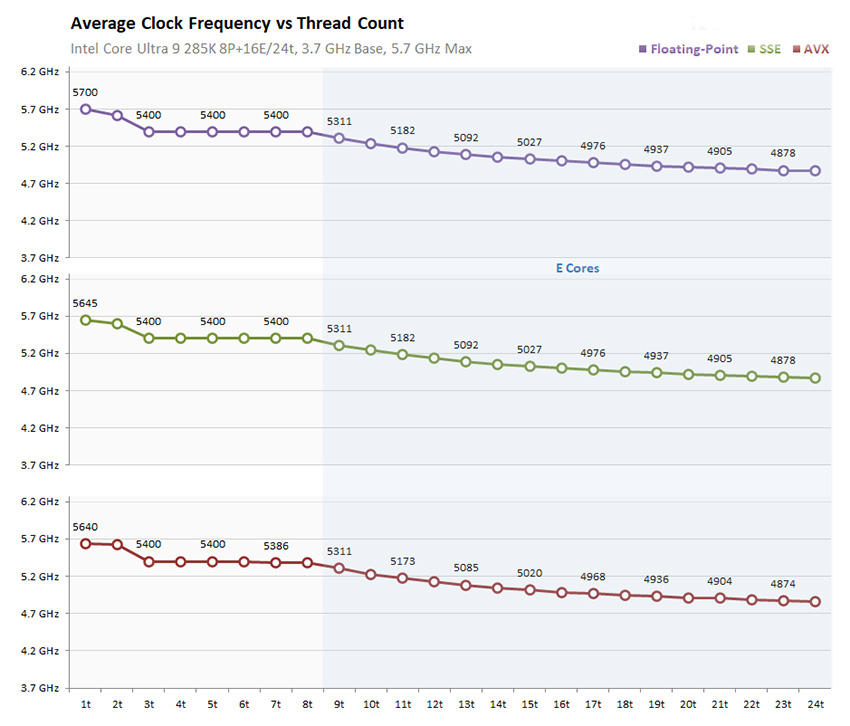
Заявленная максимальная частота 5.7 ГГц легко достигается, но на короткое время, в режиме легкой нагрузки и на двух лучших ядрах P. Как вы сами можете видеть, даже в режиме двух активных потоков (или одного высоконагруженного) кривая уже идет вниз.
Вид графиков с момента подключения ядер E (число потоков от 9 до 24) может вводить в заблуждение. Можно подумать, что ядра работают на всё более медленных частотах по мере возрастания нагрузки, но на самом деле это не так. График показывает среднюю частоту всех активных ядер P и подключающихся к ним одно за другим ядер E, которые все работают на постоянной частоте, более низкой, чем у ядер P, из-за чего общая кривая идет вниз.
Для более наглядной иллюстрации этого я вывел частоту последовательно задействуемых ядер E на отдельные графики, которые приведены ниже.
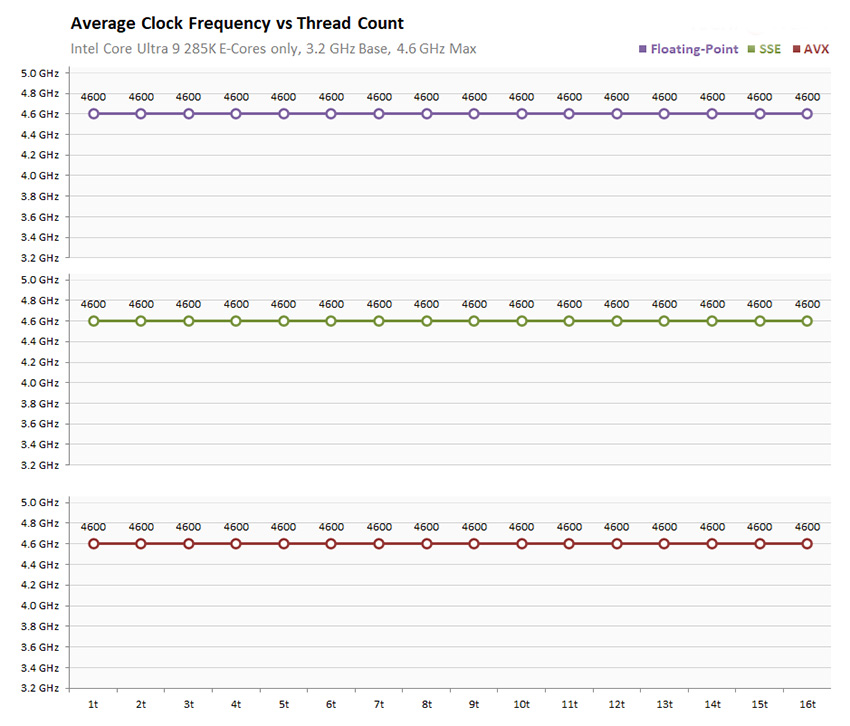
Ядра E работают на частоте 4.6 ГГц все время, если процессор не переходит (по какой-либо причине) в состояние троттлинга.
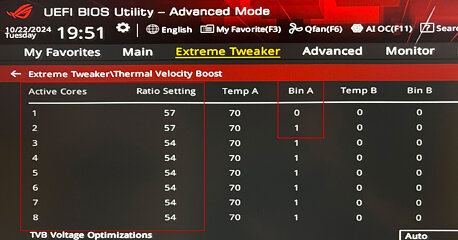
Приведенный выше скриншот BIOS подтверждает значения частот при масштабировании нагрузки по ядрам процессора:
- 1 активное ядро и температура менее 70°C – частота 5.7 ГГц;
- 1 активное ядро и температура более 70°C, или 2 активных ядра – частота 5.6 ГГц;
- 3 или более активных ядер – частота 5.4 ГГц.
Разгон процессора
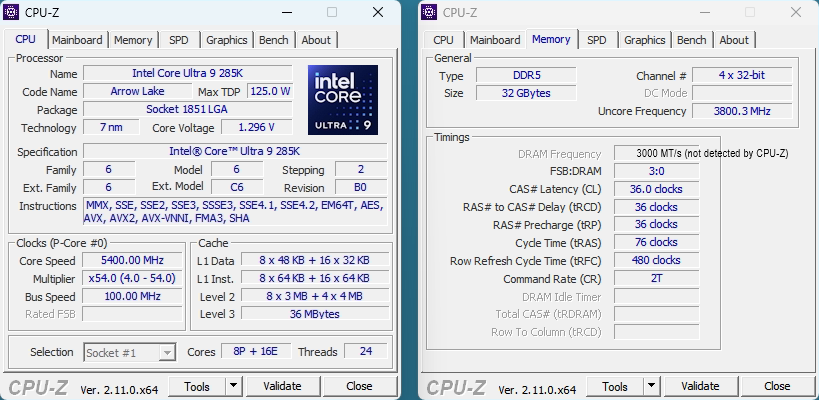
Благодаря разблокированному множителю разогнать процессор Intel Core Ultra 9 285K довольно легко. Раньше удерживать температуру при разгоне ниже точки троттлинга было большим искусством, но теперь это просто – процессоры особенно и не перегреваются. Кроме того, Intel повысила TjMax по умолчанию до 105°C, подняв температурный потолок на 5 градусов. И можно еще повысить этот лимит вручную до 115°C. У процессоров AMD AM5 аналогичный лимит составляет 95°C, и он не повышается.
Теперь вы можете устанавливать напряжения отдельно для ядер P и E, как и их разгонные частоты. Наконец, дополнительные настройки позволяют задавать тактовую частоту интерконнекта между плитками и др.
Раздел оверклокинга в данном обзоре имеет своей целью показать, каких результатов может достичь обычный пользователь без специальных знаний и не тратя десятки часов на тюнинг системы. Я выставил в настройках напряжения +150 mV для ядер обоих типов и стал повышать множитель частоты сначала только для ядер P.
Еще одно нововведение Arrow Lake – намного более точная настройка частоты, минимальный доступный шаг – 16 МГц. Я начал с шага 200 МГц, потом уменьшил его до 100 МГц и повышал частоту до тех пор, пока процессор не начал сбоить. На этой частоте (5.6 ГГц) я попробовал еще повысить напряжение, но не смог добиться стабильности без риска повреждения процессора из-за слишком высокого напряжения, поэтому остановился на частоте 5.5 ГГц, но на этой частоте процессор в конце концов слегка замедлился из-за троттлинга, так что в результате я пришел к 5.4 ГГц. Это значительно меньше, чем предлагают различные boost-режимы, где частота доходит до 5.7 ГГц, поэтому ручной разгон всех ядер имеет смысл только тогда, когда вы имеете дело с супермногопоточной нагрузкой. Важно отметить, что процессоры Intel поддерживают поядерный разгон, что позволяет подобрать оптимальный профиль разгона в полном соответствии с нагрузкой.
Затем я начал разгонять ядра E. Но сначала снизил частоту ядер P, чтобы гарантированно избежать каких-либо сбоев, которые могли бы помешать разгону ядер E.
На ядрах E я дошел до 5.0 ГГц – впечатляющий результат, но не вполне стабильный, поэтому я сбавил частоту на 100 МГц и в итоге остановился на 4.9 ГГц.
Общая производительность
В этом разделе мы сравниваем производительность тестируемых процессоров относительно друг друга. Диаграмма показывает уровень производительности каждого процессора в сравнении с другими. Относительные показатели производительности (в процентах) наглядно показывают, какой процессор быстрее или медленнее других в бенчмарках, и чем выше процентный показатель, тем лучше.
Relative Performance
Applications
Higher is Better
Ryzen 9 9950X
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Ryzen 9 7950X
Core i9-14900K
Core i9-13900K
Ryzen 9 7950X3D
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 9 9900X
Core i7-14700K
Ryzen 9 7900X
Core i7-13700K
Ryzen 9 7900
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Core i9-12900K
Ryzen 7 9700Х
Core i5-14600K
Ryzen 7 7700X
Core i5-13600K
Ryzen 9 5950X
Ryzen 7 7700
Core i7-12700K
Ryzen 7 7800X3D
Ryzen 5 9600X
Ryzen 9 5900X
Ryzen 5 7600X
Core i5-12600K
Ryzen 5 7600
Core i9-11900K
Ryzen 7 5800X
Ryzen 7 5800X3D
Ryzen 9 3900X
Core i5-13400F
Core i7-11700KF
Ryzen 7 5700X
Ryzen 7 5700G
Ryzen 5 8500G
Core i5-12400F
Ryzen 5 5600X
Core i5-11600K
Ryzen 7 3700X
Core i3-14100
Ryzen 5 3600
Core i3-12100F
Core i5-11400F
Ryzen 7 2700X
Ryzen 3 3300X
Relative Performance
Games 1280x720
RTX 4090, Ultra - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Ryzen 9 7950X3D
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 9 9950X
Ryzen 7 9700Х
Core Ultra 9 285K/Power Limits Removed
Ryzen 7 9700Х
Core Ultra 9 285K/Stock
Ryzen 5 9600X
Ryzen 9 7950X
Core i5-14600K
Ryzen 7 7700X
Ryzen 9 7900X
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 7 7700
Ryzen 5 7600X
Core i5-13600K
Core Ultra 5 245K/Power Limits Removed
Core i9-12900K
Ryzen 9 7900
Core Ultra 5 245K/Stock
Ryzen 7 5800X3D
Ryzen 5 7600
Core i7-12700K
Core i5-12600K
Ryzen 9 5950X
Ryzen 9 5900X
Core i9-11900K
Core i5-13400F
Core i7-11700KF
Ryzen 7 5800X
Core i5-12400F
Ryzen 5 5600X
Ryzen 7 5700X
Core i5-11600K
Ryzen 5 8500G
Core i3-14100
Ryzen 7 5700G
Core i3-12100F
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Relative Performance
Games 1920x1080
RTX 4090, Ultra - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Ryzen 9 7950X3D
Core i7-14700K
Core i7-13700K
Ryzen 9 9950X
Ryzen 7 9700Х
Ryzen 5 9600X
Core Ultra 9 285K/Power Limits Removed
Ryzen 9 9900X
Core Ultra 9 285K/Stock
Ryzen 9 7950X
Core i5-14600K
Ryzen 7 7700X
Ryzen 9 7900X
Ryzen 7 7700
Core Ultra 7 265K/Power Limits Removed
Core Ultra 7 265K/Stock
Ryzen 5 7600X
Core i5-13600K
Ryzen 9 7900
Core i9-12900K
Ryzen 7 5800X3D
Core Ultra 5 245K/Power Limits Removed
Core Ultra 5 245K/Stock
Ryzen 5 7600
Core i7-12700K
Ryzen 9 5950X
Core i5-12600K
Ryzen 9 5900X
Core i5-13400F
Core i9-11900K
Ryzen 7 5800X
Core i5-12400F
Core i7-11700KF
Ryzen 7 5700X
Ryzen 5 5600X
Core i5-11600K
Core i3-14100
Ryzen 5 8500G
Core i3-12100F
Ryzen 7 5700G
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Relative Performance
Games 2560x1440
RTX 4090, Ultra - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 9 7950X3D
Core i7-13700K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 7950X
Ryzen 5 9600X
Core i5-14600K
Ryzen 9 9950X
Ryzen 9 9900X
Core Ultra 7 265K/Stock
Ryzen 7 9700Х
Ryzen 9 7900Х
Ryzen 7 7700X
Ryzen 7 5800X3D
Core Ultra 5 245K/Power Limits Removed
Core i5-13600K
Core i9-12900K
Core Ultra 5 245K/Stock
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 7900
Core i7-12700K
Ryzen 5 7600
Ryzen 9 5950X
Core i5-12600K
Ryzen 9 5900X
Core i5-13400F
Core i9-11900K
Ryzen 7 5800X
Core i5-12400F
Ryzen 7 5700X
Ryzen 5 5600X
Core i7-11700KF
Core i5-11600K
Core i3-14100
Ryzen 5 8500G
Core i3-12100F
Ryzen 7 5700G
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Relative Performance
Games 3840x2160
RTX 4090, Ultra - Higher is Better
Ryzen 7 7800X3D
Ryzen 9 7950X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Core i7-13700K
Ryzen 9 9950X
Ryzen 9 7950X
Ryzen 9 9900X
Ryzen 5 9600X
Ryzen 9 7900X
Ryzen 7 5800X3D
Core Ultra 9 285K/Power Limits Removed
Ryzen 7 7700X
Core i5-14600K
Core Ultra 9 285K/Stock
Ryzen 7 9700Х
Core Ultra 7 265K/Power Limits Removed
Core i9-12900K
Ryzen 9 7900
Ryzen 7 7700
Core Ultra 7 265K/Stock
Core Ultra 5 245K/Power Limits Removed
Core i5-13600K
Core Ultra 5 245K/Stock
Ryzen 5 7600X
Core i7-12700K
Ryzen 5 7600
Ryzen 9 5950X
Ryzen 9 5900X
Core i5-12600K
Core i5-13400F
Ryzen 7 5800X
Ryzen 5 5600X
Ryzen 7 5700X
Core i5-12400F
Core i9-11900K
Core i3-14100
Core i7-11700KF
Core i5-11600K
Ryzen 9 3900X
Core i3-12100F
Ryzen 7 5700G
Ryzen 7 3700X
Ryzen 5 8500G
Ryzen 5 3600
Ryzen 3 3300X
Core i5-11400F
Ryzen 7 2700X
Relative Performance
Games 3840x2160
RTX 4090, Ultra - Higher is Better
Ryzen 7 7800X3D
Core i9-14900K
Core i9-13900K
Core i7-14700K
Ryzen 9 7950X3D
Core i7-13700K
Core Ultra 9 285K/Power Limits Removed
Core Ultra 9 285K/Stock
Core Ultra 7 265K/Power Limits Removed
Ryzen 9 7950X
Ryzen 5 9600X
Core i5-14600K
Ryzen 9 9950X
Ryzen 9 9900X
Core Ultra 7 265K/Stock
Ryzen 7 9700Х
Ryzen 9 7900Х
Ryzen 7 7700X
Ryzen 7 5800X3D
Core Ultra 5 245K/Power Limits Removed
Core i5-13600K
Core i9-12900K
Core Ultra 5 245K/Stock
Ryzen 7 7700
Ryzen 5 7600X
Ryzen 9 7900
Core i7-12700K
Ryzen 5 7600
Ryzen 9 5950X
Core i5-12600K
Ryzen 9 5900X
Core i5-13400F
Core i9-11900K
Ryzen 7 5800X
Core i5-12400F
Ryzen 7 5700X
Ryzen 5 5600X
Core i7-11700KF
Core i5-11600K
Core i3-14100
Ryzen 5 8500G
Core i3-12100F
Ryzen 7 5700G
Ryzen 9 3900X
Ryzen 7 3700X
Core i5-11400F
Ryzen 5 3600
Ryzen 3 3300X
Ryzen 7 2700X
Экономическая эффективность
Диаграмма ниже показывает, сколько вычислительной мощности вы получаете за каждый потраченный доллар при покупке того или иного процессора. Эти результаты охватывают весь диапазон наших неигровых бенчмарков, включая приложения. Они показывают выгодность каждого процессора, определяемую как отношение производительности процессора в таких сценариях, как редактирование видео, 3D-рендеринг или обработка данных, к его цене. Чем выше этот показатель, тем больший вычислительный ресурс вы получаете за свои деньги и тем лучшим решением будет этот процессор для современных требовательных приложений.
Performance per Dollar
Applications
Higher is Better
Core i5-12400F/$110
Core i3-12100F/$85
Ryzen 5 3600/$90
Core i5-12600K/$170
Ryzen 5 5600X/$135
Core i5-11400F/$105
Ryzen 7 5800X/$165
Core i7-12700K/$210
Ryzen 7 5700X/$160
Ryzen 5 8500G/$150
Core i5-13600K/$225
Core i5-13400F/$170
Core i3-14100/$130
Ryzen 7 5700G/$165
Ryzen 7 3700X/$150
Core i7-13700K/$280
Ryzen 5 7600/$200
Ryzen 5 7600X/$210
Core i5-14600K/$260
Core i9-12900K/$280
Ryzen 5 9600X/$250
Ryzen 7 7700X/$275
Core i5-11600K/$175
Ryzen 7 7700/$280
Core Ultra 5 245K/Power Limits Removed/$310
Core i7-14700K/$355
Ryzen 9 5900X/$265
Core Ultra 5 245K/Stock/$310
Core Ultra 7 265K/Power Limits Removed/$395
Core Ultra 7 265K/Stock/$395
Core i7-11700KF/$230
Ryzen 7 9700Х/$330
Core i9-13900K/$415
Core i9-11900K/$250
Ryzen 3 3300X/$140
Core i9-14900K/$445
Ryzen 9 7900X/$400
Ryzen 9 7900/$370
Ryzen 9 9900X/$430
Ryzen 9 5950X/$345
Ryzen 9 7950X/$510
Ryzen 7 2700X/$185
Ryzen 7 7800X3D/$370
Ryzen 9 7950X3D/$550
Core Ultra 9 285K/Power Limits Removed/$590
Ryzen 9 9950X/$600
Core Ultra 9 285K/Stock/$590
Ryzen 7 5800X3D/$340
Ryzen 9 3900X/$375
Стоимость кадра
Следующая диаграмма показывает, во сколько примерно вам обойдется каждый отрисованный кадр, если принимать в расчет только цену процессора, без учета энергопотребления и стоимости остального «железа». Важно иметь перед глазами оба показателя: стоимость кадра и фактическую частоту кадров, которую вы при этом получаете. На более высоких разрешениях разница в FPS между процессорами становится меньше, поскольку лимитирующим фактором становится производительность GPU. Показатели FPS рассчитаны по значениям средней частоты кадров, которые были получены на указанном разрешении во всех игровых тестах, в том числе с рейтрейсингом.
Cost per Frame
1280x720
Lower is Better
Core i3-12100F/$85/126 FPS
Core i5-12400F/$110/145 FPS
Ryzen 5 3600/$90/114 FPS
Core i5-11400F/$105/115 FPS
Ryzen 5 5600X/$135/ 148 FPS
Core i3-14100/$130/135 FPS
Ryzen 7 5700X/$160/150 FPS
Ryzen 5 8500G/$150/139 FPS
Core i5-12600K/$170/157 FPS
Ryzen 7 5800X/$165/152 FPS
Ryzen 5 7600/$200/180 FPS
Ryzen 5 7600X/$210/185 FPS
Core i5-13400F/$170/147 FPS
Core i7-12700K/$210/171 FPS
Ryzen 7 3700X/$150/122 FPS
Core i5-11600K/$175/140 FPS
Core i5-13600K/$225/179 FPS
Ryzen 7 5700G/$165/129 FPS
Ryzen 3 3300X/$140/109 FPS
Ryzen 5 9600X/$250/192 FPS
Core i5-14600K/$260/186 FPS
Core i7-13700K/$280/196 FPS
Ryzen 7 7700X/$275/191 FPS
Ryzen 7 7700/$280/188 FPS
Core i7-11700KF/$230/148 FPS
Core i9-12900K/$280/178 FPS
Ryzen 9 5900X/$265/160 FPS
Core i9-11900K/$250/150 FPS
Ryzen 7 9700Х/$330/198 FPS
Ryzen 7 7800X3D/$370/218 FPS
Core Ultra 5 245K
/Power Limits Removed/$310/178 FPS
/Power Limits Removed/$310/178 FPS
Core Ultra 5 245K
/Stock/$310/177 FPS
/Stock/$310/177 FPS
Core i7-14700K/$355/198 FPS
Ryzen 7 5800X3D/$340/182 FPS
Ryzen 7 2700X/$185/ 91 FPS
Ryzen 9 7900/$370/181 FPS
Core i9-13900K/$415/202 FPS
Ryzen 9 7900X/$400/189 FPS
Core Ultra 7 265K
/Power Limits Removed/$395/186 FPS
/Power Limits Removed/$395/186 FPS
Core Ultra 7 265K/Stock/$395/185 FPS
Ryzen 9 5950X/$345/161 FPS
Core i9-14900K/$445/204 FPS
Ryzen 9 9900X/$430/195 FPS
Ryzen 9 7950X3D/$550/207 FPS
Ryzen 9 7950X/$510/190 FPS
Ryzen 9 3900X/$375/125 FPS
Ryzen 9 9950X/$600/199 FPS
Core Ultra 9 285K
/Power Limits Removed/$590/194 FPS
/Power Limits Removed/$590/194 FPS
Core Ultra 9 285K/Stock/$590/193 FPS
Cost per Frame
1920x1080
Lower is Better
Core i3-12100F/$85/126 FPS
Core i5-12400F/$110/143 FPS
Ryzen 5 3600/$90/113 FPS
Core i5-11400F/$105/115 FPS
Ryzen 5 5600X/$135/147 FPS
Core i3-14100/$130/133 FPS
Ryzen 7 5700X/$160/148 FPS
Ryzen 7 5800X/$165/150 FPS
Ryzen 5 8500G/$150/136 FPS
Core i5-12600K/$170/153 FPS
Core i5-13400F/$170/146 FPS
Ryzen 5 7600/$200/171 FPS
Ryzen 5 7600X/$210/173 FPS
Ryzen 7 3700X/$150/121 FPS
Core i5-11600K/$175/137 FPS
Core i7-12700K/$210/164 FPS
Ryzen 7 5700G/$165/129 FPS
Ryzen 3 3300X/$140/108 FPS
Core i5-13600K/$225/170 FPS
Ryzen 5 9600X/$250/178 FPS
Core i5-14600K/$260/173 FPS
Core i7-13700K/$280/181
Ryzen 7 7700X/$275/176 FPS
Core i7-11700KF/$230/144 FPS
Ryzen 7 7700/$280/175 FPS
Core i9-12900K/$280/169 FPS
Ryzen 9 5900X/$265/156 FPS
Core i9-11900K/$250/147 FPS
Ryzen 7 9700Х/$330/178 FPS
Core Ultra 5 245K
/Power Limits Removed/$310/168 FPS
/Power Limits Removed/$310/168 FPS
Core Ultra 5 245K/Stock/$310/167 FPS
Ryzen 7 7800X3D/$370/193 FPS
Core i7-14700K/$355/183 FPS
Ryzen 7 5800X3D/$340/172 FPS
Ryzen 7 2700X/$185/90 FPS
Ryzen 9 7900/$370/171 FPS
Ryzen 9 5950X/$345/158 FPS
Core i9-13900K/$415/185 FPS
Ryzen 9 7900Х/$400/175 FPS
Core Ultra 7 265K
/Power Limits Removed/$395/173 FPS
/Power Limits Removed/$395/173 FPS
Core Ultra 7 265K/Stock/$395/172 FPS
Core i9-14900K/$445/186 FPS
Ryzen 9 9900X/$430/178 FPS
Ryzen 9 7950X/$510/177 FPS
Ryzen 9 7950X3D/$550/186 FPS
Ryzen 9 3900X/$375/124 FPS
Ryzen 9 9950X/$600/180 FPS
Core Ultra 9 285K
/Power Limits Removed/$590/177 FPS
/Power Limits Removed/$590/177 FPS
Core Ultra 9 285K/Stock/$590/176 FPS
Cost per Frame
2560x1440
Lower is Better
Core i3-12100F/$85/120 FPS
Ryzen 5 3600/$90/111 FPS
Core i5-12400F/$110/131 FPS
Core i5-11400F/$105/111 FPS
Ryzen 5 5600X/$135/ 134 FPS
Core i3-14100/$130/125 FPS
Ryzen 5 8500G/$150/126 FPS
Ryzen 7 5700X/$160/134 FPS
Ryzen 7 5800X/$165/135 FPS
Core i5-12600K/$170/138 FPS
Core i5-13400F/$170/134 FPS
Ryzen 7 3700X/$150/117 FPS
Ryzen 3 3300X/$140/106 FPS
Ryzen 7 5700G/$165/121 FPS
Core i5-11600K/$175/128 FPS
Ryzen 5 7600/$200/144 FPS
Ryzen 5 7600X/$210/146 FPS
Core i7-12700K/$210/144 FPS
Core i5-13600K/$225/147 FPS
Ryzen 5 9600X/$250/149 FPS
Core i7-11700KF/$230/132 FPS
Core i5-14600K/$260/149 FPS
Core i7-13700K/$280/152 FPS
Ryzen 7 7700X/$275/148 FPS
Core i9-11900K/$250/133 FPS
Ryzen 9 5900X/$265/139 FPS
Core i9-12900K/$280/147 FPS
Ryzen 7 7700/$280/147 FPS
Ryzen 7 2700X/$185/ 90 FPS
Core Ultra 5 245K
/Power Limits Removed/$310/147 FPS
/Power Limits Removed/$310/147 FPS
Core Ultra 5 245K/Stock/$310/147 FPS
Ryzen 7 9700Х/$330/148 FPS
Ryzen 7 5800X3D/$340/148 FPS
Core i7-14700K/$355/153 FPS
Ryzen 7 7800X3D/$370/157 FPS
Ryzen 9 5950X/$345/140 FPS
Ryzen 9 7900/$370/146 FPS
Core Ultra 7 265K
/Power Limits Removed/$395/150 FPS
/Power Limits Removed/$395/150 FPS
Core Ultra 7 265K/Stock/$395/149 FPS
Core i9-13900K/$415/154 FPS
Ryzen 9 7900X/$400/148 FPS
Core i9-14900K/$445/155 FPS
Ryzen 9 9900X/$430/148 FPS
Ryzen 9 3900X/$375/120 FPS
Ryzen 9 7950X/$510/149 FPS
Ryzen 9 7950X3D/$550/153 FPS
Core Ultra 9 285K
/Power Limits Removed/$590/151 FPS
/Power Limits Removed/$590/151 FPS
Core Ultra 9 285K/Stock/$590/151 FPS
Ryzen 9 9950X/$600/149 FPS
Cost per Frame
3840x2160
Lower is Better
Core i3-12100F/$85/88 FPS
Ryzen 5 3600/$90/87 FPS
Core i5-12400F/$110/93 FPS
Core i5-11400F/$105/85 FPS
Core i3-14100/$130/91 FPS
Ryzen 5 5600X/$135/93 FPS
Ryzen 3 3300X/$140/85 FPS
Ryzen 5 8500G/$150/88 FPS
Ryzen 7 3700X/$150/88 FPS
Ryzen 7 5700X/$160/93 FPS
Ryzen 7 5800X/$165/93 FPS
Core i5-12600K/$170/95 FPS
Core i5-13400F/$170/94 FPS
Ryzen 7 5700G/$165/88 FPS
Core i5-11600K/$175/90 FPS
Ryzen 5 7600/$200/97 FPS
Core i7-12700K/$210/98 FPS
Ryzen 5 7600X/$210/97 FPS
Core i5-13600K/$225/98 FPS
Ryzen 7 2700X/$185/78 FPS
Core i7-11700KF/$230/91 FPS
Ryzen 5 9600X/$250/99 FPS
Core i5-14600K/$260/99 FPS
Core i9-11900K/$250/92 FPS
Ryzen 9 5900X/$265/95 FPS
Ryzen 7 7700X/$275/99 FPS
Core i7-13700K/$280/99 FPS
Core i9-12900K/$280/98 FPS
Ryzen 7 7700/$280/98 FPS
Core Ultra 5 245K
/Power Limits Removed/$310/98 FPS
/Power Limits Removed/$310/98 FPS
Core Ultra 5 245K/Stock/$310/98 FPS
Ryzen 7 9700Х/$330/98 FPS
Ryzen 7 5800X3D/$340/99 FPS
Core i7-14700K/$355/100 FPS
Ryzen 9 5950X/$345/96 FPS
Ryzen 7 7800X3D/$370/101 FPS
Ryzen 9 7900/$370/98FPS
Core Ultra 7 265K
/Power Limits Removed/$395/99 FPS
/Power Limits Removed/$395/99 FPS
Core Ultra 7 265K/Stock/$395/98 FPS
Ryzen 9 7900Х/$400/99 FPS
Core i9-13900K/$415/100 FPS
Ryzen 9 3900X/$375/89 FPS
Ryzen 9 9900X/$430/99 FPS
Core i9-14900K/$445/100 FPS
Ryzen 9 7950X/$510/99 FPS
Ryzen 9 7950X3D/$550/101 FPS
Core Ultra 9 285K
/Power Limits Removed/$590/99 FPS
/Power Limits Removed/$590/99 FPS
Core Ultra 9 285K/Stock/$590/99 FPS
Ryzen 9 9950X /$600/99 FPS
Сравнение производительности процессоров
Intel Core Ultra 9 285K vs. Core i9-14900K
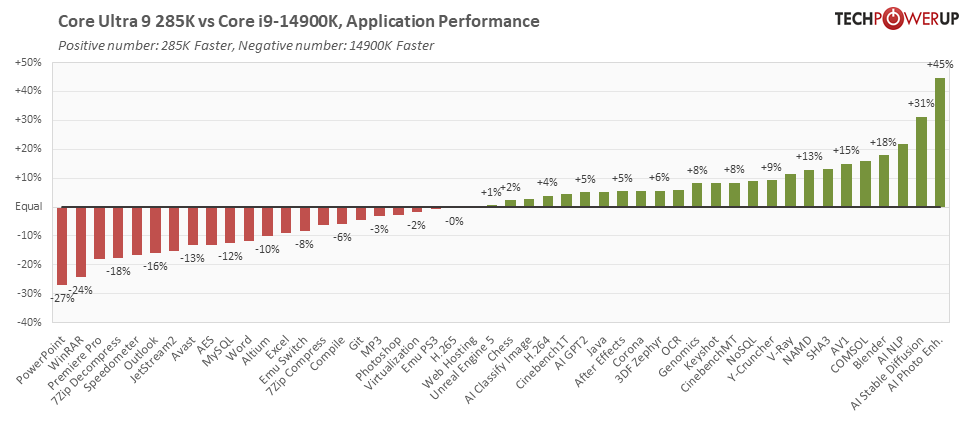
Intel Core Ultra 9 285K vs. Ryzen 9 9950X
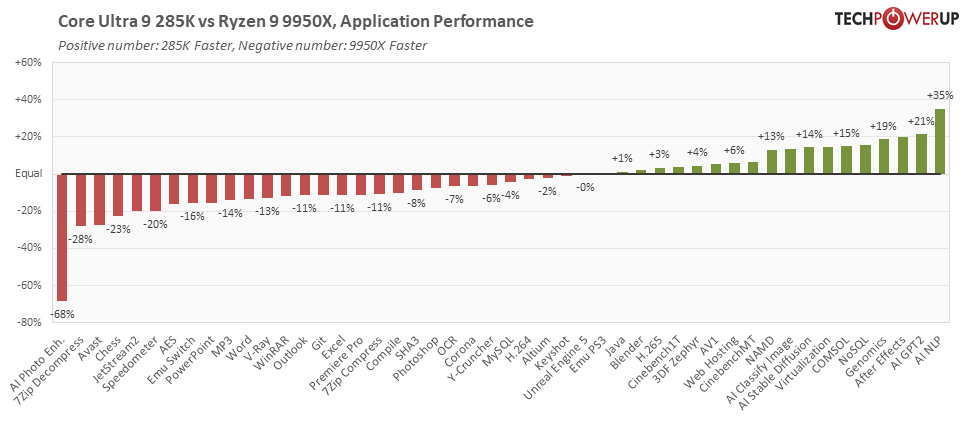
Intel Core Ultra 9 285K vs. Ryzen 9 7950X3D
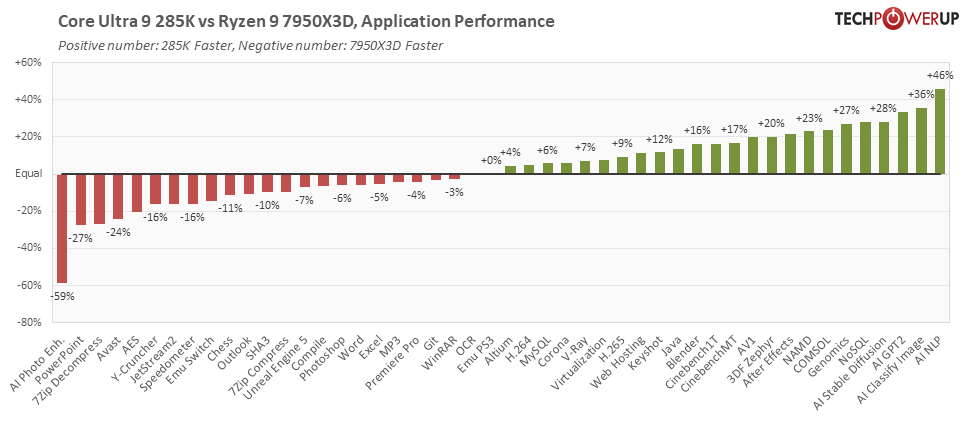
Заключение
Достоинства
- Отличная производительность в высоконагруженных многопоточных приложениях.
- Хорошая энергетическая эффективность.
- Рабочую температуру процессора поддерживать легко.
- Подключенный SSD с PCIe Gen 5 не забирает ресурс пропускной способности у дискретной видеокарты.
- Полная поддержка разгона.
- Хорошая поддержка памяти, включая скорости свыше DDR5-8000.
- Наличие встроенной графики.
- Производительность встроенной графики вдвое выше, чем у Raptor Lake.
- Поддержка Thunderbolt 4 и 5, Wi-Fi 6E и 7.
- Встроенный NPU.
- Техпроцесс 3 нм.
Недостатки
- Игровая производительность ниже, чем ожидалось (в играх медленнее Raptor Lake).
- Некоторые игры и приложения на данный момент вообще работают довольно плохо.
- Нужна новая материнская плата с сокетом LGA1851.
- Нет опции поддержки памяти DDR4.
- Нет поддержки AVX-512.
Технологии и позиция на рынке
С серией Core Ultra 200 компания Intel запускает новый бренд процессорной архитектуры для своей десктопной линейки. Долгое время не-мобильные процессоры Intel имели традиционный монолитный (однокристальный) дизайн, но чипы Arrow Lake изменили это положение дел. Чип нового поколения состоит из четырех независимо изготавливаемых кристаллов – "плиток" – которые вместе образуют единый процессор. Это напоминает подход, применяемый в серии AMD Ryzen, но здесь все намного более сложно, поскольку плитки совершенно разные, каждая со своим функционалом, тогда как у AMD – просто комбинация кристалла I/O и вычислительных плиток. AMD соединяет плитки посредством Infinity Fabric, в то время как Intel опирается на свою технологию Foveros и сажает плитки на еще один кремниевый компонент под названием "интерпозер", который обеспечивает намного более быстрое и энергетически эффективное взаимодействие составных частей процессора.
Еще одно заметное отличие новой микроархитектуры Intel – отсутствие в ядрах компонентов, отвечающих за многопоточность (Hyper-Threading). Ранее эта технология широко использовалась для удвоения числа потоков процессора, но со временем оказалось, что она является одним из основных источников проблем с безопасностью данных. Кроме того, некоторые приложения лучше работают без HT, а на реализацию HT уходит часть площади кристалла. Наконец, что тоже очень важно, ядра E также были сущетсвенно модернизированы и получили доступ к общему кэшу L3 вместе со значительным увеличением IPC.
Помимо всего прочего, номенклатура процессоров тоже изменилась, чтобы обозначить новый этап эволюции архитектуры Intel. Процессор, которому посвящен данный обзор, называется не Core i9-15900K, а Core Ultra 9 285K. Я не знаю, имеет ли это какое-нибудь значение для среднестатистического пользователя, который привык считать, что "чем больше номер модели, тем лучше", а энтузиасты просто перейдут на новую номенклатуру, не оценивая по ней фактические чипы. На сегодняшний день в сети есть обзоры флагманского процессора новой серии, Core Ultra 9 285K (например – этот обзор), а также свежих аналогов топовых чипов Core i7 – Core Ultra 7 265K, и Core i5 – Core Ultra 5 245K.
Производительность в приложениях
Intel хвалится своей новой архитектурой Lion Cove уже многие месяцы, и вот, наконец, у нас есть собственные результаты. В целом производительность в приложениях у Core Ultra 9 285K на 1.2% выше, чем у Core i9-14900K – не густо. Флагманский чип AMD, Ryzen 9 9950X, по-прежнему занимает первое место с небольшим отрывом в 3.4%. Если мы посмотрим на отдельные бенчмарки, то увидим, что Arrow Lake не побеждает во многих номинациях. В ряде тестов новый процессор вообще далек от конкуренции за первые места. Я точно не знаю, с чем это связано, но первое, что приходит в голову – возможный дисбаланс в планировке потоков по ядрам E или слишком частые переключения между ядрами. Интересно, что это чаще происходит при легкой или средней нагрузке. Тяжелые нагрузки идут отлично и раскрывают всю мощь новых ядер P. Я также впечатлен результатами запуска ИИ-тестов только на CPU (без участия NPU): просто поразительно, насколько хорошо эта новая архитектура справляется с данным видом нагрузки, даже без Hyper-Threading. Повышение лимита мощности на Arrow Lake не приводит к существенной разнице в результатах – у этих процессоров лимиты мощности не ограничивают производительность.
Память DDR5 и CUDIMM
Держа в уме результаты тестирования производительности, я хотел бы подчеркнуть, что эти тесты проводились с относительно медленной памятью DDR5-6000 CL36, которая была выбрана в целях гарантированного обеспечения равных условий для всех платформ AMD и Intel – это общий знаменатель, с которым все системы работают нормально. Память DDR5 становится все более обкатанной, так что мы собираемся заново протестировать все наши 40 с лишним образцов процессоров с более быстрыми опциями памяти. Конкретно для Arrow Lake вам нужно учесть, что эта платформа предлагает отличную поддержку памяти со скоростями за 8000 MT/с, причем без каких-либо дополнительных настроек делителей. На платформе AMD при скоростях свыше 6400 MT/с вам придется работать с меньшим соотношением частот контроллера и памяти, что потребует значительного повышения частоты памяти для компенсации выросшей задержки. На Arrow Lake повышать делитель нужно только тогда, когда скорость памяти выше 8800 MT/с, что говорит о намного лучшей оптимизации масштабирования скоростей памяти. О масштабировании памяти скоро выйдет отдельная статья, но и в этом обзоре приводится несколько результатов быстрых тестов, позволяющий получить представления о том, на что можно рассчитывать. Результаты показывают, что 6000 CL36 не так чтобы сильно медленнее 6000 CL30, но разогнанная до максимальных доступных на сегодняшний день скоростей память дает неплохое преимущество.
Игровая производительность
Если производительность в приложениях интересует вас только постольку поскольку, смотрите результаты игрового тестирования. В зависимости от конкретной игры чип Arrow Lake может занимать как одну из верхних строчек чарта (Spider-Man), так и плестись в хвосте группы (Elden Ring). Это довольно неожиданно: мы ожидали, что новые ядра P будут разделываться с играми на лету, тем более при отсутствии технологии Hyper-Threading, которая часто слегка замедляла игры. Я не знаю, с чем связан этот разброс игровой производительности, но надеюсь, что это решаемая проблема и Intel решит ее в ближайшее время. По сравнению с представителем последнего поколения Raptor Lake – 14900K, новый чип Ultra 9 285K примерно на 5% медленнее на разрешении 1080p и на 1.5% – на 4K. Процессоры AMD Zen 5 предлагают примерно такую же производительность, но у AMD в рукаве есть козырь в виде чипов X3D. Процессор 7800X3D остается бесспорно лучшим игровым процессором в мире, и очень скоро выйдет 9800X3D, который – если только AMD не пресытится своим лидерством – будет следующим чемпионом среди игровых процессоров. Однако заметьте, что разница в частоте кадров в 5% – не так уж велика. На уровне 100 FPS плюс-минус 5 FPS практического значения не имеют, и вы не заметите никакой разницы между этими процессорами. Все эти чипы отлично подходят для гейминга, и, вероятно, выбирать между ними вы будете исходя из цены. Конкурентоспособными предложениями являются Ryzen 9600X, 7700X, 14600K и 13700K – все они стоят значительно дешевле 7800X3D, и уж конечно AMD назначит кругленькую сумму за 9800X3D.
Встроенная графика
В серии Core Ultra 200 Intel представляет модернизированный iGPU, который базируется на более современной архитектуре. И я рад сообщить, что по производительности он примерно вдвое (!) превосходит встроенный графический компонент Raptor Lake – отличная работа! Хотя вы, конечно, не сможете играть на этой встроенной графике в игры класса AAA, легкий гейминг пойдет на ней вообще без каких-либо проблем. Вы также получаете ускоренное воспроизведение видео с широкой поддержкой кодеков и технологией Quick Sync для кодирования медиаконтента на самом высоком уровне. И, конечно, все стандартные продуктивные приложения, Internet-браузеры, Office и Photoshop будут работать вполне гладко.
Энергопотребление
Одним из основных целевых показателей для новой архитектуры Intel было снижение энергопотребления, и я могу подтвердить, что эта цель Intel достигнута. В среднем, по результатам тестирования 49 приложений, энергопотребление чипа 285K составило 132 Вт, тогда как у 14900K – 180 Вт; неплохо, 30%-ное снижение. Мощность, потребляемая во время гейминга, тоже снизилась – примерно на 50 Вт: до 94 Вт против 149 Вт у предшественника. В сравнении с чипами AMD Zen 5 профили мощности сопоставимы, я бы сказал – "достаточно близкие". Конкретно для гейминга лучшим решением с точки зрения энергетической эффективности является чип Ryzen 7 7800X3D: он потребляет примерно вдвое меньше ватт, чем 285K, и при этом предлагает больше FPS. Учтите также, что Intel использует техпроцесс 3 нм, тогда как AMD – чуть менее эффективный 4 нм, оба от TSMC. В свой новый набор тестов Test Suite 2024 мы добавили измерение энергопотребления системы в простое, и вот здесь серия Arrow Lake действительно впечатляет, как, впрочем, и предыдущие архитектуры Intel. В сравнении с AMD разница в пользу Intel составляет около 25 Вт, что существенно для тех пользователей, у которых компьютер включен по многу часов каждый день.
Требования к охлаждению
Раньше охлаждение высококлассных процессоров Intel было сложной технической задачей – теперь это просто. Благодаря повышению энергетической эффективности процессоров тепловой выход снизился, к тому же тепловые потоки теперь не так сильно сконцентрированы, поскольку ядра P рассредоточены на большей площади. Вы сможете легко охладить не разогнанный чип 285K, используя типовой воздушный кулер для высокопроизводительных процессоров. Решение Intel повысить температурный лимит до 105°C дает большее пространство для маневра и при этом гарантирует безотказную работу процессора в режиме 24/7. У AMD температурный лимит – 95°C, плюс более толстый IHS, поэтому поддерживать рабочую температуру их процессоров сложнее, несмотря на немного меньший тепловой выход. Если вы планируете серьезный оверклокинг, особенно с повышением напряжения, то вам понадобится более продвинутый кулер, например, водяной типа AIO.
Разгон
Как и в предыдущих поколениях, в серии Arrow Lake Intel использует суффикс "K" для обозначения разгоняемых процессоров – стоит ли этим заниматься? Например, AMD предлагает разблокированные множители во всех своих моделях. Хотя технически оверклокинг не представляет особых сложностей, и сегодня Intel даже предлагает для этого несколько новых настроек, в конечном счете разница в скорости получается небольшая. Я уверен, что в ближайшие недели мы узнаем больше о способах повышения производительности. Здесь интересны аспекты интерконнектов D2D (die-to-die) и NGU (Next Generation Uncore), Ring и, конечно, всё, что имеет отношение к планировке потоков и производительности памяти. "Классическая" накрутка множителя CPU не приводит к высоким результатам, потому что процессор и так работает довольно близко к своим максимальным лимитам, но индивидуальный разгон ядер может давать лучший по сравнению с заводской конфигурацией результат во всех сценариях.
Платформа
Arrow Lake – это не только новые процессоры, но и новая платформа с новым чипсетом, новым сокетом и новыми материнскими платами. Что мне понравилось: теперь наконец-то можно использовать SSD с PCIe Gen 5 не в ущерб графическому интерфейсу – на предыдущих платформах при установке подключаемого к CPU накопителя M.2 SSD для дискретной графики оставалось восемь линий PCIe. И, конечно, вы получаете все суперсовременные фишки в части USB, Wi-Fi, Thunderbolt и т.д. С другой стороны, если раньше переход на новую платформу Intel происходил абсолютно гладко, то в этот раз некоторые вещи выглядят слегка недоработанными. За последние две недели мы имели дело с пятью различными версиями BIOS, к которым в ближайшее время добавятся и другие. Лично я столкнулся со странной нестабильностью памяти: слоты 1 и 3 едва справлялись со скоростями DDR5-5600. Как только те же модули памяти были установлены в рекомендуемые слоты 2 и 4, стали доступны скорости за 8000 MT/с, при тех же самых настройках BIOS. Запустить четыре обычных модуля памяти с высокими скоростями крайне сложно: с четырьмя DIMM вы остановитесь где-то на уровне до 6000 MT/с; вероятно, модули CUDIMM изменят эту ситуацию. Введено много новых опций BIOS, но пока отсутствуют внятные описания, как ими пользоваться в настройках UEFI. При одновременном использовании Windows 24H2 и Arrow Lake производительность будет отвратительной – у нас частота кадров в играх была вдвое меньше по сравнению с версией 23H2. Один из вариантов решения этой проблемы – выключить Thread Director или деактивировать профиль мощности "Balanced", так что мы решили пока использовать 23H2. Наконец, есть некоторые проблемы с драйверами плюс синие экраны при одновременном нахождении в активном режиме дискретной и встроенной графики.
Мне все это напомнило историю с 1-м поколением AMD Ryzen, но я уверен, что Intel решит все эти проблемы, как в свое время AMD. Если поколение Raptor Lake поддерживало обе опции памяти – DDR4 и DDR5, то Arrow Lake сосредоточено исключительно на DDR5, что, на мой взгляд, целесообразно, так как более новая память уже достаточно подешевела. Использование на этой платформе более быстрой памяти определенно улучшает производительность, и в этом преимущество Intel перед AMD, поскольку с Intel вы сможете запускать более быструю память (если готовы за нее заплатить).
Мы уже давно наблюдаем исключительно долгую загрузку систем на процессорах AMD AM5, и, похоже, что-то мешает AMD решить эту проблему до конца. На Core Ultra 200 система загружается примерно так же, как и на процессорах предыдущих поколений Intel – можно сказать, "быстро", независимо от режима загрузки или перезагрузки.
Нейропроцессор (NPU)
Новые процессоры Intel Arrow Lake оснащены NPU, который ускоряет операции ИИ на локальном ПК. В настоящее время это редкий сценарий – большинство ИИ-приложений являются облачными или используют ресурсы CPU/GPU. Но в будущем, я уверен, все больше и больше разработчиков будут портировать свои алгоритмы на NPU, что будет давать преимущество таким системам, в основном в части энергетической эффективности. Просто на уровне вычислительной мощности GPU и CPU еще долго будут ведущим звеном, и к настоящему моменту экосистема NPU-API не сформирована. Сейчас наличие NPU в десктопном процессоре не дает ощутимых результатов, но в будущем, вероятно, ситуация изменится.
Ценовая категория и альтернативные предложения
Intel выпускает чип Core Ultra 9 285K по цене в точности по такой же, по какой поступил в продажу флагман предыдущего поколения. И это однозначно не впечатляет. В настоящий момент, с учетом всех заковырок платформы Arrow Lake, этот процессор сложно рекомендовать, тем более при отсутствии выраженного преимущества в цене. Без сомнения, некоторые приложения идут на Core Ultra 200 очень хорошо, и если вы с ними работаете, то можете рассмотреть этот чип как возможный вариант, но для геймеров на рынке имеется много хороших альтернатив Core Ultra 9 285K, которые не только дешевле, но и предлагают (слегка) лучшую производительность. Если вы хотите играть именно на Arrow Lake, рассмотрите вариант Core Ultra 7 265K, который на 200 долларов дешевле и имеет всего на четыре ядра (E) меньше и чуть более низкие тактовые частоты. В части производительности (и в играх, и в приложениях) вы потеряете единицы процентов, что совершенно не существенно на фоне более чем полуторакратной разницы в цене. Процессоры AMD Zen 5 продавались не очень хорошо, потому что не имеют значительных преимуществ перед Zen 4, и AMD просто объявила на них скидку. Я полагаю, что та же участь ждет и Core Ultra 200. Апгрейд сегодня не выглядит привлекательным решением, тем более с такими безумными ценами на материнские платы. Большинству пользователей я настоятельно рекомендую подождать несколько месяцев, пока Intel оптимизирует эту платформу.
Ближайшие релизы
AMD уже объявила, что 7 ноября выходит новый Ryzen 9800X3D, который, по всей вероятности, установит новый рекорд игровой производительности и будет стоить недешево. В новом 2025 году Intel должна анонсировать процессоры Arrow Lake не-K, с более низкими TDP и более бюджетные. Я думаю, что к тому моменту платформа уже будет достаточно оптимизирована, а Microsoft заткнет все дырки в Windows 11 24H2. Далее идут Zen 6 и Panther Lake, которые мы увидим не раньше конца 2025 года, так что пока ничего сказать про них не можем. Мы только надеемся, что в ближайшие месяцы новые платформы Arrow Lake и Zen 5 подешевеют, что привлечет к ним внимание пользователей.
Как я уже отметил, выпуск Arrow Lake очень напомнил мне выпуск Zen 1, первого поколения Ryzen. Здесь интересны скорее перспективы и возможности, поскольку эта серия закладывает новый концептуальный фундамент архитектуры для будущих поколений процессоров Intel. На мой взгляд, самыми перспективными аспектами Arrow Lake являются возможности масштабирования памяти DDR5 и отдельной загрузки ядер P и E. Эти вещи мы продолжим исследовать в ближайшее время.



Источник: www.techpowerup.com